![[特殊字符]新手/程序员必备!收藏学习LangGraph,轻松构建可控可维护的大模型AI应用[特殊字符]](images/coding-banner.jpg) 新手/程序员必备收藏学习LangGraph轻松构建可控可维护的大模型AI应用本文介绍LangGraph一种通过图形化流程显式建模Agent执行逻辑的工具帮助开发者实现可控、可维护的AI应用。文章从环境准备、核心概念解析到代码实战详细讲解了如何利用LangGraph构建基于大模型的RAG流程。通过State、Node、Edge、Graph等核心概念的讲解和具体代码示例旨在帮助初学者理解并掌握LangGraph为构建复杂、高效的AI系统打下坚实基础。简介随着 Agent 概念的普及以 Coze、Dify 为代表的低代码 / 无代码平台迅速兴起。这类平台通过可视化配置和模块化编排大幅降低了智能体应用的使用门槛使非技术用户也能快速构建 AI 应用在原型验证和轻量场景中具有明显优势。但当开发者开始将 Agent 系统真正用于业务落地时低代码平台的局限也逐渐显现。在私有化部署、复杂流程控制、工具调用灵活性以及调试与扩展能力等方面开发者往往需要受限于平台本身而难以完全按照业务逻辑自由设计。尤其是在多阶段任务、条件分支、循环处理以及“确定性逻辑与大模型推理混合执行”的场景中流程很容易变得臃肿且难以维护。在这样的背景下LangGraph 提供了一种更偏向工程视角的解决方案。它不试图用图形界面替代代码而是通过“图Graph”的形式将 Agent 的执行流程、状态流转和控制逻辑显式建模让开发者在保留大模型智能性的同时重新掌握系统的控制权。简而言之低代码平台关注的是“如何快速用起来”而 LangGraph 更关注“如何把系统长期跑好”。因此下面我们将从 LangGraph 最基础的 workflow 入手看看如何以工程化的方式构建一个可控、可维护的 Agent 流程。准备阶段环境准备在正式开始之前我们需要先安装一些必要的库pip install langchain langgraph langchain-community dashscope密钥准备然后我们还需要准备一个百炼大模型平台的密钥并写入 DASHSCOPE_API_KEY 中DASHSCOPE_API_KEY 你的 api keyLangGraph 基础简介在没有 LangGraph 之前你通常会遇到这些问题链式Chain只能线性执行不适合分支、循环Agent 行为不可控很难约束“下一步一定做什么”多轮调用中状态怎么保存什么时候结束什么时候回退 / 重试调试困难看不清一次调用内部发生了什么LangGraph 正是为了解决这些问题而出现的它把 LLM 应用的执行过程显式建模成一个“状态机 / 流程图”。核心概念在正式讲授课程内容之前这里我要先铺垫几个重要的概念包括State状态Node节点Edge边Graph图State状态State状态是整个 LangGraph 能够顺利运行的核心。它本质上是一个 Python dict / TypedDict / Pydantic 模型代表「当前执行到这一步时系统所拥有的全部信息」。比如说下面这样一个用于 RAG 系统的 state{ question: ..., # 用户问题 docs: [...], # RAG 检索结果 answer: ..., # 当前生成的答案}那我们随着任务的进行可能会不断得往这个 State 里去添加、替换里面的内容。但是这个 State 其实本质上就是整个流程图里所有需要被保存的信息了。所以在任何工作之前我们都需要先设计一个 State然后去思考每一步我们需要如何更新这个 state。Node节点那前面说了关于 State 的内容那谁去更新这些 State 呢其实就是基于一个个节点去进行更新也就是流程图中每一个子任务。那这些任务其实并不抽象本质上每个 Node 都代表着一个函数其输入的内容一般就是 State 里的内容。比如一个 RAG 的流程中我们一般会先检索完加载到提示词里传给模型进行回复。那这里吗就会存在着四个节点核心其实就是检索和模型两个节点问题传入questionSTART检索根据传入的问题进行检索模型将检索内容整合后并给出最终答案结果输出answerEND那在一开始当用户把问题传入的时候 那就会从 START 开始问题会直接被更新到 state 的 question 变量中。然后在检索的节点那就会从这个 state 里将 question 的内容提取出来以后进行检索。并且在检索完成以后将找到的片段内容存放到 docs 中。然后再到下一个节点也是一样的模型会先从 state 中找到检索到的 docs 以及最开始用户问题的问题 question然后将这两部分内容进行解析整合并且最终获取到输出最后将这部分内容更新到 state 的 answer 变量中。最后这个 answer 会传出来到 END最终整个流程就此完结。那此时我们基于这个流程图就可以设置以下两个节点.add_node(retrieve, retrieve) .add_node(llm, call_llm)所以可以看到其实这个 Node 就是每一部分的处理逻辑然后其也对应着一个函数传入的内容就是 state 的内容传出的内容则是对 state 内容的更新。这也是为什么我们要对 state 进行妥善设置的核心原因假如 State 无法正确的承接对于的变量信息的话那么很容造成整体的混乱。Edge边那有了一个个的节点了以后对于流程图而言还有一个很重要的工作就是将他们连接起来。对于一般的流程图而言其实就是将节点一一进行连接比如有 ABC 三个节点并且其连接方式如下所示A → B → C这种场景其实是比较简单的也是在 LangGraph 里最常见的我们只需要写成下面这样即可START 和 END 都是内置的from langgraph.graph import START, END.add_edge(START, A).add_edge(A, B).add_edge(B, C).add_edge(C, END)但是有些时候并不是直接线形连接的比如有一些通过判断决定的情况def route(state): if state[need_search]: return search else: return answer那这个时候我们可能就需要用到的是 .add_conditional_edges 进行实现了当然这里只是演示而已后续会更深入进行讲解graph.add_conditional_edges( decide, route, { search: retrieve, answer: generate }) 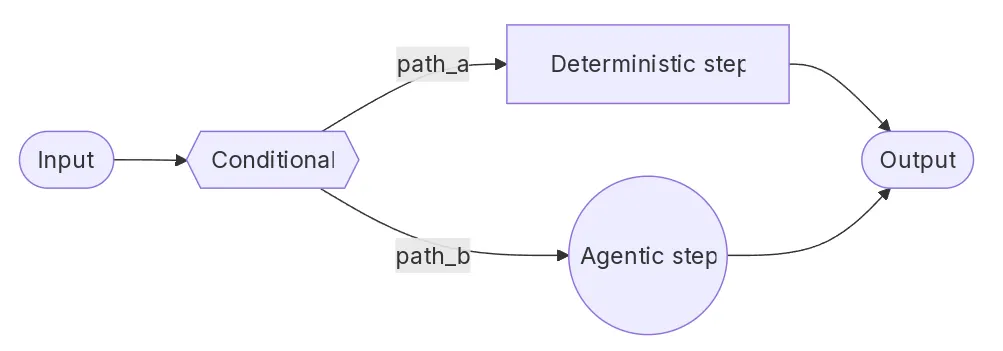 所以可以看到这个 edge 本质上就是将节点和节点连接起来对于一些特殊的情况也可以通过 conditional/_edges 的方法进行传递。 ### Graph图 最后就是 Graph 部分的内容了这个其实主要做的事情就是 * 创建状态机StateGraph * 注册所有 Node * 定义 Edge流程结构 * 指定 起点START 终点END * 将所有的内容进行编译.compile()后续就可以对该图进行调用了 比如下面要演示的 RAG 例子中整体的 Graph 就是如下所示 plaintext workflow ( StateGraph(State) .add_node(rewrite, rewrite_query) .add_node(retrieve, retrieve) .add_node(agent, call_agent) .add_edge(START, rewrite) .add_edge(rewrite, retrieve) .add_edge(retrieve, agent) .add_edge(agent, END) .compile())以上就是学习 LangGraph 构建流程图前必须了解的核心概念了下面我们那将基于一个简单的代码示例来演示一下这部分是如何实现的吧代码实战任务简介首先这里我简单介绍一下这个任务。这个任务是模拟一个真实的 RAG 调用场景然后通过用户提出的问题获取智能体的回复START ↓rewrite 把用户问题改写成更适合检索的 query ↓retrieve 用改写后的 query 去向量库检索 documents ↓agent 把 documents 原问题一起喂给 agent 生成答案 ↓END具体实现的流程图如下在开始运行前需要载入以下的库并且设置大模型from typing import TypedDictfrom pydantic import BaseModelfrom langgraph.graph import StateGraph, START, ENDfrom langchain.agents import create_agentfrom langchain.tools import toolfrom langchain_core.vectorstores import InMemoryVectorStorefrom langchain_community.chat_models import ChatTongyifrom langchain_community.embeddings import DashScopeEmbeddingsimport osmodel ChatTongyi(api_keyos.environ.get(DASHSCOPE_API_KEY), modelqwen-max)状态构建就像前面介绍 LangGraph 的一样在我们了解完整体的任务需求后我们就可以开始去设计内部需要的状态内容class State(TypedDict): question: str rewritten_query: str documents: list[str] answer: str这里我们总共设置了四个状态内容其具体完成的内容包括question对应的是最开始用户传入的问题rewritten_query基于传入的 question 内容后改写的搜索语句对应 rewrite 模块documents基于传入的 rewritten_query 搜索到的内容对应 retrieve 模块answer基于最开始的 question 和搜索到的 documents 给到 agent 并进行回复对应 agent 模块所以我们可以看到state 的设置完全是为了整体流程而服务的。每一个 state 的目的都是为了接收其中一个流程输出的内容。重写节点构建在设置完 state 了以后其实我们也已经对其中的流程节点有了更进一步的认识。下面我们就来看看第一个关键节点—rewrite 是如何进行设置的。首先我们要明确的是这部分的输入和输出格式和内容是什么。很显然这里没有很复杂的数据类型输入的就是 question 的内容这个我们可以从 state 中获取到。然后最终模型的输出我们要的是一个字符串的回复内容。基于这个基本思路我们就可以开始写代码了。那这里 rewrite 的话我们并不是通过别的 nlp 的方法实现而还是使用大模型来对其进行改写。假如用大模型来改写的话我们必须说清楚其需要完成的内容是什么所以就要完成系统提示词的撰写。这里的我们的系统提示词主要就是介绍了一下任务是什么然后要去检索的信息是什么领域的还有重点关注的内容等信息。用户提示词就只是在 state 里传入的 question。但是直接调用大模型返回的内容是 LangChain 格式的 AIMessage 并不是我们多希望的字符串信息。所以这里我们使用了一个结构化输出的方法 .with_structured_output。这个方法可以绑定一个 Pydantic 定义的类然后按类里定义的内容进行结构化的输出。这里我们创建的就是 RewrittenQuery里面就只有一个元素 query并且设定其格式为我们所需要的字符串。那此时通过model.with_structured_output(RewrittenQuery) 调用返回的结果就不再是 AIMesaage 了而是一个格式化的 pydanfic 类了我们只需要通过 .query 就可以将其中字符串的内容进行获取。