 文章分析了Andrej Karpathy提出的两类AI用户差距问题指出理解AI原理对高效使用Agent至关重要。通过9个案例文章深入探讨了Claude Code、OpenClaw等Agent的上下文管理、能力扩展、安全与成本控制等关键技术涉及上下文工程、Subagent使用、Skill动态披露、权限控制、计划模式设计、Prompt Cache优化等内容旨在帮助读者提升AI Agent的使用水平。前言一个多月前Andrej Karpathy 发了一个推说他观察到 timeline 上的人分为两类并且这两类人之间的 gap 越来越大。•第一类低频使用的“白嫖”党“去年不知道在哪使用过免费的 ChatGPT由此形成对 AI 的认知”“嘲笑模型奇怪的回答和幻觉问 AI「我应该走路还是开车去洗车店」之类的问题”付费但无法发挥 Agent 全部能力开通了 SOTA 模型 $200/月的订阅但只用来做搜索、写作、寻求建议•第二类付费并在专业领域做专业的工作看 Agent 快速“融化”原本需要几天甚至几周的工作理解原理才能更好地使用本文将从 9 个具体的 case 出发浅析 Claude Code、OpenClaw 等 Agent harness 所做的 context engineering 工作和源码帮你更好地理解和使用你的 Agent。第一部分 · 上下文管理1. “我纠正了 AI 很多次但它还是不停地犯错…这种情况怎么办”Info场景……长历史上下文用户再写一个函数把数组里的元素累加起来。Agent我会稳稳接住你写了一个map没累加。用户不对是累加应该用reduce。Agent抱歉让我修复语法错了。用户这句根本编译不过……Agent再来一次又错在别处。……用户可能已经在心里或对话里开始骂“你怎么这么笨不应该这样应该那样”所有错误的 pattern都会留在 Agent 的 context list 里例如• 调用一个 tool被用户/权限配置拒绝• 调用一个 tooltool result 是一段报错信息• 输出一段内容被用户纠正• ……LLM 本质是 token in token out。当 context 累积变长模型会感受到 context pressure输出 EoSEnd of Sequence token 的概率提高导致模型能力下降表现为“无法遵循指令”“倾向于输出短句子结束对话”——即模型坍塌Model Collapse。