 影刀RPA新手教程文本清洗与正则提取完全指南——手机号、邮箱、金额、日期提取实战本文作者林焱 | 转载请注明出处开篇案例从3000条用户留言里提取手机号去年帮一个教育机构做RPA需求很简单每天从后台导出用户留言提取里面的手机号自动加微信。我写好流程跑第一批3000条留言提取出2800个手机号。交给客户后客户说“怎么有800多个是空号”我仔细一看提取出来的手机号里有写成了138-1234-5678的有写成了138 1234 5678的还有写成了(021)13812345678的。更离谱的是有人把手机号写在了句子中间比如我的号码是13812345678请加我。正则写得不够严谨把座机号、快递单号也当成了手机号提取出来。这次教训让我明白文本清洗和正则提取表面简单实际坑很多。本文所有案例围绕用户留言信息提取与清洗这条真实业务线展开。模块一安装与准备工作文本处理和正则提取在影刀RPA里主要用Python代码指令实现。影刀自带的正则相关指令“匹配正则表达式”、“替换正则表达式”也能用但功能有限。当需要处理复杂逻辑时还是Python更顺手。确保你的环境里Python版本在3.6以上正则的某些新特性需要3.6。关于Python环境的安装配置home.linyan.cloud 上有详细的图文教程照着做10分钟搞定。新建流程命名为文本清洗与提取Demo。模块二元素定位从网页提取文本文本清洗的前提是先把文本从网页或软件里提取出来。XPath提取网页文本内容//div[classuser-comment]/text()这个XPath提取class为user-comment的div标签里的文本节点。注意XPath的text()只提取直接子文本节点不提取子标签里的文本。如果想提取div内所有文本包括子标签里的用string(//div[classuser-comment])CSS选择器提取文本在影刀里用获取元素属性指令选中元素后用以下方式获取文本# 在影刀的执行JavaScript指令里js_code return document.querySelector(.user-comment).innerText; 从Excel批量读取待处理的文本很多时候文本存在Excel里用影刀的读取Excel指令批量读取存到一个列表变量里再逐条处理。模块三变量与数据类型正则表达式的返回类型用Python的re模块做正则提取要搞清楚每个函数返回什么类型importre text我的手机号是13812345678备用号13987654321# re.search返回第一个匹配的Match对象没找到返回Nonematchre.search(r1[3-9]\d{9},text)ifmatch:print(match.group())# 13812345678字符串print(match.span())# (6, 17)元组起始和结束位置# re.findall返回所有匹配的字符串列表没找到返回空列表phonesre.findall(r1[3-9]\d{9},text)[video(video-UbANf05A-1782836906410)(type-csdn)(url-https://live.csdn.net/v/embed/525010)(image-https://v-blog.csdnimg.cn/asset/f4faa587144cb7070f19e8b36813806b/cover/Cover0.jpg)(title-店群矩阵自动化突破运营极限)]print(phones)# [13812345678, 13987654321]列表# re.finditer返回迭代器每个元素是一个Match对象适合大文本forminre.finditer(r1[3-9]\d{9},text):print(m.group(),m.start())# re.sub返回替换后的字符串字符串cleanedre.sub(r\s,,text)print(cleaned)# 我的手机号是13812345678备用号13987654321我当时踩过这个坑把re.search()的返回值直接当字符串用。当没找到匹配时re.search()返回None对None调用.group()会报AttributeError。正确写法matchre.search(pattern,text)phonematch.group()ifmatchelse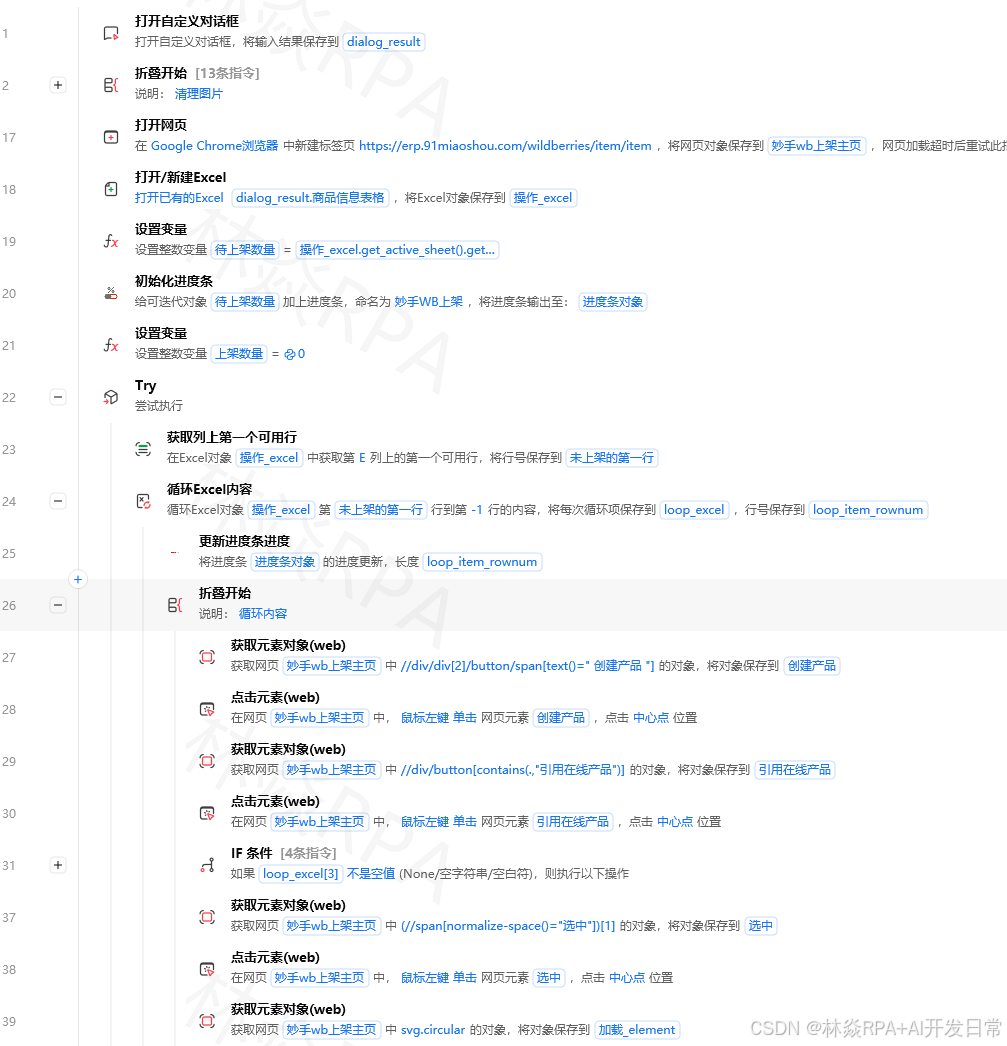模块四流程控制批量文本处理处理大量文本时用循环配合条件判断。场景从留言列表里提取手机号提取不到的单独记录importre comments[我的手机号是13812345678请加我,QQ号123456789不加微信,电话号码021-12345678,手机138-1234-5678谢谢,]patternr1[3-9]\d{9}results[]no_match[]fori,commentinenumerate(comments):# 先清洗去掉所有空格、横杠、括号cleanedre.sub(r[\s\-()],,comment)matchre.search(pattern,cleaned)ifmatch:results.append({index:i,comment:comment,phone:match.group()})else:no_match.append({index:i,comment:comment})print(f成功提取{len(results)}条未提取到{len(no_match)}条)在影刀里这个逻辑用循环指令遍历列表用如果/否则指令判断提取结果用赋值指令把结果存到新的列表变量里。模块五网页自动化结合文本提取很多时候文本不在本地文件里而在网页上需要先用网页自动化把文本抓下来再做清洗。完整流程抓取网页留言并提取手机号用启动浏览器指令打开后台页面用循环指令翻页直到没有下一页用获取元素文本指令提取每条留言的内容把提取到的文本存到一个列表变量用Python代码指令批量清洗和提取把结果写入Excel等待页面加载完成的技巧网页留言往往是异步加载的抓文本时要等内容出现。importtime# 在影刀的Python代码指令里# 配合影刀的等待元素出现指令使用# 如果内容加载慢可以主动等待defwait_text_appear(element_xpath,timeout10): 等待元素文本出现内容不为空 foriinrange(timeout):# 用影刀的获取元素文本指令获取文本# 这里用伪代码表示逻辑textget_element_text(element_xpath)iftextandtext.strip():returntext time.sleep(1)returnNone模块六数据处理——手机号提取手机号的规则1开头第二位是3-9后面9位数字共11位。但要注意用户填写时会有各种格式。严格手机号提取只匹配纯数字11位importredefextract_phone(text): 从文本中提取手机号 先清洗格式字符再做匹配 # 第一步去掉所有非数字字符看看是否有11位连续数字以1开头digits_onlyre.sub(r\D,,text)matchre.search(r1[3-9]\d{9},digits_only)ifmatch:returnmatch.group()return# 测试test_cases[13812345678,# 标准格式138-1234-5678,# 带横杠138 1234 5678,# 带空格(021)13812345678,# 带区号括号手机13812345678,# 带中文前缀1381234567,# 只有10位不是手机号23812345678,# 2开头不是手机号]forcaseintest_cases:resultextract_phone(case)print(f输入{case}- 提取结果{resultifresultelse未提取到})排除座机号座机号以0开头或者是400/800开头。如果文本里同时有手机号和座机号要区分开importredefextract_phone_only(text): 只提取手机号排除座机号 # 去掉所有非数字digits_onlyre.sub(r\D,,text)# 如果以0开头是座机号跳过ifdigits_only.startswith(0):return# 如果以400或800开头是客服号跳过ifdigits_only.startswith(400)ordigits_only.startswith(800):return# 匹配手机号matchre.search(r1[3-9]\d{9},digits_only)returnmatch.group()ifmatchelse模块七数据处理——邮箱提取邮箱的正则表达式比手机号复杂因为邮箱格式多样。