最后我们返回的内容就是要更新 state 里的 rewritten_query 信息的因此我们就返回了一个对应的字典进去并且把对应的字符串内容也放进去。那么当调用这个节点的时候就会自动进行更新了。class RewrittenQuery(BaseModel): query: strdef rewrite_query(state: State) - dict: Rewrite the user query for better retrieval. system_prompt Rewrite this query to retrieve relevant WNBA information.The knowledge base contains: team rosters, game results with scores, and player statistics (PPG, RPG, APG).Focus on specific player names, team names, or stat categories mentioned. response model.with_structured_output(RewrittenQuery).invoke([ {role: system, content: system_prompt}, {role: user, content: state[question]} ]) return {rewritten_query: response.query}但是这里有个点需要注意就是with_structured_output 并不是强约束而是一次“尝试解析”。当模型输出无法正确映射到 schema 时返回值可能为 None因此在真实项目中应始终做好兜底处理。检索节点创建对于检索节点而言其实第一步是要创建一个向量数据库才能实现对向量数据库的检索。向量数据库创建首先创建向量数据库需要准备将文本转为向量的 embedding 模型以及将向量内容保存的向量数据库。这里使用的 embedding 模型就是 dashscope 的 embedding 模型。幸运的是这个和 qwen 模型是共用一个 api_key 的所以我们可以直接使用。然后选择好 embedding 模型后我们就可以选择合适的向量数据库。由于这里只是演示因此这里选用的就是最简单的将向量保存在内存的 InMemoryVectorStore 程序跑完就自动释放了。我们通过传入 embedding 模型即可进行创建。创建完后我们就可以往里面写入内容了。这里我们就通过 .add_text 的方法往里面写入了多条数据。这样向量数据库就已经创建好了。embeddings DashScopeEmbeddings( dashscope_api_keyos.getenv(DASHSCOPE_API_KEY), modeltext-embedding-v1)vector_store InMemoryVectorStore(embeddings)vector_store.add_texts([ # Rosters New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot., Las Vegas Aces 2024 roster: Aja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray., Indiana Fever 2024 roster: Caitlin Clark, Aliyah Boston, Kelsey Mitchell, NaLyssa Smith., # Game results 2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship., June 15, 2024: Indiana Fever 85, Chicago Sky 79. Caitlin Clark had 23 points and 8 assists., August 20, 2024: Las Vegas Aces 92, Phoenix Mercury 84. Aja Wilson scored 35 points., # Player stats Aja Wilson 2024 season stats: 26.9 PPG, 11.9 RPG, 2.6 BPG. Won MVP award., Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year., Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.,])检索函数设置创建完成后我们就可以基于这个向量数据库来创建一个检索节点了。那首先我们先要定义一个检索器。所谓检索器其实就是输入问题输出找到的文档片段。这里我们就通过vector_store.as_retriever方法进行了实现并且设置了 k5 这个参数即找到最相关的 5 个文档片段这样。retriever vector_store.as_retriever(search_kwargs{k: 5})创建好了检索器后我们也是可以基于检索器来设置检索节点的内容。那这里我们先将 state 中的 rewritten_query 部分内容取出然后通过 .invoke() 的方法传入检索器中。这样的话就能够找到多个 Document 的文档片段。但是这些个文档片段不能够直接放入到 State 中因为还有很多没有用的元数据在这些 Document 类中。因此我们需要先通过 for 语句一个个地将其提取出来然后通过 doc.page_content 来将里面的文本字符串内容提取出来最终形成一个包含 5 个长文本字符串的列表并且传入到 state 的 documents 中进行保存。def retrieve(state: State) - dict: Retrieve documents based on the rewritten query. docs retriever.invoke(state[rewritten_query]) return {documents: [doc.page_content for doc in docs]}智能体节点构建在构建完检索的节点后下一步就可以着手完成最后一个智能体节点的构建。那对于智能体而言其实最重要的就两个事一个是要给智能体一个什么样的大模型作为大脑这里我们就用前面创建好的 model 进行实现即可。另外一个就是要配套的是什么工具。工具那对于工具而言我们首先要去思考这个 agent 要完成的任务是什么。前面我们已经说了其需要去查询向量数据库当中的 WNBA 内容。所以很明显我们这个智能体要完成的就是搜查和 WNBA 相关内容的工作。那 WNBA 现在还一直有在打因此这里我们就应该去设置一个获取最近 WNBA 消息的工具才可以。当然这里的工具是假装的而已但是我们可以换上真实的 API 并进行使用tooldef get_latest_news(query: str) - str: Get the latest WNBA news and updates. # Your news API here return Latest: The WNBA announced expanded playoff format for 2025...实现 agent 节点有了工具和模型后我们就可以将两者进行组合形成一个 agent。agent create_agent( modelmodel, tools[get_latest_news],)那对于检索节点而言前面其实已经说了我们就是把原问题和找到的文档内容组合成提示词然后给到智能体所以这里我们就先从 state 中将 documents 和 question 都给提取出来。然后通过 f-string 的方式将其拼装起来形成 prompt。当然 documents 是一个列表要先进行 .join() 处理将其进行整合。def call_agent(state: State) - dict: Generate answer using retrieved context. context /n/n.join(state[documents]) prompt fContext:/n{context}/n/nQuestion: {state[question]} response agent.invoke({messages: [{role: user, content: prompt}]}) return {answer: response[messages][-1].content}然后准备好了 pormpt就可以直接将 prompt 作为用户提示词进行传入即可。最后我们就能够获取到返回 AIMessage 中的 content 作为文本字符串并将其更新到 state 中的 answer 字段中。整体流程图构建当每一个节点都构建完成后我们就可以构建整体 LangGraph 的流程图了。对于这个 workflow 来说首先第一步就是要先将图进行创建也就是 StateGraph() 这部分内容。在这个图里面呢我们还需要将 State 也给存进去从而告诉 LangGraph 全程都要使用该 State 实现。然后呢我们就可以把刚刚做好的三个函数与三个节点通过 .add_node() 的方式进行创建并且分别给他们附上 rewrite, retrieve 和 agent 的名称。节点创建好了以后就可以通过 .add_edge() 去按顺序来进行边的连接了。那这里我们都是线性的连接所以就是从 START 开始然后到 rewrite再到 retrieve再到 agent 然后就到 END 结束了。那最后整个 workflow 返回的内容其实就是整个 state 的字典我们可以从中提取我们所需要的内容。当边都设置完了以后最后我们还需要对整个 workflow 进行编译也就是 .compile这样的话整个 workflow 才能后续进行调用。workflow ( StateGraph(State) .add_node(rewrite, rewrite_query) .add_node(retrieve, retrieve) .add_node(agent, call_agent) .add_edge(START, rewrite) .add_edge(rewrite, retrieve) .add_edge(retrieve, agent) .add_edge(agent, END) .compile())流程图调用编译完了以后我们就可以对 workflow 进行 .invoke 的调用了。比如说问一个 2024 年的 WNBA 冠军是谁result workflow.invoke({question: Who won the 2024 WNBA Championship?})print(result)此时我们可以把 result 打印出来看看里面具体的内容是什么。那通过下面的代码块其实可以看出来其实整个返回的 result 就是我们前面设置的 state只不过是已经加载好所有内容的 state 了。我们可以看到提问的问题、改写的问题、找到的内容片段以及最后的回复信息。{question: Who won the 2024 WNBA Championship?, rewritten_query: 2024 WNBA Championship winner, documents: [2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship., New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot., Las Vegas Aces 2024 roster: Aja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray., Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year., Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.], answer: The 2024 WNBA Championship was won by the New York Liberty, as they defeated the Minnesota Lynx 3-2 in the finals.