因此当一轮对话中LLM 通过 tool call 试错或人工纠错轮次多了之后无效上下文占据了模型的 context window影响 agent 完成任务的能力。例如想让 Agent 帮我读一篇飞书文档总结核心内容并写入另一篇文档。当发现 LLM 调用了多轮 Fetch / Bash(curl) 工具都无法获取文档内容后就应该及时停止这轮对话新开一个会话。- User: 帮我读一篇飞书文档 xxx总结核心内容并写入另一篇文档。- Agent: 好的我会稳稳接住你。- Tool callFetch(xxx)- Tool resultForbidden- Tool call: Bash(curl xxx)- Tool resultHTTP Code 403……多轮 tool call 试错 及时 stop新开对话 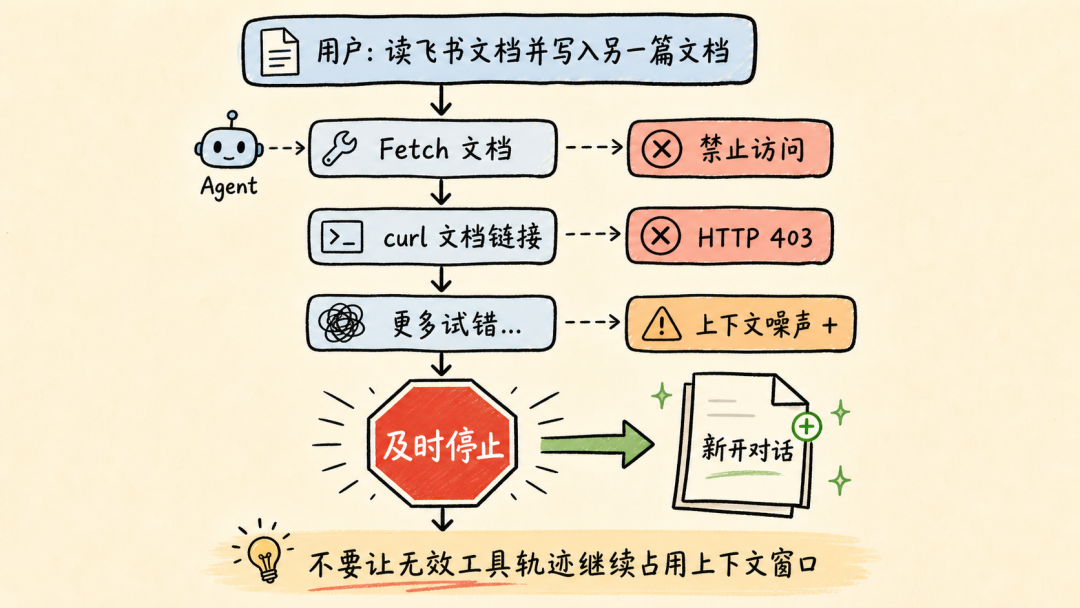 新会话的提示词里直接告诉 Agent“使用 lark-cli 获取一篇飞书文档总结核心内容并写入另一篇文档”。 plaintext - User: 使用 lark-cli 获取一篇飞书文档 xxx总结核心内容并写入另一篇文档。- Agent: 好的我会稳稳接住你。- Tool callBash(which lark-cli lark-cli --version)- Tool resultx.y.z- Tool callBash(lark-cli fetch-doc xxx)- Tool result: xxx……多轮 tool call 完成任务 顺利完成任务 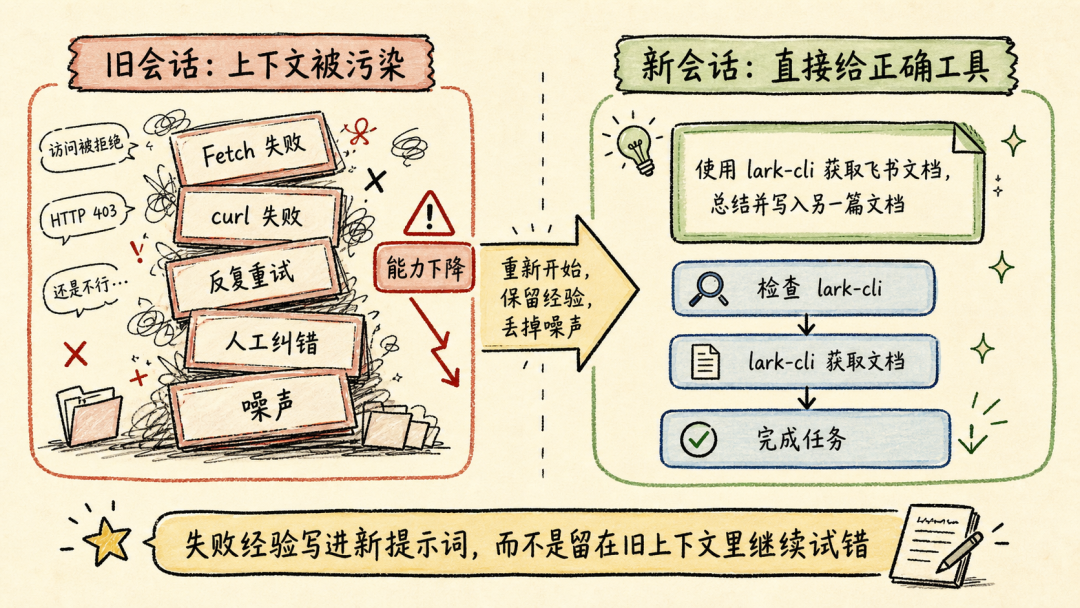 Tip **使用技巧** 1. 1. LLM tool call 试错太多或在对话中多次纠正 Agent 后果断放弃当前对话 2. 2. 新开对话在 prompt 中指定应该使用的工具或禁止不应尝试的路径。 ### ### 2. “我给 OpenClaw 派了不同的任务不同任务之间的上下文会互相影响吗OpenClaw 如何做的上下文隔离” Info **场景** * • 用户在飞书私聊 OpenClaw bot 让它写一份周报任务还没写完又想起来——这周还有个数据要它查和周报没任何关系。两个任务在同一个聊天里会不会互相影响如果过了一两天又新增了一个任务会影响吗 * • 群里 这个 bot 呢 * • 群里有人聊天没 bot但命中了关键词又是另一个会话吗 OpenClaw 通过 peerId、sessionKey 和 sessionId决定上下文如何分割。 * • peerIdIM 渠道侧「这个消息属于哪个聊天/话题/发言人范围」 * • sessionKey会话入口 key内部拼接 peerId一个 sessionKey 可能对应多个 session\_id * • session_id某个会话入口当前指向的实际 message list 文件 ID当 session\_id 过期或使用 /new 命令时生成新的 session\_id 并绑定到对应 sessionKey 上。 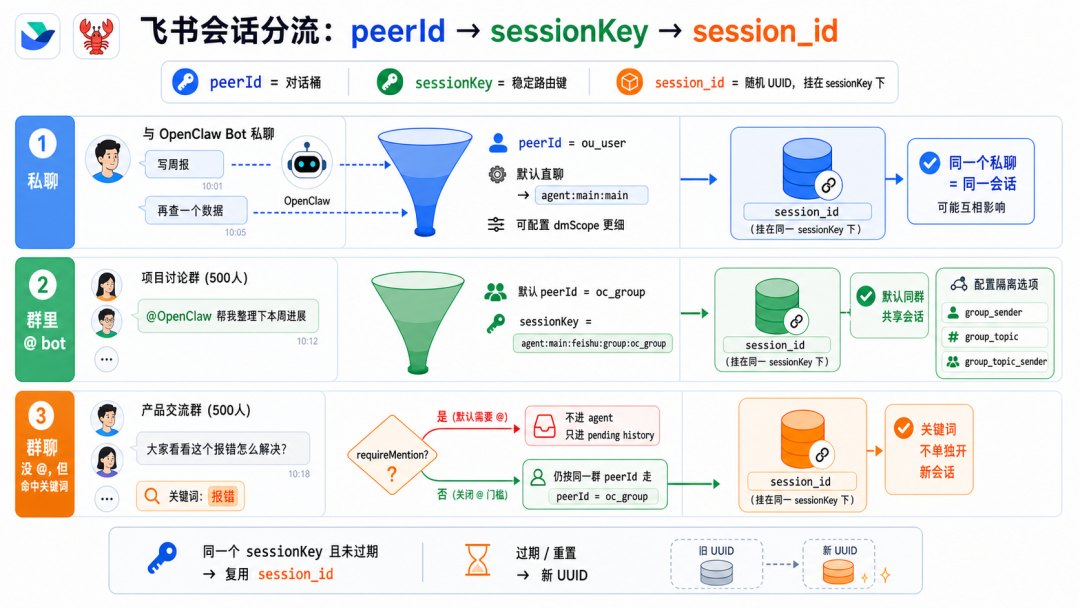 回到场景中的问题。 **私聊 OpenClaw bot 让它写一份周报任务还没写完又想起来——这周还有个数据要它查和周报没任何关系。** 上下文会互相影响。 **过了一两天又新增了一个任务。** OpenClaw 会判断历史的 session\_id 生成时间是否在本地网关时间 4:00 AM 之前。如果跨过了这个重置时间会生成新的 session\_id新消息不会携带历史上下文。 **群里 bot / 群聊命中关键词** 默认同群共享会话可以配置隔离。 | 配置 | 表现 | peerId pattern | | --- | --- | --- | | group\_sender | 按群中的发送人隔离同一个人发送的消息和收到的回复在同一个 context list 中 | chatId:sender:senderOpenId | | group\_topic | 按话题群的 topic 隔离同一个 topic 下的消息在同一个 context list 中 | chatId:topic:topicId | | group\_topic\_sender | 按话题群每个 topic 下的不同发送人隔离 | chatId:topic:topicId:sender:senderOpenId | Tip **使用技巧** 如果有并行任务需要 OpenClaw 处理并且不希望任务之间污染上下文。可以试试**创建一个专门的话题群用不同话题隔离上下文**。  ### ### 3. “Claude Code 和 OpenClaw 是如何‘记住’事情的OpenClaw 的 Dreaming 能力是什么怎么实现的记忆什么时候会被加载进上下文放在哪” Info **场景** * • Claude Code 在代码仓库中使用 npm 安装依赖用户纠正了一次“使用 pnpm”没有写入 CLAUDE.md 和 README.md但 Claude Code 记住了这个要求。 * • OpenClaw 还有个功能叫 **Dreaming**。它会在后台“做梦”然后会发现它的记忆变了。 Claude Code 和 OpenClaw 都用**文件系统**作为长期记忆载体。**模型本身没记忆**只是把需要“记住”的东西写在了 Markdown 文件里。下次对话时加载对应的 Markdown 文件。 **Claude Code 使用 Write/Edit 工具写入 memory分为两个时机** 1. 1. **Agent loop 中写**System prompt 中告诉模型“如果用户明确要求 remember就立即保存”。 2. 2. **后台写**每个完整 loop 结束后stopHook 触发 executeExtractMemories对这一轮 loop 的上下文进行 review更新 memory。 **Claude Code 加载 Memory 分为两层** 1. 1. **System prompt 加载“memory 机制说明”**memory 文件路径、什么时候保存、怎么保存、怎么读。 2. 2. **Memory 内容加载**一轮对话开始时通过 getUserContext函数和 CLAUDE.md 内容一起使用 system-reminder 标签注入 user message 里**memory 内容不会在 system prompt 里**。 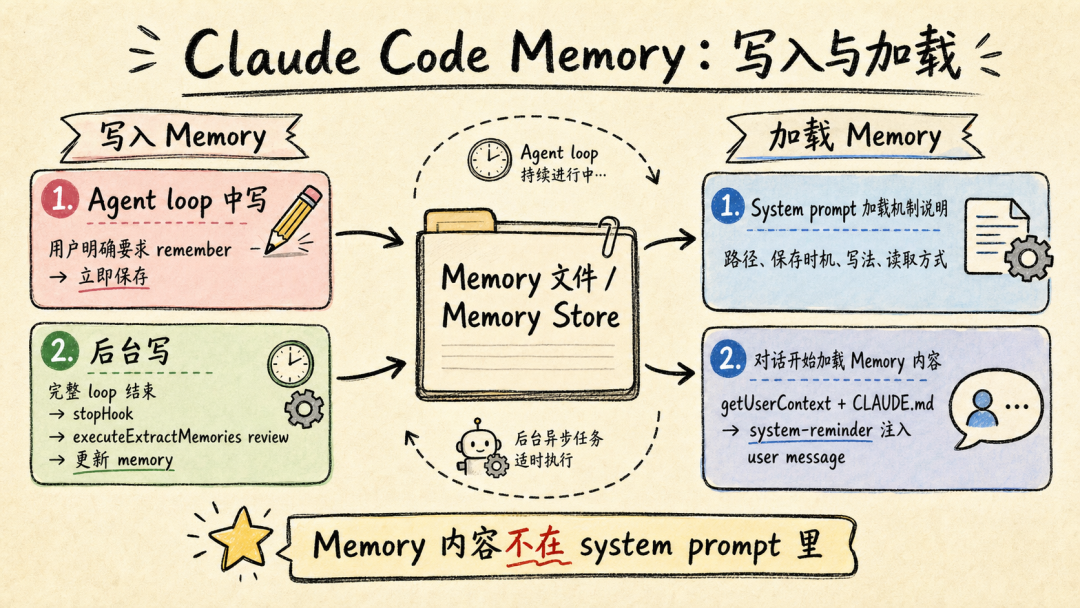 OpenClaw 的 Memory 能力和 Claude Code 类似区别主要有两个 1. 1. 不会在 agent loop 结束后后台跑一个 agent 专门写 memory.md只是在执行过程中写 daily memory 2. 2. MEMORY.md 和 memory.md 会加载进 system prompt但 daily memory 不会。 Dreaming 主要解决这个问题对 daily memory 等文件中的内容做筛选、打分、去重和验证得分高的写入 MEMORY.md后续对话中直接加载进上下文。 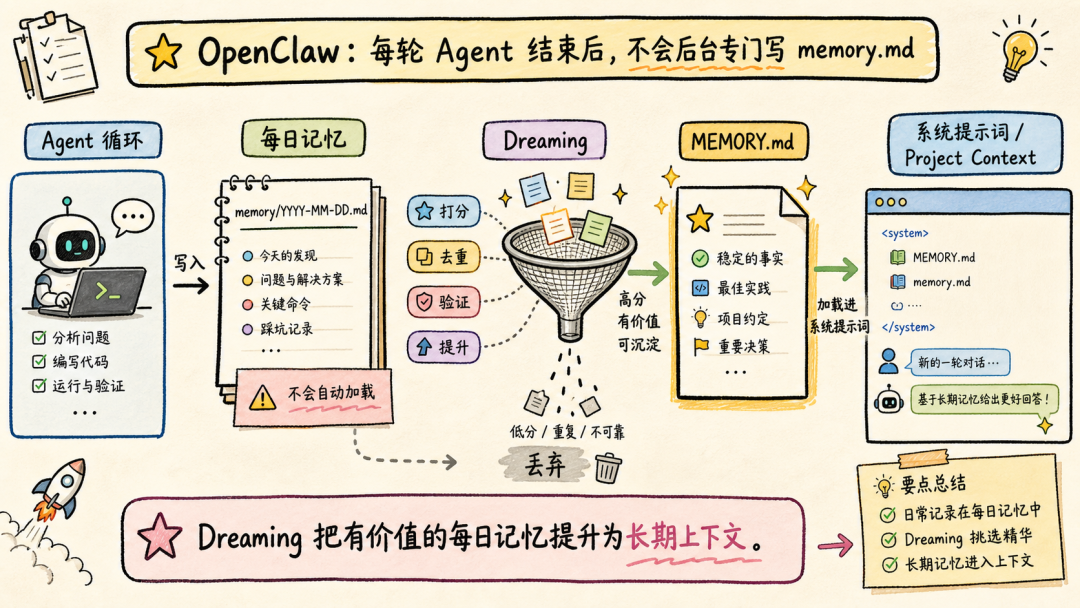 Tip **使用技巧** 1. 