标准邮箱提取importredefextract_email(text): 从文本中提取邮箱地址 patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}matchre.search(pattern,text)returnmatch.group()ifmatchelse# 测试emails[我的邮箱是zhangsanexample.com,联系我lisi123163.com,work.emailtaggmail.com,# 号在邮箱里是合法的adminsub.domain.co.jp,# 多层级域名]foreinemails:print(extract_email(e))坑点邮箱后面的标点符号用户写邮箱时经常在后面加标点符号我的邮箱是zhangsanexample.com。请发邮件。 联系我lisi123163.com谢谢如果直接匹配会把句号或逗号也匹配进去。解决方法在正则里排除结尾的标点符号或者在匹配后做清洗defextract_email_clean(text):patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}matchre.search(pattern,text)ifnotmatch:returnemailmatch.group()# 去掉结尾的可能附着的标点符号emailemail.rstrip(.,;:!。)returnemail我当时踩过这个坑提取出来的邮箱带了一个中文句号发邮件时一直报邮箱地址无效排查了很久才发现问题。模块八数据处理——金额提取金额提取的难点格式多样有100元、“100”、“100.00”、一百元等。常见金额格式提取importredefextract_amount(text): 从文本中提取金额数字部分 支持100元、100、100.00、100.00元、1,000元 # 匹配各种金额格式patterns[r?\s*(\d(?:,\d{3})*(?:\.\d{2})?)\s*元?,# 100、100元、100.00元r(\d(?:,\d{3})*(?:\.\d{2})?)\s*元,# 100元r金额[:]\s*(\d(?:,\d{3})*(?:\.\d{2})?),# 金额100r合计[:]\s*(\d(?:,\d{3})*(?:\.\d{2})?),# 合计100]forpatterninpatterns:matchre.search(pattern,text)ifmatch:amount_strmatch.group(1).replace(,,)returnfloat(amount_str)return0.0# 测试test_cases[总价100元,199.00,金额1,299.00,合计 299元,没有金额信息,]forcaseintest_cases:amountextract_amount(case)print(f输入{case}- 金额{amount})中文金额转数字进阶如果遇到了一百元、贰佰叁拾元这种中文金额需要专门处理defchinese_amount_to_number(text): 把中文金额转成数字简化版支持佰以内的金额 cn_num{一:1,二:2,三:3,四:4,五:5,六:6,七:7,八:8,九:9,十:10}# 匹配X百Y十Z格式patternr([一二三四五六七八九])?百?([一二三四五六七八九])?十?([一二三四五六七八九])?元# 这个正则比较复杂实际项目中建议用现成的库pip install cn2antry:importcn2an 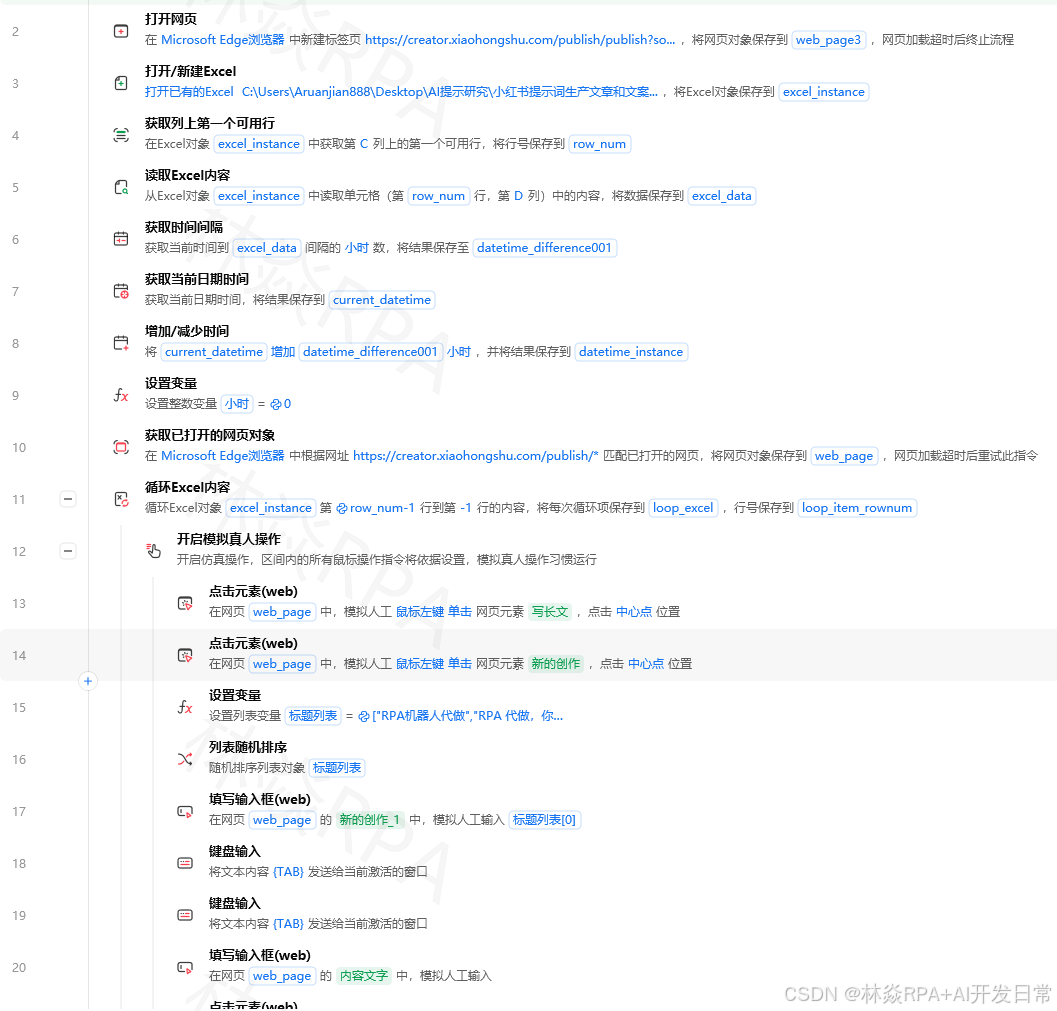# 提取中文金额字符串matchre.search(r[\u4e00-\u9fff]元,text)ifmatch:cn_amountmatch.group().rstrip(元)returncn2an.cn2an(cn_amount)exceptImportError:print(请先安装cn2an库pip install cn2an)return0模块九数据处理——日期提取日期格式比金额还多2024-06-01、2024/06/01、06/01/2024、2024年6月1日……通用日期提取importrefromdatetimeimportdatetimedefextract_date(text): 从文本中提取日期转成统一格式YYYY-MM-DD # 定义多种日期格式的正则patterns[(r(\d{4})[年\-/](\d{1,2})[月\-/](\d{1,2}),%Y%m%d),# 2024-06-01 或 2024年06月01日(r(\d{1,2})[月\-/](\d{1,2})[日\-/](\d{4})?,%m%d%Y),# 06/01/2024(r(\d{4})年(\d{1,2})月(\d{1,2})日,%Y%m%d),# 2024年6月1日]forpattern,fmtinpatterns:matchre.search(pattern,text)ifmatch:groupsmatch.groups()# 根据格式组装iffmt%Y%m%d:year,month,daygroupstry:dtdatetime(int(year),int(month),int(day))returndt.strftime(%Y-%m-%d)exceptValueError:passreturn# 测试dates[日期2024-06-01,2024年6月1日,06/01/2024,订单日期20240601,# 连续数字格式]fordindates:resultextract_date(d)print(f输入{d}-{resultifresultelse未识别})模块十进阶技能技能一用正则分组同时提取多个字段一条留言里可能同时包含姓名、手机号、地址。用正则分组一次提取importre text姓名张三手机13812345678地址广东省深圳市南山区patternr姓名[:]\s*(\S).*?手机\s*(\d{11}).*?地址[:]\s*(\S)matchre.search(pattern,text)ifmatch:namematch.group(1)phonematch.group(2)addressmatch.group(3)print(f姓名{name}手机{phone}地址{address})注意正则里的.*?问号表示非贪婪匹配即匹配尽可能少的字符。如果不加问号.*会匹配到最后一个符合条件的位置可能导致提取错误。技能二批量清洗特殊字符用户留言里经常有特殊字符emoji、不可见字符、全角半角混用。importredefclean_text(text): 清洗文本去掉emoji、不可见字符统一全角半角 # 去掉emojiUnicode范围textre.sub(r[\U00010000-\U0010ffff],,text)# 去掉不可见字符除了换行和制表符textre.sub(r[\x00-\x08\x0b\x0c\x0e-\x1f\x7f],,text)# 全角数字转半角forfull,halfin[(,0),(,1),(,2),(,3),(,4),(,5),(,6),(,7),(,8),(,9)]:texttext.replace(full,half)# 全角字母转半角简易版importstring# 这个范围处理用unicode码点转换resultforcharintext:if\uff01char\uff5e:# 全角字符转半角resultchr(ord(char)-0xfee0)else:resultcharreturnresult技能三用看看AI能不能帮上忙如果文本太乱正则写不出来可以考虑调用OCR或者NLP API。但大多数情况下把正则写严谨就够了。正则写不好时先在小批量数据上测试用re.findall()看看匹配结果再逐步调整正则。模块十一平台实战把文本提取流程部署到影刀控制台时注意以下几点。要点一留言内容可能包含敏感词有些用户留言里包含脏话或者敏感词直接存到Excel可能在打开时触发系统的内容审查。解决方法在清洗流程里加一个敏感词过滤步骤把敏感词替换成***。