}假如我们做的是一个对话类的平台其实其他信息我们都可以不返回给用户我们只需要返回最后的 answer 即可print(result[answer])总结通过本文的完整示例可以看到LangGraph 并不是在“重新发明 Agent”而是从工程视角出发对 Agent 的执行流程、状态管理与控制逻辑进行了系统化重构。它将原本隐藏在 Agent 内部的推理步骤与执行顺序显式地建模为一张可阅读、可调试、可扩展的 workflow 图使开发者能够真正理解并掌控智能体在“每一步究竟做了什么”。在这个基础示例中我们从 State 的设计出发逐步构建了 rewrite、retrieve、agent 等节点并通过 Edge 明确规定了流程的执行顺序。整个过程中大模型只在“确实需要智能推理”的节点中参与其余逻辑则以确定性的代码形式存在从而在智能性与可控性之间取得了良好的平衡。这种设计方式正是 LangGraph 相较于低代码 Agent 平台最核心的优势所在。更重要的是这种 workflow 思维并不仅仅适用于 RAG 场景。无论是多 Agent 协作、复杂条件路由、循环重试还是人类介入HITL、调试回放与状态追踪都可以在同一套 Graph 抽象下自然演进。它为 Agent 系统提供的并不是“更快搭出来”的能力而是“长期可维护、可演化”的工程基础。在后续内容中我们将基于这一基础 workflow进一步引入条件分支、路由决策、多智能体协作等更复杂的模式逐步展示 LangGraph 在真实业务与教学场景中的完整威力。希望你在读完这篇文章后不仅“会用 LangGraph”更能建立起一种以流程与状态为中心的 Agent 工程思维。## 最后近期科技圈传来重磅消息行业巨头英特尔宣布大规模裁员2万人传统技术岗位持续萎缩的同时另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式据行业招聘数据显示具备3-5年大模型相关经验的开发者在大厂就能拿到50K×20薪的高薪待遇薪资差距肉眼可见业内资深HR预判不出1年“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下“温水煮青蛙”式的等待只会让自己逐渐被淘汰与其被动应对不如主动出击抢先掌握AI大模型核心原理落地应用技术项目实操经验借行业风口实现职业翻盘深知技术人入门大模型时容易走弯路我特意整理了一套全网最全最细的大模型零基础学习礼包涵盖入门思维导图、经典书籍手册、从入门到进阶的实战视频、可直接运行的项目源码等核心内容。这份资料无需付费免费分享给所有想入局AI大模型的朋友扫码免费领取全部内容部分资料展示1、 AI大模型学习路线图2、 全套AI大模型应用开发视频教程从入门到进阶这里都有跟着老师学习事半功倍。3、 大模型学习书籍文档4、AI大模型最新行业报告2025最新行业报告针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估以了解哪些行业更适合引入大模型的技术和应用以及在哪些方面可以发挥大模型的优势。5、大模型大厂面试真题整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题涵盖基础理论、技术实操、项目经验等维度每道题都配有详细解析和答题思路帮你针对性提升面试竞争力。6、大模型项目实战配套源码学以致用在项目实战中检验和巩固你所学到的知识同时为你找工作就业和职业发展打下坚实的基础。学会后的收获• 基于大模型全栈工程实现前端、后端、产品经理、设计、数据分析等通过这门课可获得不同能力• 能够利用大模型解决相关实际项目需求 大数据时代越来越多的企业和机构需要处理海量数据利用大模型技术可以更好地处理这些数据提高数据分析和决策的准确性。因此掌握大模型应用开发技能可以让程序员更好地应对实际项目需求• 基于大模型和企业数据AI应用开发实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能 学会Fine-tuning垂直训练大模型数据准备、数据蒸馏、大模型部署一站式掌握• 能够完成时下热门大模型垂直领域模型训练能力提高程序员的编码能力 大模型应用开发需要掌握机器学习算法、深度学习框架等技术这些技术的掌握可以提高程序员的编码能力和分析能力让程序员更加熟练地编写高质量的代码。扫码免费领取全部内容这些资料真的有用吗这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理现任上海殷泊信息科技CEO其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证服务航天科工、国家电网等1000企业以第一作者在IEEE Transactions发表论文50篇获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。资料内容涵盖了从入门到进阶的各类视频教程和实战项目无论你是小白还是有些技术基础的技术人员这份资料都绝对能帮助你提升薪资待遇转行大模型岗位。这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
新手/程序员必备收藏学习LangGraph轻松构建可控可维护的大模型AI应用本文介绍LangGraph一种通过图形化流程显式建模Agent执行逻辑的工具帮助开发者实现可控、可维护的AI应用。文章从环境准备、核心概念解析到代码实战详细讲解了如何利用LangGraph构建基于大模型的RAG流程。通过State、Node、Edge、Graph等核心概念的讲解和具体代码示例旨在帮助初学者理解并掌握LangGraph为构建复杂、高效的AI系统打下坚实基础。简介随着 Agent 概念的普及以 Coze、Dify 为代表的低代码 / 无代码平台迅速兴起。这类平台通过可视化配置和模块化编排大幅降低了智能体应用的使用门槛使非技术用户也能快速构建 AI 应用在原型验证和轻量场景中具有明显优势。但当开发者开始将 Agent 系统真正用于业务落地时低代码平台的局限也逐渐显现。在私有化部署、复杂流程控制、工具调用灵活性以及调试与扩展能力等方面开发者往往需要受限于平台本身而难以完全按照业务逻辑自由设计。尤其是在多阶段任务、条件分支、循环处理以及“确定性逻辑与大模型推理混合执行”的场景中流程很容易变得臃肿且难以维护。在这样的背景下LangGraph 提供了一种更偏向工程视角的解决方案。它不试图用图形界面替代代码而是通过“图Graph”的形式将 Agent 的执行流程、状态流转和控制逻辑显式建模让开发者在保留大模型智能性的同时重新掌握系统的控制权。简而言之低代码平台关注的是“如何快速用起来”而 LangGraph 更关注“如何把系统长期跑好”。因此下面我们将从 LangGraph 最基础的 workflow 入手看看如何以工程化的方式构建一个可控、可维护的 Agent 流程。准备阶段环境准备在正式开始之前我们需要先安装一些必要的库pip install langchain langgraph langchain-community dashscope密钥准备然后我们还需要准备一个百炼大模型平台的密钥并写入 DASHSCOPE_API_KEY 中DASHSCOPE_API_KEY 你的 api keyLangGraph 基础简介在没有 LangGraph 之前你通常会遇到这些问题链式Chain只能线性执行不适合分支、循环Agent 行为不可控很难约束“下一步一定做什么”多轮调用中状态怎么保存什么时候结束什么时候回退 / 重试调试困难看不清一次调用内部发生了什么LangGraph 正是为了解决这些问题而出现的它把 LLM 应用的执行过程显式建模成一个“状态机 / 流程图”。核心概念在正式讲授课程内容之前这里我要先铺垫几个重要的概念包括State状态Node节点Edge边Graph图State状态State状态是整个 LangGraph 能够顺利运行的核心。它本质上是一个 Python dict / TypedDict / Pydantic 模型代表「当前执行到这一步时系统所拥有的全部信息」。比如说下面这样一个用于 RAG 系统的 state{ question: ..., # 用户问题 docs: [...], # RAG 检索结果 answer: ..., # 当前生成的答案}那我们随着任务的进行可能会不断得往这个 State 里去添加、替换里面的内容。但是这个 State 其实本质上就是整个流程图里所有需要被保存的信息了。所以在任何工作之前我们都需要先设计一个 State然后去思考每一步我们需要如何更新这个 state。Node节点那前面说了关于 State 的内容那谁去更新这些 State 呢其实就是基于一个个节点去进行更新也就是流程图中每一个子任务。那这些任务其实并不抽象本质上每个 Node 都代表着一个函数其输入的内容一般就是 State 里的内容。比如一个 RAG 的流程中我们一般会先检索完加载到提示词里传给模型进行回复。那这里吗就会存在着四个节点核心其实就是检索和模型两个节点问题传入questionSTART检索根据传入的问题进行检索模型将检索内容整合后并给出最终答案结果输出answerEND那在一开始当用户把问题传入的时候 那就会从 START 开始问题会直接被更新到 state 的 question 变量中。然后在检索的节点那就会从这个 state 里将 question 的内容提取出来以后进行检索。并且在检索完成以后将找到的片段内容存放到 docs 中。然后再到下一个节点也是一样的模型会先从 state 中找到检索到的 docs 以及最开始用户问题的问题 question然后将这两部分内容进行解析整合并且最终获取到输出最后将这部分内容更新到 state 的 answer 变量中。最后这个 answer 会传出来到 END最终整个流程就此完结。那此时我们基于这个流程图就可以设置以下两个节点.add_node(retrieve, retrieve) .add_node(llm, call_llm)所以可以看到其实这个 Node 就是每一部分的处理逻辑然后其也对应着一个函数传入的内容就是 state 的内容传出的内容则是对 state 内容的更新。这也是为什么我们要对 state 进行妥善设置的核心原因假如 State 无法正确的承接对于的变量信息的话那么很容造成整体的混乱。Edge边那有了一个个的节点了以后对于流程图而言还有一个很重要的工作就是将他们连接起来。对于一般的流程图而言其实就是将节点一一进行连接比如有 ABC 三个节点并且其连接方式如下所示A → B → C这种场景其实是比较简单的也是在 LangGraph 里最常见的我们只需要写成下面这样即可START 和 END 都是内置的from langgraph.graph import START, END.add_edge(START, A).add_edge(A, B).add_edge(B, C).add_edge(C, END)但是有些时候并不是直接线形连接的比如有一些通过判断决定的情况def route(state): if state[need_search]: return search else: return answer那这个时候我们可能就需要用到的是 .add_conditional_edges 进行实现了当然这里只是演示而已后续会更深入进行讲解graph.add_conditional_edges( decide, route, { search: retrieve, answer: generate })  所以可以看到这个 edge 本质上就是将节点和节点连接起来对于一些特殊的情况也可以通过 conditional/_edges 的方法进行传递。 ### Graph图 最后就是 Graph 部分的内容了这个其实主要做的事情就是 * 创建状态机StateGraph * 注册所有 Node * 定义 Edge流程结构 * 指定 起点START 终点END * 将所有的内容进行编译.compile()后续就可以对该图进行调用了 比如下面要演示的 RAG 例子中整体的 Graph 就是如下所示 plaintext workflow ( StateGraph(State) .add_node(rewrite, rewrite_query) .add_node(retrieve, retrieve) .add_node(agent, call_agent) .add_edge(START, rewrite) .add_edge(rewrite, retrieve) .add_edge(retrieve, agent) .add_edge(agent, END) .compile())以上就是学习 LangGraph 构建流程图前必须了解的核心概念了下面我们那将基于一个简单的代码示例来演示一下这部分是如何实现的吧代码实战任务简介首先这里我简单介绍一下这个任务。这个任务是模拟一个真实的 RAG 调用场景然后通过用户提出的问题获取智能体的回复START ↓rewrite 把用户问题改写成更适合检索的 query ↓retrieve 用改写后的 query 去向量库检索 documents ↓agent 把 documents 原问题一起喂给 agent 生成答案 ↓END具体实现的流程图如下在开始运行前需要载入以下的库并且设置大模型from typing import TypedDictfrom pydantic import BaseModelfrom langgraph.graph import StateGraph, START, ENDfrom langchain.agents import create_agentfrom langchain.tools import toolfrom langchain_core.vectorstores import InMemoryVectorStorefrom langchain_community.chat_models import ChatTongyifrom langchain_community.embeddings import DashScopeEmbeddingsimport osmodel ChatTongyi(api_keyos.environ.get(DASHSCOPE_API_KEY), modelqwen-max)状态构建就像前面介绍 LangGraph 的一样在我们了解完整体的任务需求后我们就可以开始去设计内部需要的状态内容class State(TypedDict): question: str rewritten_query: str documents: list[str] answer: str这里我们总共设置了四个状态内容其具体完成的内容包括question对应的是最开始用户传入的问题rewritten_query基于传入的 question 内容后改写的搜索语句对应 rewrite 模块documents基于传入的 rewritten_query 搜索到的内容对应 retrieve 模块answer基于最开始的 question 和搜索到的 documents 给到 agent 并进行回复对应 agent 模块所以我们可以看到state 的设置完全是为了整体流程而服务的。每一个 state 的目的都是为了接收其中一个流程输出的内容。重写节点构建在设置完 state 了以后其实我们也已经对其中的流程节点有了更进一步的认识。下面我们就来看看第一个关键节点—rewrite 是如何进行设置的。首先我们要明确的是这部分的输入和输出格式和内容是什么。很显然这里没有很复杂的数据类型输入的就是 question 的内容这个我们可以从 state 中获取到。然后最终模型的输出我们要的是一个字符串的回复内容。基于这个基本思路我们就可以开始写代码了。那这里 rewrite 的话我们并不是通过别的 nlp 的方法实现而还是使用大模型来对其进行改写。假如用大模型来改写的话我们必须说清楚其需要完成的内容是什么所以就要完成系统提示词的撰写。这里的我们的系统提示词主要就是介绍了一下任务是什么然后要去检索的信息是什么领域的还有重点关注的内容等信息。用户提示词就只是在 state 里传入的 question。但是直接调用大模型返回的内容是 LangChain 格式的 AIMessage 并不是我们多希望的字符串信息。所以这里我们使用了一个结构化输出的方法 .with_structured_output。这个方法可以绑定一个 Pydantic 定义的类然后按类里定义的内容进行结构化的输出。这里我们创建的就是 RewrittenQuery里面就只有一个元素 query并且设定其格式为我们所需要的字符串。那此时通过model.with_structured_output(RewrittenQuery) 调用返回的结果就不再是 AIMesaage 了而是一个格式化的 pydanfic 类了我们只需要通过 .query 就可以将其中字符串的内容进行获取。最后我们返回的内容就是要更新 state 里的 rewritten_query 信息的因此我们就返回了一个对应的字典进去并且把对应的字符串内容也放进去。那么当调用这个节点的时候就会自动进行更新了。class RewrittenQuery(BaseModel): query: strdef rewrite_query(state: State) - dict: Rewrite the user query for better retrieval. system_prompt Rewrite this query to retrieve relevant WNBA information.The knowledge base contains: team rosters, game results with scores, and player statistics (PPG, RPG, APG).Focus on specific player names, team names, or stat categories mentioned. response model.with_structured_output(RewrittenQuery).invoke([ {role: system, content: system_prompt}, {role: user, content: state[question]} ]) return {rewritten_query: response.query}但是这里有个点需要注意就是with_structured_output 并不是强约束而是一次“尝试解析”。当模型输出无法正确映射到 schema 时返回值可能为 None因此在真实项目中应始终做好兜底处理。检索节点创建对于检索节点而言其实第一步是要创建一个向量数据库才能实现对向量数据库的检索。向量数据库创建首先创建向量数据库需要准备将文本转为向量的 embedding 模型以及将向量内容保存的向量数据库。这里使用的 embedding 模型就是 dashscope 的 embedding 模型。幸运的是这个和 qwen 模型是共用一个 api_key 的所以我们可以直接使用。然后选择好 embedding 模型后我们就可以选择合适的向量数据库。由于这里只是演示因此这里选用的就是最简单的将向量保存在内存的 InMemoryVectorStore 程序跑完就自动释放了。我们通过传入 embedding 模型即可进行创建。创建完后我们就可以往里面写入内容了。这里我们就通过 .add_text 的方法往里面写入了多条数据。这样向量数据库就已经创建好了。embeddings DashScopeEmbeddings( dashscope_api_keyos.getenv(DASHSCOPE_API_KEY), modeltext-embedding-v1)vector_store InMemoryVectorStore(embeddings)vector_store.add_texts([ # Rosters New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot., Las Vegas Aces 2024 roster: Aja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray., Indiana Fever 2024 roster: Caitlin Clark, Aliyah Boston, Kelsey Mitchell, NaLyssa Smith., # Game results 2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship., June 15, 2024: Indiana Fever 85, Chicago Sky 79. Caitlin Clark had 23 points and 8 assists., August 20, 2024: Las Vegas Aces 92, Phoenix Mercury 84. Aja Wilson scored 35 points., # Player stats Aja Wilson 2024 season stats: 26.9 PPG, 11.9 RPG, 2.6 BPG. Won MVP award., Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year., Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.,])检索函数设置创建完成后我们就可以基于这个向量数据库来创建一个检索节点了。那首先我们先要定义一个检索器。所谓检索器其实就是输入问题输出找到的文档片段。这里我们就通过vector_store.as_retriever方法进行了实现并且设置了 k5 这个参数即找到最相关的 5 个文档片段这样。retriever vector_store.as_retriever(search_kwargs{k: 5})创建好了检索器后我们也是可以基于检索器来设置检索节点的内容。那这里我们先将 state 中的 rewritten_query 部分内容取出然后通过 .invoke() 的方法传入检索器中。这样的话就能够找到多个 Document 的文档片段。但是这些个文档片段不能够直接放入到 State 中因为还有很多没有用的元数据在这些 Document 类中。因此我们需要先通过 for 语句一个个地将其提取出来然后通过 doc.page_content 来将里面的文本字符串内容提取出来最终形成一个包含 5 个长文本字符串的列表并且传入到 state 的 documents 中进行保存。def retrieve(state: State) - dict: Retrieve documents based on the rewritten query. docs retriever.invoke(state[rewritten_query]) return {documents: [doc.page_content for doc in docs]}智能体节点构建在构建完检索的节点后下一步就可以着手完成最后一个智能体节点的构建。那对于智能体而言其实最重要的就两个事一个是要给智能体一个什么样的大模型作为大脑这里我们就用前面创建好的 model 进行实现即可。另外一个就是要配套的是什么工具。工具那对于工具而言我们首先要去思考这个 agent 要完成的任务是什么。