1. 定期让 Agent review memory 内容发现错误及时更正避免污染未来上下文。 2. 2. 控制 memory 文件长度只存关键内容保障 agent 工作质量降低 token 成本文章最后会聊 第二部分 · 能力扩展 ----------- ### 4. “什么时候应该用 Subagents / Multi-agents / Agent Teams多 Agent 相比单 Agent 有何优劣” 要理解什么时候应该用 Subagents得先了解多 Agent 之间是怎么传递信息的。 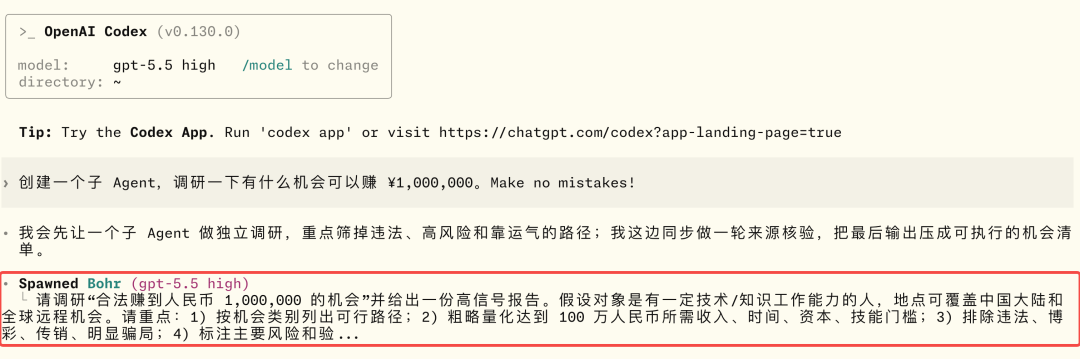 可以看到主 Agent 在启动 Subagent 的时候并不是原封不动的传递用户诉求和主 Agent context list 中的上下文而是**对上下文做总结之后使用自然语言作为 user prompt启动 Subagent**。 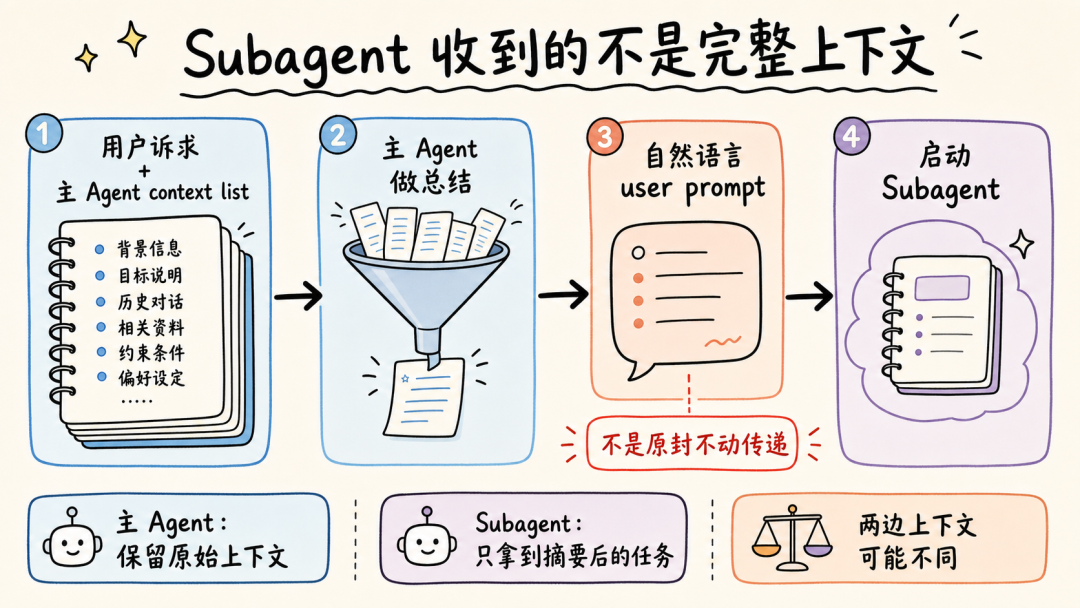 这样做有一个**好处**所有调研过程中Web Search 的 tool call 和 tool result都在 Subagent 的上下文里主 Agent 的上下文不会膨胀。Subagent 只会按照要求告诉主 Agent 调研报告结果。中间被过滤掉的 Web Search 结果**不会污染主 Agent 上下文**。 但显然也有**坏处**这里创建的 Subagent 上下文和主 Agent 原始接收的**上下文出现了不对齐**。 1. 1. 用户并没有说要“合法赚到”手动狗头 2. 2. 用户要求“Make no mistakes!”Subagent 没有“感受到这个压力”。 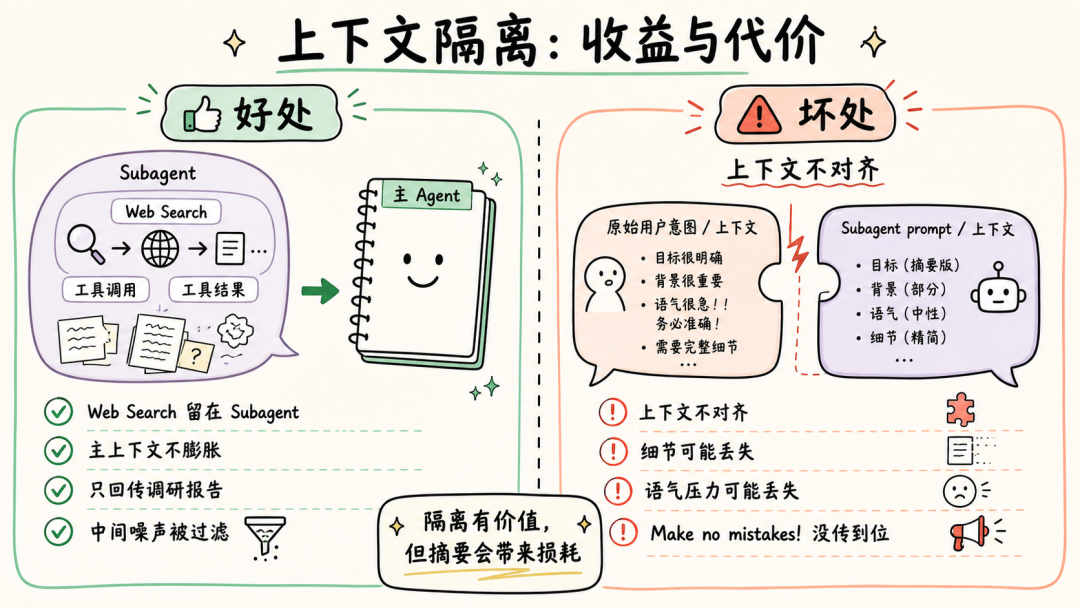 通过这个例子可以理解**决定是否使用 Subagents 完成任务的关键是“上下文是否应该独立”**。 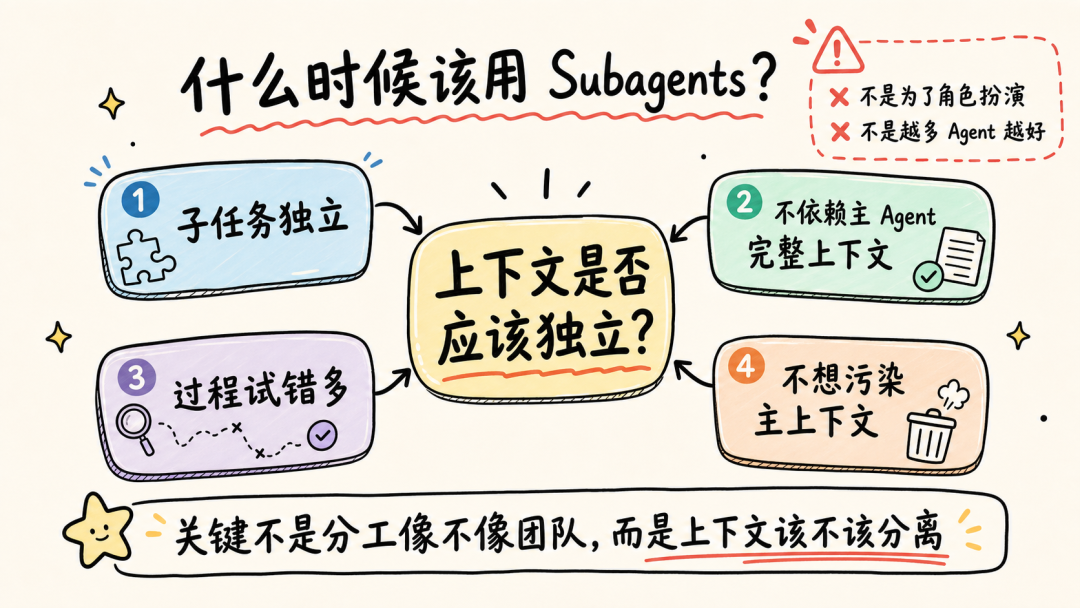 一些常见的反例是用 Subagents 玩“过家家”试图以此提高完成任务的可能性和质量比如让一个“脾气暴躁的 PM Agent”和一个“脾气暴躁的 RD Agent”battle。 * • LLM 并不理解“脾气暴躁”这只是几个额外、无意义的 token甚至可能会影响其他生成的 token影响整体工作质量 * • “过家家”式使用 Subagents还需要承担上下文不对齐的风险。例如一个简单的任务拆分了 PM Agent 和 RD AgentPM Agent 使用自然语言告知 RD Agent 任务时RD Agent 并不完整具备 PM Agent 的完整上下文可能导致最终完成工作的效果甚至不如只使用一个 Agent。 并不是说仿照 PM、RD 角色使用 Subagents 一定不对而是要根据“**上下文是否应该独立**”决定是否使用 Subagents。 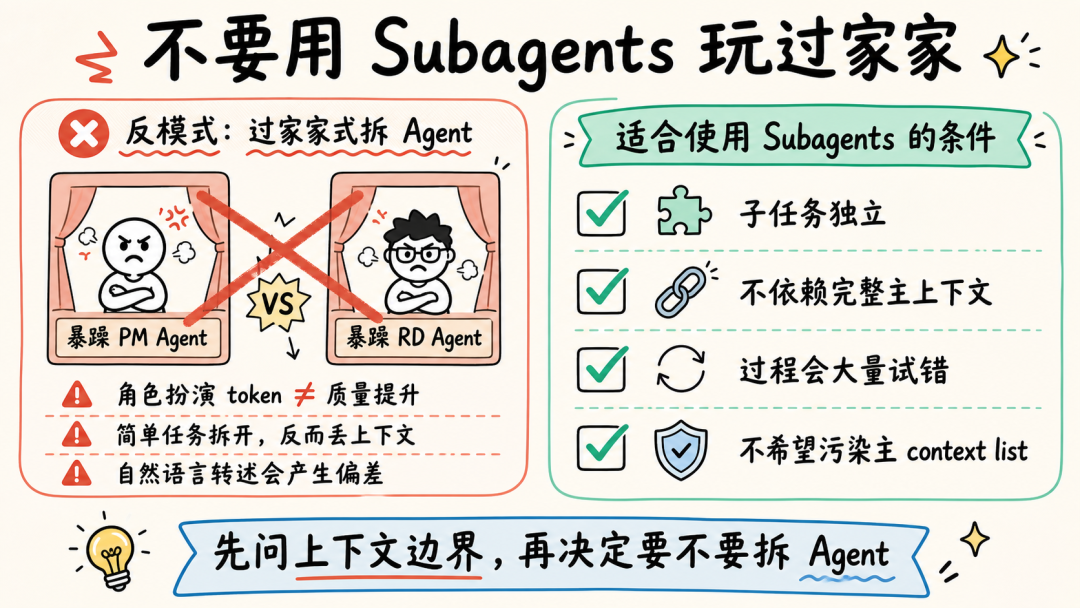 Tip **使用技巧** 在 * • 子任务独立 * • 不依赖主 Agent 完整上下文 * • 已知过程中会有较多“试错”上下文不希望污染主 Agent context list 时使用 Subagents。 ### ### 5. “Skill 的动态披露是怎么做的Claude Code 的 ToolSearchTool 是怎么实现的” Claude Code Skill 的“动态披露”主要是三层机制。 1. 1. **先披露索引不披露全文**启动时会扫描 Skill但给模型的只是 name / description / when\_to\_use 这类 frontmatter 摘要不把整个 SKILL.md 放进上下文。这些索引会放第一条 user prompt 的 system-reminder 标签里告诉 LLM 有哪些可用的 Skill 2. 2. **通过 SkillTool加载 SKILL.md** 3. a. 模型调用 SkillTool 4. b. SkillTool.call() 调 processPromptSlashCommand(...) 5. c. 读取/生成完整 Skill 内容 6. d. SKILL.md 的内容作为一条 user message加载进上下文中 7. 3. **按需使用 FileReadTool加载 references使用 BashTool 执行 scripts**。 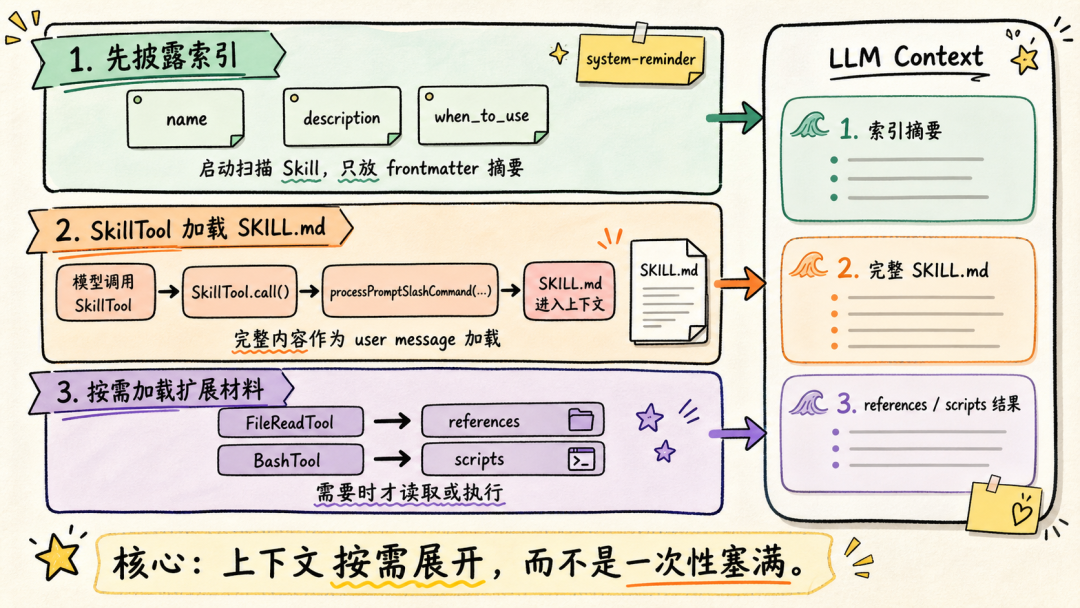 那么 Claude Code 中配置的 MCP Server tool 又是怎么通过 ToolSearchTool 做的动态披露呢  1. 1. 