temu店群自动化报活动案例要点二提取结果要去重同一个手机号可能出现在多条留言里同一个人留了多次。提取完后用Python的set去重phones[13812345678,13987654321,13812345678]unique_phoneslist(set(phones))print(f去重前{len(phones)}条去重后{len(unique_phones)}条)注意set不保证顺序。如果需要保留第一次出现的顺序用以下方式unique_phones[]seenset()forphoneinphones:ifphonenotinseen:unique_phones.append(phone)seen.add(phone)模块十二系统联动与工程化规范工程化规范一正则表达式存到配置文件不要把正则写在代码里维护起来很麻烦。创建一个regex_patterns.json配置文件{phone:1[3-9]\\d{9},email:[a-zA-Z0-9._%-][a-zA-Z0-9.-]\\.[a-zA-Z]{2,},amount:\\d(?:,\\d{3})*(?:\\.\\d{2})?,date:\\d{4}[年\\-]\\d{1,2}[月\\-]\\d{1,2}}流程启动时读取这个文件正则需要修改时只改配置文件。工程化规范二提取结果的质量报告每次跑完提取流程自动生成一个质量报告defgenerate_quality_report(total,success,details): 生成提取质量报告 reportf 提取质量报告 总条数{total}成功提取{success}提取失败{total-success}提取成功率{success/total*100:.1f}% 失败详情 foritemindetails:reportf - 第{item[index]}行{item[text][:30]}...\nprint(report)# 保存报告到文件withopen(extract_report.txt,w,encodingutf-8)asf:f.write(report)速查表正则提取常用表达式目标正则表达式说明手机号1[3-9]\d{9}匹配11位手机号邮箱[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}标准邮箱格式金额数字\d(?:\.\d{2})?匹配整数或两位小数日期YYYY-MM-DD\d{4}-\d{1,2}-\d{1,2}简单匹配不验证合法性中文姓名[\u4e00-\u9fa5]{2,4}2-4个汉字身份证号\d{17}[\dXx]18位身份证邮政编码\d{6}6位数字去除所有空格\s用于re.sub替换报错排查指南报错re.error: unterminated character set原因正则里有未闭合的方括号[]。解决检查正则里所有的[是否有对应的]。报错提取结果比预期少原因正则默认是贪婪匹配或者用了错误的分组。解决在*或后面加?改成非贪婪匹配。总结文本清洗和正则提取核心是先清洗格式、再提取内容、最后验证结果。三步都做到位提取准确率就能到95%以上。剩下的5%特殊情况可以人工核查不必追求100%自动化。更多正则写法和文本处理案例访问 home.linyan.cloud 获取。#影刀RPA #RPA教程 #正则提取 #文本清洗 #数据提取作者林焱
影刀RPA新手教程文本清洗与正则提取完全指南——手机号、邮箱、金额、日期提取实战本文作者林焱 | 转载请注明出处开篇案例从3000条用户留言里提取手机号去年帮一个教育机构做RPA需求很简单每天从后台导出用户留言提取里面的手机号自动加微信。我写好流程跑第一批3000条留言提取出2800个手机号。交给客户后客户说“怎么有800多个是空号”我仔细一看提取出来的手机号里有写成了138-1234-5678的有写成了138 1234 5678的还有写成了(021)13812345678的。更离谱的是有人把手机号写在了句子中间比如我的号码是13812345678请加我。正则写得不够严谨把座机号、快递单号也当成了手机号提取出来。这次教训让我明白文本清洗和正则提取表面简单实际坑很多。本文所有案例围绕用户留言信息提取与清洗这条真实业务线展开。模块一安装与准备工作文本处理和正则提取在影刀RPA里主要用Python代码指令实现。影刀自带的正则相关指令“匹配正则表达式”、“替换正则表达式”也能用但功能有限。当需要处理复杂逻辑时还是Python更顺手。确保你的环境里Python版本在3.6以上正则的某些新特性需要3.6。关于Python环境的安装配置home.linyan.cloud 上有详细的图文教程照着做10分钟搞定。新建流程命名为文本清洗与提取Demo。模块二元素定位从网页提取文本文本清洗的前提是先把文本从网页或软件里提取出来。XPath提取网页文本内容//div[classuser-comment]/text()这个XPath提取class为user-comment的div标签里的文本节点。注意XPath的text()只提取直接子文本节点不提取子标签里的文本。如果想提取div内所有文本包括子标签里的用string(//div[classuser-comment])CSS选择器提取文本在影刀里用获取元素属性指令选中元素后用以下方式获取文本# 在影刀的执行JavaScript指令里js_code return document.querySelector(.user-comment).innerText; 从Excel批量读取待处理的文本很多时候文本存在Excel里用影刀的读取Excel指令批量读取存到一个列表变量里再逐条处理。模块三变量与数据类型正则表达式的返回类型用Python的re模块做正则提取要搞清楚每个函数返回什么类型importre text我的手机号是13812345678备用号13987654321# re.search返回第一个匹配的Match对象没找到返回Nonematchre.search(r1[3-9]\d{9},text)ifmatch:print(match.group())# 13812345678字符串print(match.span())# (6, 17)元组起始和结束位置# re.findall返回所有匹配的字符串列表没找到返回空列表phonesre.findall(r1[3-9]\d{9},text)[video(video-UbANf05A-1782836906410)(type-csdn)(url-https://live.csdn.net/v/embed/525010)(image-https://v-blog.csdnimg.cn/asset/f4faa587144cb7070f19e8b36813806b/cover/Cover0.jpg)(title-店群矩阵自动化突破运营极限)]print(phones)# [13812345678, 13987654321]列表# re.finditer返回迭代器每个元素是一个Match对象适合大文本forminre.finditer(r1[3-9]\d{9},text):print(m.group(),m.start())# re.sub返回替换后的字符串字符串cleanedre.sub(r\s,,text)print(cleaned)# 我的手机号是13812345678备用号13987654321我当时踩过这个坑把re.search()的返回值直接当字符串用。当没找到匹配时re.search()返回None对None调用.group()会报AttributeError。正确写法matchre.search(pattern,text)phonematch.group()ifmatchelse模块四流程控制批量文本处理处理大量文本时用循环配合条件判断。场景从留言列表里提取手机号提取不到的单独记录importre comments[我的手机号是13812345678请加我,QQ号123456789不加微信,电话号码021-12345678,手机138-1234-5678谢谢,]patternr1[3-9]\d{9}results[]no_match[]fori,commentinenumerate(comments):# 先清洗去掉所有空格、横杠、括号cleanedre.sub(r[\s\-()],,comment)matchre.search(pattern,cleaned)ifmatch:results.append({index:i,comment:comment,phone:match.group()})else:no_match.append({index:i,comment:comment})print(f成功提取{len(results)}条未提取到{len(no_match)}条)在影刀里这个逻辑用循环指令遍历列表用如果/否则指令判断提取结果用赋值指令把结果存到新的列表变量里。