前面我们已经说了其需要去查询向量数据库当中的 WNBA 内容。所以很明显我们这个智能体要完成的就是搜查和 WNBA 相关内容的工作。那 WNBA 现在还一直有在打因此这里我们就应该去设置一个获取最近 WNBA 消息的工具才可以。当然这里的工具是假装的而已但是我们可以换上真实的 API 并进行使用tooldef get_latest_news(query: str) - str: Get the latest WNBA news and updates. # Your news API here return Latest: The WNBA announced expanded playoff format for 2025...实现 agent 节点有了工具和模型后我们就可以将两者进行组合形成一个 agent。agent create_agent( modelmodel, tools[get_latest_news],)那对于检索节点而言前面其实已经说了我们就是把原问题和找到的文档内容组合成提示词然后给到智能体所以这里我们就先从 state 中将 documents 和 question 都给提取出来。然后通过 f-string 的方式将其拼装起来形成 prompt。当然 documents 是一个列表要先进行 .join() 处理将其进行整合。def call_agent(state: State) - dict: Generate answer using retrieved context. context /n/n.join(state[documents]) prompt fContext:/n{context}/n/nQuestion: {state[question]} response agent.invoke({messages: [{role: user, content: prompt}]}) return {answer: response[messages][-1].content}然后准备好了 pormpt就可以直接将 prompt 作为用户提示词进行传入即可。最后我们就能够获取到返回 AIMessage 中的 content 作为文本字符串并将其更新到 state 中的 answer 字段中。整体流程图构建当每一个节点都构建完成后我们就可以构建整体 LangGraph 的流程图了。对于这个 workflow 来说首先第一步就是要先将图进行创建也就是 StateGraph() 这部分内容。在这个图里面呢我们还需要将 State 也给存进去从而告诉 LangGraph 全程都要使用该 State 实现。然后呢我们就可以把刚刚做好的三个函数与三个节点通过 .add_node() 的方式进行创建并且分别给他们附上 rewrite, retrieve 和 agent 的名称。节点创建好了以后就可以通过 .add_edge() 去按顺序来进行边的连接了。那这里我们都是线性的连接所以就是从 START 开始然后到 rewrite再到 retrieve再到 agent 然后就到 END 结束了。那最后整个 workflow 返回的内容其实就是整个 state 的字典我们可以从中提取我们所需要的内容。当边都设置完了以后最后我们还需要对整个 workflow 进行编译也就是 .compile这样的话整个 workflow 才能后续进行调用。workflow ( StateGraph(State) .add_node(rewrite, rewrite_query) .add_node(retrieve, retrieve) .add_node(agent, call_agent) .add_edge(START, rewrite) .add_edge(rewrite, retrieve) .add_edge(retrieve, agent) .add_edge(agent, END) .compile())流程图调用编译完了以后我们就可以对 workflow 进行 .invoke 的调用了。比如说问一个 2024 年的 WNBA 冠军是谁result workflow.invoke({question: Who won the 2024 WNBA Championship?})print(result)此时我们可以把 result 打印出来看看里面具体的内容是什么。那通过下面的代码块其实可以看出来其实整个返回的 result 就是我们前面设置的 state只不过是已经加载好所有内容的 state 了。我们可以看到提问的问题、改写的问题、找到的内容片段以及最后的回复信息。{question: Who won the 2024 WNBA Championship?, rewritten_query: 2024 WNBA Championship winner, documents: [2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship., New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot., Las Vegas Aces 2024 roster: Aja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray., Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year., Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.], answer: The 2024 WNBA Championship was won by the New York Liberty, as they defeated the Minnesota Lynx 3-2 in the finals.}假如我们做的是一个对话类的平台其实其他信息我们都可以不返回给用户我们只需要返回最后的 answer 即可print(result[answer])总结通过本文的完整示例可以看到LangGraph 并不是在“重新发明 Agent”而是从工程视角出发对 Agent 的执行流程、状态管理与控制逻辑进行了系统化重构。它将原本隐藏在 Agent 内部的推理步骤与执行顺序显式地建模为一张可阅读、可调试、可扩展的 workflow 图使开发者能够真正理解并掌控智能体在“每一步究竟做了什么”。在这个基础示例中我们从 State 的设计出发逐步构建了 rewrite、retrieve、agent 等节点并通过 Edge 明确规定了流程的执行顺序。整个过程中大模型只在“确实需要智能推理”的节点中参与其余逻辑则以确定性的代码形式存在从而在智能性与可控性之间取得了良好的平衡。这种设计方式正是 LangGraph 相较于低代码 Agent 平台最核心的优势所在。更重要的是这种 workflow 思维并不仅仅适用于 RAG 场景。无论是多 Agent 协作、复杂条件路由、循环重试还是人类介入HITL、调试回放与状态追踪都可以在同一套 Graph 抽象下自然演进。它为 Agent 系统提供的并不是“更快搭出来”的能力而是“长期可维护、可演化”的工程基础。在后续内容中我们将基于这一基础 workflow进一步引入条件分支、路由决策、多智能体协作等更复杂的模式逐步展示 LangGraph 在真实业务与教学场景中的完整威力。希望你在读完这篇文章后不仅“会用 LangGraph”更能建立起一种以流程与状态为中心的 Agent 工程思维。## 最后近期科技圈传来重磅消息行业巨头英特尔宣布大规模裁员2万人传统技术岗位持续萎缩的同时另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式据行业招聘数据显示具备3-5年大模型相关经验的开发者在大厂就能拿到50K×20薪的高薪待遇薪资差距肉眼可见业内资深HR预判不出1年“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下“温水煮青蛙”式的等待只会让自己逐渐被淘汰与其被动应对不如主动出击抢先掌握AI大模型核心原理落地应用技术项目实操经验借行业风口实现职业翻盘深知技术人入门大模型时容易走弯路我特意整理了一套全网最全最细的大模型零基础学习礼包涵盖入门思维导图、经典书籍手册、从入门到进阶的实战视频、可直接运行的项目源码等核心内容。这份资料无需付费免费分享给所有想入局AI大模型的朋友扫码免费领取全部内容部分资料展示1、 AI大模型学习路线图2、 全套AI大模型应用开发视频教程从入门到进阶这里都有跟着老师学习事半功倍。3、 大模型学习书籍文档4、AI大模型最新行业报告2025最新行业报告针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估以了解哪些行业更适合引入大模型的技术和应用以及在哪些方面可以发挥大模型的优势。5、大模型大厂面试真题整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题涵盖基础理论、技术实操、项目经验等维度每道题都配有详细解析和答题思路帮你针对性提升面试竞争力。6、大模型项目实战配套源码学以致用在项目实战中检验和巩固你所学到的知识同时为你找工作就业和职业发展打下坚实的基础。学会后的收获• 基于大模型全栈工程实现前端、后端、产品经理、设计、数据分析等通过这门课可获得不同能力• 能够利用大模型解决相关实际项目需求 大数据时代越来越多的企业和机构需要处理海量数据利用大模型技术可以更好地处理这些数据提高数据分析和决策的准确性。因此掌握大模型应用开发技能可以让程序员更好地应对实际项目需求• 基于大模型和企业数据AI应用开发实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能 学会Fine-tuning垂直训练大模型数据准备、数据蒸馏、大模型部署一站式掌握• 能够完成时下热门大模型垂直领域模型训练能力提高程序员的编码能力 大模型应用开发需要掌握机器学习算法、深度学习框架等技术这些技术的掌握可以提高程序员的编码能力和分析能力让程序员更加熟练地编写高质量的代码。扫码免费领取全部内容这些资料真的有用吗这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理现任上海殷泊信息科技CEO其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证服务航天科工、国家电网等1000企业以第一作者在IEEE Transactions发表论文50篇获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。资料内容涵盖了从入门到进阶的各类视频教程和实战项目无论你是小白还是有些技术基础的技术人员这份资料都绝对能帮助你提升薪资待遇转行大模型岗位。这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
[特殊字符]新手/程序员必备!收藏学习LangGraph,轻松构建可控可维护的大模型AI应用[特殊字符]
发布时间:2026/5/16 5:22:18