启动工具列表时如果 isToolSearchEnabledOptimistic() 认为可能启用就把 ToolSearchTool 加进基础工具列表 2. 2. **被判定为 deferred 的工具不会一开始完整暴露给模型**isDeferredTool() 规则是 3. a. MCP Server tool 默认 defer 4. b. 普通工具 shouldDefer true 的例如 AskUserQuestionTool、EnterPlanModeTool、TaskCreateTool、CronCreateTool 等会 defer 5. c. 但标记 alwaysLoad 的 tool、以及 ToolSearchTool 自身不 defer 6. 3. API 层只发送非 deferred tool以及历史里已经通过 ToolSearchTool 发现过的 deferred tool需要 API 请求时开启 defer_loading 配置。 这样即使配置了很多 MCP Server tool加上 Claude Code 内置很多 Tool 的情况下不使用到的 Tool 不会预占上下文空间。 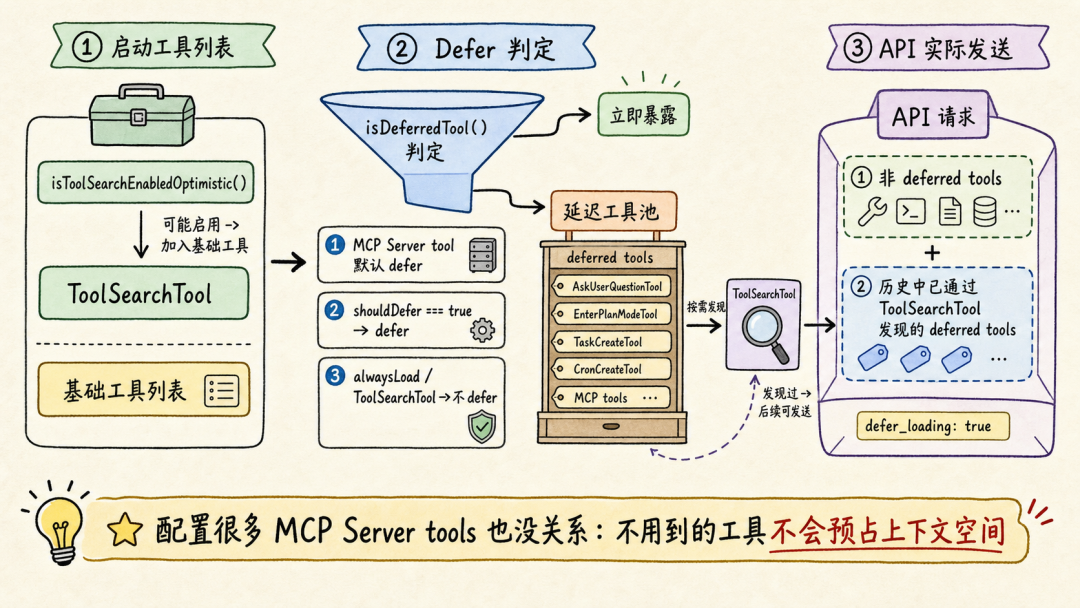 ToolSearchTool 输入只有两个字段query 和可选 max_results。支持两种搜索方式 1. 1. **select:tool_name**精确选择工具支持逗号分隔多选比如 select:A,B,C 2. 2. **关键词搜索**对 deferred 工具的名字、searchHint、完整 tool prompt/description 做打分 3. a. MCP tool name 按 mcp__server__action 拆词普通工具按 CamelCase/下划线拆词 4. b. 名字精确命中权重大MCP 名字命中更高 5. c. searchHint 命中加分 6. d. 工具 prompt/description 命中也加分 7. e. term 表示 required term必须命中才进入候选集。 ToolSearchTool 真正“加载”工具的方式是返回 Anthropic beta 的 tool_reference block若使用其他 LLM Provider需 MaaS 平台支持。