模块五网页自动化结合文本提取很多时候文本不在本地文件里而在网页上需要先用网页自动化把文本抓下来再做清洗。完整流程抓取网页留言并提取手机号用启动浏览器指令打开后台页面用循环指令翻页直到没有下一页用获取元素文本指令提取每条留言的内容把提取到的文本存到一个列表变量用Python代码指令批量清洗和提取把结果写入Excel等待页面加载完成的技巧网页留言往往是异步加载的抓文本时要等内容出现。importtime# 在影刀的Python代码指令里# 配合影刀的等待元素出现指令使用# 如果内容加载慢可以主动等待defwait_text_appear(element_xpath,timeout10): 等待元素文本出现内容不为空 foriinrange(timeout):# 用影刀的获取元素文本指令获取文本# 这里用伪代码表示逻辑textget_element_text(element_xpath)iftextandtext.strip():returntext time.sleep(1)returnNone模块六数据处理——手机号提取手机号的规则1开头第二位是3-9后面9位数字共11位。但要注意用户填写时会有各种格式。严格手机号提取只匹配纯数字11位importredefextract_phone(text): 从文本中提取手机号 先清洗格式字符再做匹配 # 第一步去掉所有非数字字符看看是否有11位连续数字以1开头digits_onlyre.sub(r\D,,text)matchre.search(r1[3-9]\d{9},digits_only)ifmatch:returnmatch.group()return# 测试test_cases[13812345678,# 标准格式138-1234-5678,# 带横杠138 1234 5678,# 带空格(021)13812345678,# 带区号括号手机13812345678,# 带中文前缀1381234567,# 只有10位不是手机号23812345678,# 2开头不是手机号]forcaseintest_cases:resultextract_phone(case)print(f输入{case}- 提取结果{resultifresultelse未提取到})排除座机号座机号以0开头或者是400/800开头。如果文本里同时有手机号和座机号要区分开importredefextract_phone_only(text): 只提取手机号排除座机号 # 去掉所有非数字digits_onlyre.sub(r\D,,text)# 如果以0开头是座机号跳过ifdigits_only.startswith(0):return# 如果以400或800开头是客服号跳过ifdigits_only.startswith(400)ordigits_only.startswith(800):return# 匹配手机号matchre.search(r1[3-9]\d{9},digits_only)returnmatch.group()ifmatchelse模块七数据处理——邮箱提取邮箱的正则表达式比手机号复杂因为邮箱格式多样。标准邮箱提取importredefextract_email(text): 从文本中提取邮箱地址 patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}matchre.search(pattern,text)returnmatch.group()ifmatchelse# 测试emails[我的邮箱是zhangsanexample.com,联系我lisi123163.com,work.emailtaggmail.com,# 号在邮箱里是合法的adminsub.domain.co.jp,# 多层级域名]foreinemails:print(extract_email(e))坑点邮箱后面的标点符号用户写邮箱时经常在后面加标点符号我的邮箱是zhangsanexample.com。请发邮件。 联系我lisi123163.com谢谢如果直接匹配会把句号或逗号也匹配进去。解决方法在正则里排除结尾的标点符号或者在匹配后做清洗defextract_email_clean(text):patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}matchre.search(pattern,text)ifnotmatch:returnemailmatch.group()# 去掉结尾的可能附着的标点符号emailemail.rstrip(.,;:!。)returnemail我当时踩过这个坑提取出来的邮箱带了一个中文句号发邮件时一直报邮箱地址无效排查了很久才发现问题。模块八数据处理——金额提取金额提取的难点格式多样有100元、“100”、“100.00”、一百元等。常见金额格式提取importredefextract_amount(text): 从文本中提取金额数字部分 支持100元、100、100.00、100.00元、1,000元 # 匹配各种金额格式patterns[r?\s*(\d(?:,\d{3})*(?:\.\d{2})?)\s*元?,# 100、100元、100.00元r(\d(?:,\d{3})*(?:\.\d{2})?)\s*元,# 100元r金额[:]\s*(\d(?:,\d{3})*(?:\.\d{2})?),# 金额100r合计[:]\s*(\d(?:,\d{3})*(?:\.\d{2})?),# 合计100]forpatterninpatterns:matchre.search(pattern,text)ifmatch:amount_strmatch.group(1).replace(,,)returnfloat(amount_str)return0.0# 测试test_cases[总价100元,199.00,金额1,299.00,合计 299元,没有金额信息,]forcaseintest_cases:amountextract_amount(case)print(f输入{case}- 金额{amount})中文金额转数字进阶如果遇到了一百元、贰佰叁拾元这种中文金额需要专门处理defchinese_amount_to_number(text): 把中文金额转成数字简化版支持佰以内的金额 cn_num{一:1,二:2,三:3,四:4,五:5,六:6,七:7,八:8,九:9,十:10}# 匹配X百Y十Z格式patternr([一二三四五六七八九])?百?([一二三四五六七八九])?十?([一二三四五六七八九])?元# 这个正则比较复杂实际项目中建议用现成的库pip install cn2antry:importcn2an # 提取中文金额字符串matchre.search(r[\u4e00-\u9fff]元,text)ifmatch:cn_amountmatch.group().rstrip(元)returncn2an.cn2an(cn_amount)exceptImportError:print(请先安装cn2an库pip install cn2an)return0模块九数据处理——日期提取日期格式比金额还多2024-06-01、2024/06/01、06/01/2024、2024年6月1日……通用日期提取importrefromdatetimeimportdatetimedefextract_date(text): 从文本中提取日期转成统一格式YYYY-MM-DD # 定义多种日期格式的正则patterns[(r(\d{4})[年\-/](\d{1,2})[月\-/](\d{1,2}),%Y%m%d),# 2024-06-01 或 2024年06月01日(r(\d{1,2})[月\-/](\d{1,2})[日\-/](\d{4})?,%m%d%Y),# 06/01/2024(r(\d{4})年(\d{1,2})月(\d{1,2})日,%Y%m%d),# 2024年6月1日]forpattern,fmtinpatterns:matchre.search(pattern,text)ifmatch:groupsmatch.groups()# 根据格式组装iffmt%Y%m%d:year,month,daygroupstry:dtdatetime(int(year),int(month),int(day))returndt.strftime(%Y-%m-%d)exceptValueError:passreturn# 测试dates[日期2024-06-01,2024年6月1日,06/01/2024,订单日期20240601,# 连续数字格式]fordindates:resultextract_date(d)print(f输入{d}-{resultifresultelse未识别})模块十进阶技能技能一用正则分组同时提取多个字段一条留言里可能同时包含姓名、手机号、地址。