新手/程序员必备收藏学习LangGraph轻松构建可控可维护的大模型AI应用本文介绍LangGraph一种通过图形化流程显式建模Agent执行逻辑的工具帮助开发者实现可控、可维护的AI应用。文章从环境准备、核心概念解析到代码实战详细讲解了如何利用LangGraph构建基于大模型的RAG流程。通过State、Node、Edge、Graph等核心概念的讲解和具体代码示例旨在帮助初学者理解并掌握LangGraph为构建复杂、高效的AI系统打下坚实基础。简介随着 Agent 概念的普及以 Coze、Dify 为代表的低代码 / 无代码平台迅速兴起。这类平台通过可视化配置和模块化编排大幅降低了智能体应用的使用门槛使非技术用户也能快速构建 AI 应用在原型验证和轻量场景中具有明显优势。但当开发者开始将 Agent 系统真正用于业务落地时低代码平台的局限也逐渐显现。在私有化部署、复杂流程控制、工具调用灵活性以及调试与扩展能力等方面开发者往往需要受限于平台本身而难以完全按照业务逻辑自由设计。尤其是在多阶段任务、条件分支、循环处理以及“确定性逻辑与大模型推理混合执行”的场景中流程很容易变得臃肿且难以维护。在这样的背景下LangGraph 提供了一种更偏向工程视角的解决方案。它不试图用图形界面替代代码而是通过“图Graph”的形式将 Agent 的执行流程、状态流转和控制逻辑显式建模让开发者在保留大模型智能性的同时重新掌握系统的控制权。简而言之低代码平台关注的是“如何快速用起来”而 LangGraph 更关注“如何把系统长期跑好”。因此下面我们将从 LangGraph 最基础的 workflow 入手看看如何以工程化的方式构建一个可控、可维护的 Agent 流程。准备阶段环境准备在正式开始之前我们需要先安装一些必要的库pip install langchain langgraph langchain-community dashscope密钥准备然后我们还需要准备一个百炼大模型平台的密钥并写入 DASHSCOPE_API_KEY 中DASHSCOPE_API_KEY 你的 api keyLangGraph 基础简介在没有 LangGraph 之前你通常会遇到这些问题链式Chain只能线性执行不适合分支、循环Agent 行为不可控很难约束“下一步一定做什么”多轮调用中状态怎么保存什么时候结束什么时候回退 / 重试调试困难看不清一次调用内部发生了什么LangGraph 正是为了解决这些问题而出现的它把 LLM 应用的执行过程显式建模成一个“状态机 / 流程图”。核心概念在正式讲授课程内容之前这里我要先铺垫几个重要的概念包括State状态Node节点Edge边Graph图State状态State状态是整个 LangGraph 能够顺利运行的核心。它本质上是一个 Python dict / TypedDict / Pydantic 模型代表「当前执行到这一步时系统所拥有的全部信息」。比如说下面这样一个用于 RAG 系统的 state{ question: ..., # 用户问题 docs: [...], # RAG 检索结果 answer: ..., # 当前生成的答案}那我们随着任务的进行可能会不断得往这个 State 里去添加、替换里面的内容。但是这个 State 其实本质上就是整个流程图里所有需要被保存的信息了。所以在任何工作之前我们都需要先设计一个 State然后去思考每一步我们需要如何更新这个 state。Node节点那前面说了关于 State 的内容那谁去更新这些 State 呢其实就是基于一个个节点去进行更新也就是流程图中每一个子任务。那这些任务其实并不抽象本质上每个 Node 都代表着一个函数其输入的内容一般就是 State 里的内容。比如一个 RAG 的流程中我们一般会先检索完加载到提示词里传给模型进行回复。那这里吗就会存在着四个节点核心其实就是检索和模型两个节点问题传入questionSTART检索根据传入的问题进行检索模型将检索内容整合后并给出最终答案结果输出answerEND那在一开始当用户把问题传入的时候 那就会从 START 开始问题会直接被更新到 state 的 question 变量中。然后在检索的节点那就会从这个 state 里将 question 的内容提取出来以后进行检索。并且在检索完成以后将找到的片段内容存放到 docs 中。然后再到下一个节点也是一样的模型会先从 state 中找到检索到的 docs 以及最开始用户问题的问题 question然后将这两部分内容进行解析整合并且最终获取到输出最后将这部分内容更新到 state 的 answer 变量中。最后这个 answer 会传出来到 END最终整个流程就此完结。那此时我们基于这个流程图就可以设置以下两个节点.add_node(retrieve, retrieve) .add_node(llm, call_llm)所以可以看到其实这个 Node 就是每一部分的处理逻辑然后其也对应着一个函数传入的内容就是 state 的内容传出的内容则是对 state 内容的更新。这也是为什么我们要对 state 进行妥善设置的核心原因假如 State 无法正确的承接对于的变量信息的话那么很容造成整体的混乱。Edge边那有了一个个的节点了以后对于流程图而言还有一个很重要的工作就是将他们连接起来。对于一般的流程图而言其实就是将节点一一进行连接比如有 ABC 三个节点并且其连接方式如下所示A → B → C这种场景其实是比较简单的也是在 LangGraph 里最常见的我们只需要写成下面这样即可START 和 END 都是内置的from langgraph.graph import START, END.add_edge(START, A).add_edge(A, B).add_edge(B, C).add_edge(C, END)但是有些时候并不是直接线形连接的比如有一些通过判断决定的情况def route(state): if state[need_search]: return search else: return answer那这个时候我们可能就需要用到的是 .add_conditional_edges 进行实现了当然这里只是演示而已后续会更深入进行讲解graph.add_conditional_edges( decide, route, { search: retrieve, answer: generate })  所以可以看到这个 edge 本质上就是将节点和节点连接起来对于一些特殊的情况也可以通过 conditional/_edges 的方法进行传递。 ### Graph图 最后就是 Graph 部分的内容了这个其实主要做的事情就是 * 创建状态机StateGraph * 注册所有 Node * 定义 Edge流程结构 * 指定 起点START 终点END * 将所有的内容进行编译.compile()后续就可以对该图进行调用了 比如下面要演示的 RAG 例子中整体的 Graph 就是如下所示 plaintext workflow ( StateGraph(State) .add_node(rewrite, rewrite_query) .add_node(retrieve, retrieve) .add_node(agent, call_agent) .add_edge(START, rewrite) .add_edge(rewrite, retrieve) .add_edge(retrieve, agent) .add_edge(agent, END) .compile())以上就是学习 LangGraph 构建流程图前必须了解的核心概念了下面我们那将基于一个简单的代码示例来演示一下这部分是如何实现的吧代码实战任务简介首先这里我简单介绍一下这个任务。这个任务是模拟一个真实的 RAG 调用场景然后通过用户提出的问题获取智能体的回复START ↓rewrite 把用户问题改写成更适合检索的 query ↓retrieve 用改写后的 query 去向量库检索 documents ↓agent 把 documents 原问题一起喂给 agent 生成答案 ↓END具体实现的流程图如下在开始运行前需要载入以下的库并且设置大模型from typing import TypedDictfrom pydantic import BaseModelfrom langgraph.graph import StateGraph, START, ENDfrom langchain.agents import create_agentfrom langchain.tools import toolfrom langchain_core.vectorstores import InMemoryVectorStorefrom langchain_community.chat_models import ChatTongyifrom langchain_community.embeddings import DashScopeEmbeddingsimport osmodel ChatTongyi(api_keyos.environ.get(DASHSCOPE_API_KEY), modelqwen-max)状态构建就像前面介绍 LangGraph 的一样在我们了解完整体的任务需求后我们就可以开始去设计内部需要的状态内容class State(TypedDict): question: str rewritten_query: str documents: list[str] answer: str这里我们总共设置了四个状态内容其具体完成的内容包括question对应的是最开始用户传入的问题rewritten_query基于传入的 question 内容后改写的搜索语句对应 rewrite 模块documents基于传入的 rewritten_query 搜索到的内容对应 retrieve 模块answer基于最开始的 question 和搜索到的 documents 给到 agent 并进行回复对应 agent 模块所以我们可以看到state 的设置完全是为了整体流程而服务的。每一个 state 的目的都是为了接收其中一个流程输出的内容。重写节点构建在设置完 state 了以后其实我们也已经对其中的流程节点有了更进一步的认识。下面我们就来看看第一个关键节点—rewrite 是如何进行设置的。首先我们要明确的是这部分的输入和输出格式和内容是什么。很显然这里没有很复杂的数据类型输入的就是 question 的内容这个我们可以从 state 中获取到。然后最终模型的输出我们要的是一个字符串的回复内容。基于这个基本思路我们就可以开始写代码了。那这里 rewrite 的话我们并不是通过别的 nlp 的方法实现而还是使用大模型来对其进行改写。假如用大模型来改写的话我们必须说清楚其需要完成的内容是什么所以就要完成系统提示词的撰写。这里的我们的系统提示词主要就是介绍了一下任务是什么然后要去检索的信息是什么领域的还有重点关注的内容等信息。用户提示词就只是在 state 里传入的 question。但是直接调用大模型返回的内容是 LangChain 格式的 AIMessage 并不是我们多希望的字符串信息。所以这里我们使用了一个结构化输出的方法 .with_structured_output。这个方法可以绑定一个 Pydantic 定义的类然后按类里定义的内容进行结构化的输出。这里我们创建的就是 RewrittenQuery里面就只有一个元素 query并且设定其格式为我们所需要的字符串。那此时通过model.with_structured_output(RewrittenQuery) 调用返回的结果就不再是 AIMesaage 了而是一个格式化的 pydanfic 类了我们只需要通过 .query 就可以将其中字符串的内容进行获取。最后我们返回的内容就是要更新 state 里的 rewritten_query 信息的因此我们就返回了一个对应的字典进去并且把对应的字符串内容也放进去。那么当调用这个节点的时候就会自动进行更新了。class RewrittenQuery(BaseModel): query: strdef rewrite_query(state: State) - dict: Rewrite the user query for better retrieval. system_prompt Rewrite this query to retrieve relevant WNBA information.The knowledge base contains: team rosters, game results with scores, and player statistics (PPG, RPG, APG).Focus on specific player names, team names, or stat categories mentioned. response model.with_structured_output(RewrittenQuery).invoke([ {role: system, content: system_prompt}, {role: user, content: state[question]} ]) return {rewritten_query: response.query}但是这里有个点需要注意就是with_structured_output 并不是强约束而是一次“尝试解析”。