用正则分组一次提取importre text姓名张三手机13812345678地址广东省深圳市南山区patternr姓名[:]\s*(\S).*?手机\s*(\d{11}).*?地址[:]\s*(\S)matchre.search(pattern,text)ifmatch:namematch.group(1)phonematch.group(2)addressmatch.group(3)print(f姓名{name}手机{phone}地址{address})注意正则里的.*?问号表示非贪婪匹配即匹配尽可能少的字符。如果不加问号.*会匹配到最后一个符合条件的位置可能导致提取错误。技能二批量清洗特殊字符用户留言里经常有特殊字符emoji、不可见字符、全角半角混用。importredefclean_text(text): 清洗文本去掉emoji、不可见字符统一全角半角 # 去掉emojiUnicode范围textre.sub(r[\U00010000-\U0010ffff],,text)# 去掉不可见字符除了换行和制表符textre.sub(r[\x00-\x08\x0b\x0c\x0e-\x1f\x7f],,text)# 全角数字转半角forfull,halfin[(,0),(,1),(,2),(,3),(,4),(,5),(,6),(,7),(,8),(,9)]:texttext.replace(full,half)# 全角字母转半角简易版importstring# 这个范围处理用unicode码点转换resultforcharintext:if\uff01char\uff5e:# 全角字符转半角resultchr(ord(char)-0xfee0)else:resultcharreturnresult技能三用看看AI能不能帮上忙如果文本太乱正则写不出来可以考虑调用OCR或者NLP API。但大多数情况下把正则写严谨就够了。正则写不好时先在小批量数据上测试用re.findall()看看匹配结果再逐步调整正则。模块十一平台实战把文本提取流程部署到影刀控制台时注意以下几点。要点一留言内容可能包含敏感词有些用户留言里包含脏话或者敏感词直接存到Excel可能在打开时触发系统的内容审查。解决方法在清洗流程里加一个敏感词过滤步骤把敏感词替换成***。temu店群自动化报活动案例要点二提取结果要去重同一个手机号可能出现在多条留言里同一个人留了多次。提取完后用Python的set去重phones[13812345678,13987654321,13812345678]unique_phoneslist(set(phones))print(f去重前{len(phones)}条去重后{len(unique_phones)}条)注意set不保证顺序。如果需要保留第一次出现的顺序用以下方式unique_phones[]seenset()forphoneinphones:ifphonenotinseen:unique_phones.append(phone)seen.add(phone)模块十二系统联动与工程化规范工程化规范一正则表达式存到配置文件不要把正则写在代码里维护起来很麻烦。创建一个regex_patterns.json配置文件{phone:1[3-9]\\d{9},email:[a-zA-Z0-9._%-][a-zA-Z0-9.-]\\.[a-zA-Z]{2,},amount:\\d(?:,\\d{3})*(?:\\.\\d{2})?,date:\\d{4}[年\\-]\\d{1,2}[月\\-]\\d{1,2}}流程启动时读取这个文件正则需要修改时只改配置文件。工程化规范二提取结果的质量报告每次跑完提取流程自动生成一个质量报告defgenerate_quality_report(total,success,details): 生成提取质量报告 reportf 提取质量报告 总条数{total}成功提取{success}提取失败{total-success}提取成功率{success/total*100:.1f}% 失败详情 foritemindetails:reportf - 第{item[index]}行{item[text][:30]}...\nprint(report)# 保存报告到文件withopen(extract_report.txt,w,encodingutf-8)asf:f.write(report)速查表正则提取常用表达式目标正则表达式说明手机号1[3-9]\d{9}匹配11位手机号邮箱[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}标准邮箱格式金额数字\d(?:\.\d{2})?匹配整数或两位小数日期YYYY-MM-DD\d{4}-\d{1,2}-\d{1,2}简单匹配不验证合法性中文姓名[\u4e00-\u9fa5]{2,4}2-4个汉字身份证号\d{17}[\dXx]18位身份证邮政编码\d{6}6位数字去除所有空格\s用于re.sub替换报错排查指南报错re.error: unterminated character set原因正则里有未闭合的方括号[]。解决检查正则里所有的[是否有对应的]。报错提取结果比预期少原因正则默认是贪婪匹配或者用了错误的分组。解决在*或后面加?改成非贪婪匹配。总结文本清洗和正则提取核心是先清洗格式、再提取内容、最后验证结果。三步都做到位提取准确率就能到95%以上。剩下的5%特殊情况可以人工核查不必追求100%自动化。更多正则写法和文本处理案例访问 home.linyan.cloud 获取。#影刀RPA #RPA教程 #正则提取 #文本清洗 #数据提取作者林焱
影刀RPA新手教程:文本清洗与正则提取完全指南——手机号、邮箱、金额、日期提取实战
发布时间:2026/7/1 15:50:37
影刀RPA新手教程文本清洗与正则提取完全指南——手机号、邮箱、金额、日期提取实战本文作者林焱 | 转载请注明出处开篇案例从3000条用户留言里提取手机号去年帮一个教育机构做RPA需求很简单每天从后台导出用户留言提取里面的手机号自动加微信。我写好流程跑第一批3000条留言提取出2800个手机号。交给客户后客户说“怎么有800多个是空号”我仔细一看提取出来的手机号里有写成了138-1234-5678的有写成了138 1234 5678的还有写成了(021)13812345678的。更离谱的是有人把手机号写在了句子中间比如我的号码是13812345678请加我。正则写得不够严谨把座机号、快递单号也当成了手机号提取出来。这次教训让我明白文本清洗和正则提取表面简单实际坑很多。本文所有案例围绕用户留言信息提取与清洗这条真实业务线展开。模块一安装与准备工作文本处理和正则提取在影刀RPA里主要用Python代码指令实现。影刀自带的正则相关指令“匹配正则表达式”、“替换正则表达式”也能用但功能有限。当需要处理复杂逻辑时还是Python更顺手。确保你的环境里Python版本在3.6以上正则的某些新特性需要3.6。关于Python环境的安装配置home.linyan.cloud 上有详细的图文教程照着做10分钟搞定。新建流程命名为文本清洗与提取Demo。模块二元素定位从网页提取文本文本清洗的前提是先把文本从网页或软件里提取出来。XPath提取网页文本内容//div[classuser-comment]/text()这个XPath提取class为user-comment的div标签里的文本节点。注意XPath的text()只提取直接子文本节点不提取子标签里的文本。如果想提取div内所有文本包括子标签里的用string(//div[classuser-comment])CSS选择器提取文本在影刀里用获取元素属性指令选中元素后用以下方式获取文本# 在影刀的执行JavaScript指令里js_code return document.querySelector(.user-comment).innerText; 从Excel批量读取待处理的文本很多时候文本存在Excel里用影刀的读取Excel指令批量读取存到一个列表变量里再逐条处理。模块三变量与数据类型正则表达式的返回类型用Python的re模块做正则提取要搞清楚每个函数返回什么类型importre text我的手机号是13812345678备用号13987654321# re.search返回第一个匹配的Match对象没找到返回Nonematchre.search(r1[3-9]\d{9},text)ifmatch:print(match.group())# 13812345678字符串print(match.span())# (6, 17)元组起始和结束位置# re.findall返回所有匹配的字符串列表没找到返回空列表phonesre.findall(r1[3-9]\d{9},text)[video(video-UbANf05A-1782836906410)(type-csdn)(url-https://live.csdn.net/v/embed/525010)(image-https://v-blog.csdnimg.cn/asset/f4faa587144cb7070f19e8b36813806b/cover/Cover0.jpg)(title-店群矩阵自动化突破运营极限)]print(phones)# [13812345678, 13987654321]列表# re.finditer返回迭代器每个元素是一个Match对象适合大文本forminre.finditer(r1[3-9]\d{9},text):print(m.group(),m.start())# re.sub返回替换后的字符串字符串cleanedre.sub(r\s,,text)print(cleaned)# 我的手机号是13812345678备用号13987654321我当时踩过这个坑把re.search()的返回值直接当字符串用。当没找到匹配时re.search()返回None对None调用.group()会报AttributeError。正确写法matchre.search(pattern,text)phonematch.group()ifmatchelse模块四流程控制批量文本处理处理大量文本时用循环配合条件判断。场景从留言列表里提取手机号提取不到的单独记录importre comments[我的手机号是13812345678请加我,QQ号123456789不加微信,电话号码021-12345678,手机138-1234-5678谢谢,]patternr1[3-9]\d{9}results[]no_match[]fori,commentinenumerate(comments):# 先清洗去掉所有空格、横杠、括号cleanedre.sub(r[\s\-()],,comment)matchre.search(pattern,cleaned)ifmatch:results.append({index:i,comment:comment,phone:match.group()})else:no_match.append({index:i,comment:comment})print(f成功提取{len(results)}条未提取到{len(no_match)}条)在影刀里这个逻辑用循环指令遍历列表用如果/否则指令判断提取结果用赋值指令把结果存到新的列表变量里。模块五网页自动化结合文本提取很多时候文本不在本地文件里而在网页上需要先用网页自动化把文本抓下来再做清洗。完整流程抓取网页留言并提取手机号用启动浏览器指令打开后台页面用循环指令翻页直到没有下一页用获取元素文本指令提取每条留言的内容把提取到的文本存到一个列表变量用Python代码指令批量清洗和提取把结果写入Excel等待页面加载完成的技巧网页留言往往是异步加载的抓文本时要等内容出现。importtime# 在影刀的Python代码指令里# 配合影刀的等待元素出现指令使用# 如果内容加载慢可以主动等待defwait_text_appear(element_xpath,timeout10): 等待元素文本出现内容不为空 foriinrange(timeout):# 用影刀的获取元素文本指令获取文本# 这里用伪代码表示逻辑textget_element_text(element_xpath)iftextandtext.strip():returntext time.sleep(1)returnNone模块六数据处理——手机号提取手机号的规则1开头第二位是3-9后面9位数字共11位。但要注意用户填写时会有各种格式。严格手机号提取只匹配纯数字11位importredefextract_phone(text): 从文本中提取手机号 先清洗格式字符再做匹配 # 第一步去掉所有非数字字符看看是否有11位连续数字以1开头digits_onlyre.sub(r\D,,text)matchre.search(r1[3-9]\d{9},digits_only)ifmatch:returnmatch.group()return# 测试test_cases[13812345678,# 标准格式138-1234-5678,# 带横杠138 1234 5678,# 带空格(021)13812345678,# 带区号括号手机13812345678,# 带中文前缀1381234567,# 只有10位不是手机号23812345678,# 2开头不是手机号]forcaseintest_cases:resultextract_phone(case)print(f输入{case}- 提取结果{resultifresultelse未提取到})排除座机号座机号以0开头或者是400/800开头。如果文本里同时有手机号和座机号要区分开importredefextract_phone_only(text): 只提取手机号排除座机号 # 去掉所有非数字digits_onlyre.sub(r\D,,text)# 如果以0开头是座机号跳过ifdigits_only.startswith(0):return# 如果以400或800开头是客服号跳过ifdigits_only.startswith(400)ordigits_only.startswith(800):return# 匹配手机号matchre.search(r1[3-9]\d{9},digits_only)returnmatch.group()ifmatchelse模块七数据处理——邮箱提取邮箱的正则表达式比手机号复杂因为邮箱格式多样。标准邮箱提取importredefextract_email(text): 从文本中提取邮箱地址 patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}matchre.search(pattern,text)returnmatch.group()ifmatchelse# 测试emails[我的邮箱是zhangsanexample.com,联系我lisi123163.com,work.emailtaggmail.com,# 号在邮箱里是合法的adminsub.domain.co.jp,# 多层级域名]foreinemails:print(extract_email(e))坑点邮箱后面的标点符号用户写邮箱时经常在后面加标点符号我的邮箱是zhangsanexample.com。请发邮件。 联系我lisi123163.com谢谢如果直接匹配会把句号或逗号也匹配进去。解决方法在正则里排除结尾的标点符号或者在匹配后做清洗defextract_email_clean(text):patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}matchre.search(pattern,text)ifnotmatch:returnemailmatch.group()# 去掉结尾的可能附着的标点符号emailemail.rstrip(.,;:!。)returnemail我当时踩过这个坑提取出来的邮箱带了一个中文句号发邮件时一直报邮箱地址无效排查了很久才发现问题。