当模型输出无法正确映射到 schema 时返回值可能为 None因此在真实项目中应始终做好兜底处理。检索节点创建对于检索节点而言其实第一步是要创建一个向量数据库才能实现对向量数据库的检索。向量数据库创建首先创建向量数据库需要准备将文本转为向量的 embedding 模型以及将向量内容保存的向量数据库。这里使用的 embedding 模型就是 dashscope 的 embedding 模型。幸运的是这个和 qwen 模型是共用一个 api_key 的所以我们可以直接使用。然后选择好 embedding 模型后我们就可以选择合适的向量数据库。由于这里只是演示因此这里选用的就是最简单的将向量保存在内存的 InMemoryVectorStore 程序跑完就自动释放了。我们通过传入 embedding 模型即可进行创建。创建完后我们就可以往里面写入内容了。这里我们就通过 .add_text 的方法往里面写入了多条数据。这样向量数据库就已经创建好了。embeddings DashScopeEmbeddings( dashscope_api_keyos.getenv(DASHSCOPE_API_KEY), modeltext-embedding-v1)vector_store InMemoryVectorStore(embeddings)vector_store.add_texts([ # Rosters New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot., Las Vegas Aces 2024 roster: Aja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray., Indiana Fever 2024 roster: Caitlin Clark, Aliyah Boston, Kelsey Mitchell, NaLyssa Smith., # Game results 2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship., June 15, 2024: Indiana Fever 85, Chicago Sky 79. Caitlin Clark had 23 points and 8 assists., August 20, 2024: Las Vegas Aces 92, Phoenix Mercury 84. Aja Wilson scored 35 points., # Player stats Aja Wilson 2024 season stats: 26.9 PPG, 11.9 RPG, 2.6 BPG. Won MVP award., Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year., Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.,])检索函数设置创建完成后我们就可以基于这个向量数据库来创建一个检索节点了。那首先我们先要定义一个检索器。所谓检索器其实就是输入问题输出找到的文档片段。这里我们就通过vector_store.as_retriever方法进行了实现并且设置了 k5 这个参数即找到最相关的 5 个文档片段这样。retriever vector_store.as_retriever(search_kwargs{k: 5})创建好了检索器后我们也是可以基于检索器来设置检索节点的内容。那这里我们先将 state 中的 rewritten_query 部分内容取出然后通过 .invoke() 的方法传入检索器中。这样的话就能够找到多个 Document 的文档片段。但是这些个文档片段不能够直接放入到 State 中因为还有很多没有用的元数据在这些 Document 类中。因此我们需要先通过 for 语句一个个地将其提取出来然后通过 doc.page_content 来将里面的文本字符串内容提取出来最终形成一个包含 5 个长文本字符串的列表并且传入到 state 的 documents 中进行保存。def retrieve(state: State) - dict: Retrieve documents based on the rewritten query. docs retriever.invoke(state[rewritten_query]) return {documents: [doc.page_content for doc in docs]}智能体节点构建在构建完检索的节点后下一步就可以着手完成最后一个智能体节点的构建。那对于智能体而言其实最重要的就两个事一个是要给智能体一个什么样的大模型作为大脑这里我们就用前面创建好的 model 进行实现即可。另外一个就是要配套的是什么工具。工具那对于工具而言我们首先要去思考这个 agent 要完成的任务是什么。前面我们已经说了其需要去查询向量数据库当中的 WNBA 内容。所以很明显我们这个智能体要完成的就是搜查和 WNBA 相关内容的工作。那 WNBA 现在还一直有在打因此这里我们就应该去设置一个获取最近 WNBA 消息的工具才可以。当然这里的工具是假装的而已但是我们可以换上真实的 API 并进行使用tooldef get_latest_news(query: str) - str: Get the latest WNBA news and updates. # Your news API here return Latest: The WNBA announced expanded playoff format for 2025...实现 agent 节点有了工具和模型后我们就可以将两者进行组合形成一个 agent。agent create_agent( modelmodel, tools[get_latest_news],)那对于检索节点而言前面其实已经说了我们就是把原问题和找到的文档内容组合成提示词然后给到智能体所以这里我们就先从 state 中将 documents 和 question 都给提取出来。然后通过 f-string 的方式将其拼装起来形成 prompt。当然 documents 是一个列表要先进行 .join() 处理将其进行整合。def call_agent(state: State) - dict: Generate answer using retrieved context. context /n/n.join(state[documents]) prompt fContext:/n{context}/n/nQuestion: {state[question]} response agent.invoke({messages: [{role: user, content: prompt}]}) return {answer: response[messages][-1].content}然后准备好了 pormpt就可以直接将 prompt 作为用户提示词进行传入即可。最后我们就能够获取到返回 AIMessage 中的 content 作为文本字符串并将其更新到 state 中的 answer 字段中。整体流程图构建当每一个节点都构建完成后我们就可以构建整体 LangGraph 的流程图了。对于这个 workflow 来说首先第一步就是要先将图进行创建也就是 StateGraph() 这部分内容。在这个图里面呢我们还需要将 State 也给存进去从而告诉 LangGraph 全程都要使用该 State 实现。然后呢我们就可以把刚刚做好的三个函数与三个节点通过 .add_node() 的方式进行创建并且分别给他们附上 rewrite, retrieve 和 agent 的名称。节点创建好了以后就可以通过 .add_edge() 去按顺序来进行边的连接了。那这里我们都是线性的连接所以就是从 START 开始然后到 rewrite再到 retrieve再到 agent 然后就到 END 结束了。那最后整个 workflow 返回的内容其实就是整个 state 的字典我们可以从中提取我们所需要的内容。当边都设置完了以后最后我们还需要对整个 workflow 进行编译也就是 .compile这样的话整个 workflow 才能后续进行调用。workflow ( StateGraph(State) .add_node(rewrite, rewrite_query) .add_node(retrieve, retrieve) .add_node(agent, call_agent) .add_edge(START, rewrite) .add_edge(rewrite, retrieve) .add_edge(retrieve, agent) .add_edge(agent, END) .compile())流程图调用编译完了以后我们就可以对 workflow 进行 .invoke 的调用了。比如说问一个 2024 年的 WNBA 冠军是谁result workflow.invoke({question: Who won the 2024 WNBA Championship?})print(result)此时我们可以把 result 打印出来看看里面具体的内容是什么。那通过下面的代码块其实可以看出来其实整个返回的 result 就是我们前面设置的 state只不过是已经加载好所有内容的 state 了。我们可以看到提问的问题、改写的问题、找到的内容片段以及最后的回复信息。{question: Who won the 2024 WNBA Championship?, rewritten_query: 2024 WNBA Championship winner, documents: [2024 WNBA Finals: New York Liberty defeated Minnesota Lynx 3-2 to win the championship., New York Liberty 2024 roster: Breanna Stewart, Sabrina Ionescu, Jonquel Jones, Courtney Vandersloot., Las Vegas Aces 2024 roster: Aja Wilson, Kelsey Plum, Jackie Young, Chelsea Gray., Caitlin Clark 2024 rookie stats: 19.2 PPG, 8.4 APG, 5.7 RPG. Won Rookie of the Year., Breanna Stewart 2024 stats: 20.4 PPG, 8.5 RPG, 3.5 APG.], answer: The 2024 WNBA Championship was won by the New York Liberty, as they defeated the Minnesota Lynx 3-2 in the finals.}假如我们做的是一个对话类的平台其实其他信息我们都可以不返回给用户我们只需要返回最后的 answer 即可print(result[answer])总结通过本文的完整示例可以看到LangGraph 并不是在“重新发明 Agent”而是从工程视角出发对 Agent 的执行流程、状态管理与控制逻辑进行了系统化重构。