模块八数据处理——金额提取金额提取的难点格式多样有100元、“100”、“100.00”、一百元等。常见金额格式提取importredefextract_amount(text): 从文本中提取金额数字部分 支持100元、100、100.00、100.00元、1,000元 # 匹配各种金额格式patterns[r?\s*(\d(?:,\d{3})*(?:\.\d{2})?)\s*元?,# 100、100元、100.00元r(\d(?:,\d{3})*(?:\.\d{2})?)\s*元,# 100元r金额[:]\s*(\d(?:,\d{3})*(?:\.\d{2})?),# 金额100r合计[:]\s*(\d(?:,\d{3})*(?:\.\d{2})?),# 合计100]forpatterninpatterns:matchre.search(pattern,text)ifmatch:amount_strmatch.group(1).replace(,,)returnfloat(amount_str)return0.0# 测试test_cases[总价100元,199.00,金额1,299.00,合计 299元,没有金额信息,]forcaseintest_cases:amountextract_amount(case)print(f输入{case}- 金额{amount})中文金额转数字进阶如果遇到了一百元、贰佰叁拾元这种中文金额需要专门处理defchinese_amount_to_number(text): 把中文金额转成数字简化版支持佰以内的金额 cn_num{一:1,二:2,三:3,四:4,五:5,六:6,七:7,八:8,九:9,十:10}# 匹配X百Y十Z格式patternr([一二三四五六七八九])?百?([一二三四五六七八九])?十?([一二三四五六七八九])?元# 这个正则比较复杂实际项目中建议用现成的库pip install cn2antry:importcn2an # 提取中文金额字符串matchre.search(r[\u4e00-\u9fff]元,text)ifmatch:cn_amountmatch.group().rstrip(元)returncn2an.cn2an(cn_amount)exceptImportError:print(请先安装cn2an库pip install cn2an)return0模块九数据处理——日期提取日期格式比金额还多2024-06-01、2024/06/01、06/01/2024、2024年6月1日……通用日期提取importrefromdatetimeimportdatetimedefextract_date(text): 从文本中提取日期转成统一格式YYYY-MM-DD # 定义多种日期格式的正则patterns[(r(\d{4})[年\-/](\d{1,2})[月\-/](\d{1,2}),%Y%m%d),# 2024-06-01 或 2024年06月01日(r(\d{1,2})[月\-/](\d{1,2})[日\-/](\d{4})?,%m%d%Y),# 06/01/2024(r(\d{4})年(\d{1,2})月(\d{1,2})日,%Y%m%d),# 2024年6月1日]forpattern,fmtinpatterns:matchre.search(pattern,text)ifmatch:groupsmatch.groups()# 根据格式组装iffmt%Y%m%d:year,month,daygroupstry:dtdatetime(int(year),int(month),int(day))returndt.strftime(%Y-%m-%d)exceptValueError:passreturn# 测试dates[日期2024-06-01,2024年6月1日,06/01/2024,订单日期20240601,# 连续数字格式]fordindates:resultextract_date(d)print(f输入{d}-{resultifresultelse未识别})模块十进阶技能技能一用正则分组同时提取多个字段一条留言里可能同时包含姓名、手机号、地址。用正则分组一次提取importre text姓名张三手机13812345678地址广东省深圳市南山区patternr姓名[:]\s*(\S).*?手机\s*(\d{11}).*?地址[:]\s*(\S)matchre.search(pattern,text)ifmatch:namematch.group(1)phonematch.group(2)addressmatch.group(3)print(f姓名{name}手机{phone}地址{address})注意正则里的.*?问号表示非贪婪匹配即匹配尽可能少的字符。如果不加问号.*会匹配到最后一个符合条件的位置可能导致提取错误。技能二批量清洗特殊字符用户留言里经常有特殊字符emoji、不可见字符、全角半角混用。importredefclean_text(text): 清洗文本去掉emoji、不可见字符统一全角半角 # 去掉emojiUnicode范围textre.sub(r[\U00010000-\U0010ffff],,text)# 去掉不可见字符除了换行和制表符textre.sub(r[\x00-\x08\x0b\x0c\x0e-\x1f\x7f],,text)# 全角数字转半角forfull,halfin[(,0),(,1),(,2),(,3),(,4),(,5),(,6),(,7),(,8),(,9)]:texttext.replace(full,half)# 全角字母转半角简易版importstring# 这个范围处理用unicode码点转换resultforcharintext:if\uff01char\uff5e:# 全角字符转半角resultchr(ord(char)-0xfee0)else:resultcharreturnresult技能三用看看AI能不能帮上忙如果文本太乱正则写不出来可以考虑调用OCR或者NLP API。但大多数情况下把正则写严谨就够了。正则写不好时先在小批量数据上测试用re.findall()看看匹配结果再逐步调整正则。模块十一平台实战把文本提取流程部署到影刀控制台时注意以下几点。要点一留言内容可能包含敏感词有些用户留言里包含脏话或者敏感词直接存到Excel可能在打开时触发系统的内容审查。解决方法在清洗流程里加一个敏感词过滤步骤把敏感词替换成***。temu店群自动化报活动案例要点二提取结果要去重同一个手机号可能出现在多条留言里同一个人留了多次。提取完后用Python的set去重phones[13812345678,13987654321,13812345678]unique_phoneslist(set(phones))print(f去重前{len(phones)}条去重后{len(unique_phones)}条)注意set不保证顺序。如果需要保留第一次出现的顺序用以下方式unique_phones[]seenset()forphoneinphones:ifphonenotinseen:unique_phones.append(phone)seen.add(phone)模块十二系统联动与工程化规范工程化规范一正则表达式存到配置文件不要把正则写在代码里维护起来很麻烦。创建一个regex_patterns.json配置文件{phone:1[3-9]\\d{9},email:[a-zA-Z0-9._%-][a-zA-Z0-9.-]\\.[a-zA-Z]{2,},amount:\\d(?:,\\d{3})*(?:\\.\\d{2})?,date:\\d{4}[年\\-]\\d{1,2}[月\\-]\\d{1,2}}流程启动时读取这个文件正则需要修改时只改配置文件。工程化规范二提取结果的质量报告每次跑完提取流程自动生成一个质量报告defgenerate_quality_report(total,success,details): 生成提取质量报告 reportf 提取质量报告 总条数{total}成功提取{success}提取失败{total-success}提取成功率{success/total*100:.1f}% 失败详情 foritemindetails:reportf - 第{item[index]}行{item[text][:30]}...