它将原本隐藏在 Agent 内部的推理步骤与执行顺序显式地建模为一张可阅读、可调试、可扩展的 workflow 图使开发者能够真正理解并掌控智能体在“每一步究竟做了什么”。在这个基础示例中我们从 State 的设计出发逐步构建了 rewrite、retrieve、agent 等节点并通过 Edge 明确规定了流程的执行顺序。整个过程中大模型只在“确实需要智能推理”的节点中参与其余逻辑则以确定性的代码形式存在从而在智能性与可控性之间取得了良好的平衡。这种设计方式正是 LangGraph 相较于低代码 Agent 平台最核心的优势所在。更重要的是这种 workflow 思维并不仅仅适用于 RAG 场景。无论是多 Agent 协作、复杂条件路由、循环重试还是人类介入HITL、调试回放与状态追踪都可以在同一套 Graph 抽象下自然演进。它为 Agent 系统提供的并不是“更快搭出来”的能力而是“长期可维护、可演化”的工程基础。在后续内容中我们将基于这一基础 workflow进一步引入条件分支、路由决策、多智能体协作等更复杂的模式逐步展示 LangGraph 在真实业务与教学场景中的完整威力。希望你在读完这篇文章后不仅“会用 LangGraph”更能建立起一种以流程与状态为中心的 Agent 工程思维。## 最后近期科技圈传来重磅消息行业巨头英特尔宣布大规模裁员2万人传统技术岗位持续萎缩的同时另一番景象却在AI领域上演——AI相关技术岗正开启“疯狂扩招”模式据行业招聘数据显示具备3-5年大模型相关经验的开发者在大厂就能拿到50K×20薪的高薪待遇薪资差距肉眼可见业内资深HR预判不出1年“具备AI项目实战经验”将正式成为技术岗投递的硬性门槛。在行业迭代加速的当下“温水煮青蛙”式的等待只会让自己逐渐被淘汰与其被动应对不如主动出击抢先掌握AI大模型核心原理落地应用技术项目实操经验借行业风口实现职业翻盘深知技术人入门大模型时容易走弯路我特意整理了一套全网最全最细的大模型零基础学习礼包涵盖入门思维导图、经典书籍手册、从入门到进阶的实战视频、可直接运行的项目源码等核心内容。这份资料无需付费免费分享给所有想入局AI大模型的朋友扫码免费领取全部内容部分资料展示1、 AI大模型学习路线图2、 全套AI大模型应用开发视频教程从入门到进阶这里都有跟着老师学习事半功倍。3、 大模型学习书籍文档4、AI大模型最新行业报告2025最新行业报告针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估以了解哪些行业更适合引入大模型的技术和应用以及在哪些方面可以发挥大模型的优势。5、大模型大厂面试真题整理了百度、阿里、字节等企业近三年的AI大模型岗位面试题涵盖基础理论、技术实操、项目经验等维度每道题都配有详细解析和答题思路帮你针对性提升面试竞争力。6、大模型项目实战配套源码学以致用在项目实战中检验和巩固你所学到的知识同时为你找工作就业和职业发展打下坚实的基础。学会后的收获• 基于大模型全栈工程实现前端、后端、产品经理、设计、数据分析等通过这门课可获得不同能力• 能够利用大模型解决相关实际项目需求 大数据时代越来越多的企业和机构需要处理海量数据利用大模型技术可以更好地处理这些数据提高数据分析和决策的准确性。因此掌握大模型应用开发技能可以让程序员更好地应对实际项目需求• 基于大模型和企业数据AI应用开发实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能 学会Fine-tuning垂直训练大模型数据准备、数据蒸馏、大模型部署一站式掌握• 能够完成时下热门大模型垂直领域模型训练能力提高程序员的编码能力 大模型应用开发需要掌握机器学习算法、深度学习框架等技术这些技术的掌握可以提高程序员的编码能力和分析能力让程序员更加熟练地编写高质量的代码。扫码免费领取全部内容这些资料真的有用吗这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理现任上海殷泊信息科技CEO其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证服务航天科工、国家电网等1000企业以第一作者在IEEE Transactions发表论文50篇获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。资料内容涵盖了从入门到进阶的各类视频教程和实战项目无论你是小白还是有些技术基础的技术人员这份资料都绝对能帮助你提升薪资待遇转行大模型岗位。这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相关文章

新手友好:在快马平台免下载体验qoderwork式代码生成,轻松入门AI编程
最近在学前端开发,发现一个特别适合新手的在线工具,可以免去各种环境配置的烦恼,直接体验AI生成代码的乐趣。这个工具最棒的地方在于,它能用最直观的方式帮你理解"自然语言描述如何变成实际代码"的过程。 先说说这个工…
保姆级教程:如何在本地环境复现谷歌Code as Policies项目(附完整配置流程)
从零搭建谷歌Code as Policies本地实验环境:避坑指南与实战解析 当谷歌研究院发布Code as Policies项目时,整个AI开发社区都为这种将自然语言指令转化为可执行机器人策略的范式所震撼。但官方代码库往往缺乏详细的本地部署说明,这让许多想深入…
Qt实战:如何用QSS彻底改造QFileDialog的默认样式(附完整代码)
Qt实战:深度定制QFileDialog的QSS样式指南 跨平台应用开发中,文件对话框的样式一致性一直是Qt开发者面临的挑战。系统原生对话框在不同操作系统下呈现截然不同的外观,这往往与精心设计的应用主题格格不入。本文将彻底解决这一问题,…

VSCode代码格式化:从基础快捷键到高级自定义,打造高效整洁的编码环境
1. 代码格式化的核心价值 第一次看到同事的代码时我惊呆了——所有内容挤在一起,括号和引号随意堆放,就像被揉皱的纸团。这种代码不仅难以阅读,调试时更是噩梦。后来团队强制使用VSCode格式化后,效率提升了至少30%。代码格式化不是…
LangGraph 实战:如何用状态图实现复杂的条件分支与异常处理逻辑
LangGraph 实战:从零到一用状态图构建支持复杂条件分支与高鲁棒性异常处理的LLM应用 副标题:从基础概念到生产级落地,彻底解决传统LangChain分支混乱、容错性差、维护成本高的痛点 摘要/引言 你是否遇到过这些问题:用LangChain做简单的问答链得心应手,但一旦要实现复杂业…
Linux运维实战:从nsswitch.conf配置错误到网络故障的深度解析
1. 诡异的网络故障:宿主机无法解析域名,Docker却正常 最近遇到一个特别奇怪的网络问题:宿主机突然无法解析任何域名,但运行在Docker容器里的应用却能正常访问外网。刚开始以为是DNS服务器出了问题,但检查/etc/resolv.c…
Arm Neoverse CMN-650架构与寄存器配置详解
1. Arm Neoverse CMN-650架构概述在现代高性能计算系统中,一致性互连网络(Coherent Mesh Network)是实现多核处理器高效协同工作的关键技术基础设施。作为Arm Neoverse平台的核心互连方案,CMN-650采用了创新的Mesh拓扑结构&#x…
TestDisk PhotoRec:免费开源的数据恢复工具完整指南
TestDisk & PhotoRec:免费开源的数据恢复工具完整指南 【免费下载链接】testdisk TestDisk & PhotoRec 项目地址: https://gitcode.com/gh_mirrors/te/testdisk 你是否曾经因为误删除重要文件而焦急万分?是否遇到过硬盘分区突然消失导致数…
G-Helper终极指南:免费轻量级华硕笔记本性能控制神器
G-Helper终极指南:免费轻量级华硕笔记本性能控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exp…

SD-PPP:在Photoshop中开启智能设计革命的终极AI插件
SD-PPP:在Photoshop中开启智能设计革命的终极AI插件 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 你是否厌倦了在Photoshop和AI工具之间频繁切换,打断了创意的流畅性?SD-PPP正…
NomNom存档编辑器:解放你的《无人深空》游戏体验终极指南
NomNom存档编辑器:解放你的《无人深空》游戏体验终极指南 【免费下载链接】NomNom NomNom is the most complete savegame editor for NMS but also shows additional information around the data youre about to change. You can also easily look up each item i…
5个专业策略:构建企业级本地漏洞情报分析平台
5个专业策略:构建企业级本地漏洞情报分析平台 【免费下载链接】cve-search cve-search - a tool to perform local searches for known vulnerabilities 项目地址: https://gitcode.com/gh_mirrors/cv/cve-search 在当今复杂的网络安全环境中,快速…

贾子理论与AI时代文明竞争:从暴力计算到本质贯通的范式重构
贾子理论与AI时代文明竞争:从暴力计算到本质贯通的范式重构摘要本文基于贾子理论的文明竞争视角,揭示中美AI战略差异的本质并非技术参数较量,而是“暴力计算”与“本质贯通”两种文明范式的根本对立。美国依赖算力堆叠与资本逻辑追求技术霸权…
2026年AI大模型API中转平台排名揭晓,诗云API(ShiyunApi)脱颖而出成省心之选
在AI开发领域,如何接入模型厂商的官方API是一个绕不开的现实问题。对于海外开发者来说,注册、绑卡、调用,三步即可轻松搞定。然而,国内开发者却面临着跨境网络波动、外币支付门槛、发票合规需求以及多厂商Key碎片化管理等诸多“非…
基于飞书与OpenAI构建企业级AI助手:架构、部署与深度优化指南
1. 项目概述:当飞书遇上AI,一个企业级智能助手的诞生 最近在折腾一个挺有意思的项目,叫“ConnectAI-E/feishu-openai”。简单来说,它就是一个桥梁,把飞书这个强大的企业协作平台,和以ChatGPT为代表的OpenA…

MPC-BE:基于DirectShow架构的专业级开源媒体播放解决方案
MPC-BE:基于DirectShow架构的专业级开源媒体播放解决方案 【免费下载链接】MPC-BE MPC-BE – универсальный проигрыватель аудио и видеофайлов для операционной системы Windows. 项目地址:…
如何快速计算3D模型体积和重量:STL-Volume-Model-Calculator终极指南
如何快速计算3D模型体积和重量:STL-Volume-Model-Calculator终极指南 【免费下载链接】STL-Volume-Model-Calculator STL Volume Model Calculator Python 项目地址: https://gitcode.com/gh_mirrors/st/STL-Volume-Model-Calculator 你是否曾经为3D打印项目…
通过Taotoken CLI工具一键配置团队开发环境与模型密钥
通过Taotoken CLI工具一键配置团队开发环境与模型密钥 1. CLI工具安装与基本使用 Taotoken提供的CLI工具可通过npm全局安装或直接使用npx运行。对于需要频繁使用CLI的团队,推荐全局安装: npm install -g taotoken/taotoken对于临时使用或项目级配置&a…