\nprint(report)# 保存报告到文件withopen(extract_report.txt,w,encodingutf-8)asf:f.write(report)速查表正则提取常用表达式目标正则表达式说明手机号1[3-9]\d{9}匹配11位手机号邮箱[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}标准邮箱格式金额数字\d(?:\.\d{2})?匹配整数或两位小数日期YYYY-MM-DD\d{4}-\d{1,2}-\d{1,2}简单匹配不验证合法性中文姓名[\u4e00-\u9fa5]{2,4}2-4个汉字身份证号\d{17}[\dXx]18位身份证邮政编码\d{6}6位数字去除所有空格\s用于re.sub替换报错排查指南报错re.error: unterminated character set原因正则里有未闭合的方括号[]。解决检查正则里所有的[是否有对应的]。报错提取结果比预期少原因正则默认是贪婪匹配或者用了错误的分组。解决在*或后面加?改成非贪婪匹配。总结文本清洗和正则提取核心是先清洗格式、再提取内容、最后验证结果。三步都做到位提取准确率就能到95%以上。剩下的5%特殊情况可以人工核查不必追求100%自动化。更多正则写法和文本处理案例访问 home.linyan.cloud 获取。#影刀RPA #RPA教程 #正则提取 #文本清洗 #数据提取作者林焱
相关文章

堆料全能本标杆:机械革命无界 15X Pro(R7 H255 版)深度解析
在 4000 元价位全能轻薄本市场,机械革命无界 15X Pro 凭借锐龙 7 H255、32GB 大内存、1TB 固态与 99Wh 超大电池形成差异化优势,叠加国家家电补贴后性价比大幅提升,成为学生、办公人群的热门选择。整机兼顾性能、屏幕与长续航,同时…
MC6470与PIC24FV16KA304在运动控制中的优化应用
1. MC6470与PIC24FV16KA304的黄金组合解析在工业控制和运动定位领域,传感器与微控制器的选配往往决定着整个系统的性能上限。MC6470作为一款六自由度(6DOF)惯性测量单元(IMU),与PIC24FV16KA304这款16位微控制器的组合,正在成为中高端运动控制…
持证防火窗全流程验收流程及一次性通关实操方案
执行标准:GB 16809-2024《防火窗》、GB 50877-2014 施工验收规范,产品必须持有有效 CCC 强制认证,杜绝套证、非标减配。整套流程分为资料预审→进场材料核验→安装隐蔽验收→功能调试→竣工实体核查→资料归档六步,把所有扣分点前…

告别视频黑边!GSYVideoPlayer比例适配终极指南
告别视频黑边!GSYVideoPlayer比例适配终极指南 【免费下载链接】GSYVideoPlayer Video players (IJKplayer, ExoPlayer, MediaPlayer), HTTPS, 16k page size, danmaku (bullet chat) support, external subtitles, support for filters, watermarks, and GIF scree…
Avalonia 数据通知
目录 概要 关注 赞助 支持 概要 Avalonia系列教程每周五持续更新。喜欢本系列视频的观众可在B站或本公众号关注,并且可在评论区表达想看的内容。 视频地址 关注 关注Bilibili或本公众号,即可参与不定期会在视频结尾抽奖。 https://www.bilibili.…
深入解析XSS攻击:原理、类型、实战挖掘与纵深防御体系
1. 从一次真实的“弹窗”说起:理解XSS的威胁那天下午,我正在做常规的代码审查,一个前端同事跑过来,一脸困惑地问我:“老大,咱们的用户反馈系统里,怎么老是有用户说提交评论后会弹出奇怪的‘测试…
锂离子电池过压保护方案:BQ29200与STM32F373RC应用
1. 锂离子电池过压保护的必要性在锂离子电池应用中,过压保护是确保电池安全运行的关键防线。当充电电压超过电池额定上限(通常为4.2V50mV)时,电解液会开始分解产生气体,导致电池鼓包甚至热失控。根据行业统计ÿ…
ncmdump完整指南:三步解锁网易云音乐NCM加密格式的终极教程
ncmdump完整指南:三步解锁网易云音乐NCM加密格式的终极教程 【免费下载链接】ncmdump ncmdump - 网易云音乐NCM转换 项目地址: https://gitcode.com/gh_mirrors/ncmdu/ncmdump 你是否下载了网易云音乐却无法在其他播放器打开?是否发现精心收藏的歌…
3分钟解锁网易云音乐NCM格式:ncmdump让你的音乐随处可播
3分钟解锁网易云音乐NCM格式:ncmdump让你的音乐随处可播 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾遇到过这样的情况:从网易云音乐下载的歌曲只能在网易云音乐App中播放,无法在车载音…

FAE放射组学分析工具:医学影像特征探索的完整解决方案
FAE放射组学分析工具:医学影像特征探索的完整解决方案 【免费下载链接】FAE FeAture Explorer 项目地址: https://gitcode.com/gh_mirrors/fae/FAE 你是否曾经面对海量医学影像数据感到无从下手?想要从CT、MRI等影像中提取有价值的定量特征&#…
0.69B参数实现中文多模态AI:揭秘Qwen3-SmVL模型融合技术的完整实战指南
0.69B参数实现中文多模态AI:揭秘Qwen3-SmVL模型融合技术的完整实战指南 【免费下载链接】happy-llm 📚 从零开始构建大模型 项目地址: https://gitcode.com/GitHub_Trending/ha/happy-llm 还在为大型多模态模型动辄数十亿参数、显存占用高而烦恼&…
解锁AMD Ryzen处理器性能潜力的SMU调试神器:从新手到专家的完整指南
解锁AMD Ryzen处理器性能潜力的SMU调试神器:从新手到专家的完整指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…

AI Coding 六个月真实ROI账本:产品经理的血泪教训,研发的冷静忠告
6个月前的2025年12月,Boris Cherny 公开宣布自己卸载了 IDE。一时间,Vibe Coding 成了全行业最热的话题。6个月后,当我们回过头来拉一份真实账本,发现事情远没有"一句话生成一个App"那么浪漫。本文从产品经理和研发两个…
华为OD机试2025C卷-字符统计及重排[100分]( Java _ Python3 _ C++ _ C语言 _ JsNode _ Go)实现100%通过率
📫 个人主页:深夜coding算法 📣 专栏系列:2026年华为最新OD机试题库详解 🔥 一次订阅,永久解锁 | 持续更新100篇 | 6语言全覆盖 文章目录❄️前言:☀️一:题目描述🌙 题目…
华为OD机试2025C卷-寻找相同子串[100分]( Java _ Python3 _ C++ _ C语言 _ JsNode _ Go)实现100%通过率
📫 个人主页:深夜coding算法 📣 专栏系列:2026年华为最新OD机试题库详解 🔥 一次订阅,永久解锁 | 持续更新100篇 | 6语言全覆盖 文章目录❄️前言:☀️一:题目描述🌙 题目…

FAE放射组学分析工具:医学影像特征探索的完整解决方案
FAE放射组学分析工具:医学影像特征探索的完整解决方案 【免费下载链接】FAE FeAture Explorer 项目地址: https://gitcode.com/gh_mirrors/fae/FAE 你是否曾经面对海量医学影像数据感到无从下手?想要从CT、MRI等影像中提取有价值的定量特征&#…
0.69B参数实现中文多模态AI:揭秘Qwen3-SmVL模型融合技术的完整实战指南
0.69B参数实现中文多模态AI:揭秘Qwen3-SmVL模型融合技术的完整实战指南 【免费下载链接】happy-llm 📚 从零开始构建大模型 项目地址: https://gitcode.com/GitHub_Trending/ha/happy-llm 还在为大型多模态模型动辄数十亿参数、显存占用高而烦恼&…
解锁AMD Ryzen处理器性能潜力的SMU调试神器:从新手到专家的完整指南
解锁AMD Ryzen处理器性能潜力的SMU调试神器:从新手到专家的完整指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址…