匹配到工具后它把结果映射成 plaintext { type: tool_result, content: [ { type: tool_reference, tool_name: name } ]}后续请求会扫描消息历史里的这些 tool_reference提取已发现工具名再把这些工具的完整 schema 加回 tools 数组。Tip使用技巧写 Skill 的 description、when_to_use 时准确告诉 LLM “什么时候应该使用”以及“什么时候不要使用”而不是简单介绍这个 Skill 是做什么的在开发自己的 Agent 时可以支持 ToolSearch tool避免 tool 的描述默认占据大量上下文空间。6. “什么东西应该被沉淀为 Skill如何创建、评估 Skill”Note个人实践仅供参考从上面分析 Skill 加载原理可以看到SKILL.md 的内容其实只是作为 roleuser 的 prompt 内容被加载进了 Agent 上下文中。其本质是一段用户提示词。所以当发现自己重复在使用同一段提示词或发现自己有一些重复的工作需要完成时可以考虑沉淀为 Skill。例如自己希望使用 Seedance 2.0 模型生成视频。通常直接跟 Agent 聊我需求使用/skill-creator创建 Skill。- User/skill-creator 我想使用火山引擎的 Seedance 2.0 模型生成视频使用 AskUserQuestion Tool 明确我的需求并帮我创建这个 skill。- Agent好的我先了解火山引擎的上下文再问你问题明确需求。- Tool callWebSearch(火山引擎 API 文档 2026)- Tool result...……多轮 tool call- Tool callAskUserQuestion(...)- Tool result...……多轮 tool call- Agent我来测试一下这个 skill- Tool callBash(bun /path/to/skill/scripts/generate.ts)- Tool result视频保存至 ...- Agent使用 skill-creator 中的 eval 测试 skill……- Agent测试完成 Skill 创建完成在这个过程中只需要提供一些必要的上下文例如使用的baseURL以及 model ID 等。为了更好解耦 Skill 本身内容和每个用户可能不同的配置内容创建 skill 时在其中说明偏好配置文件位置规则。利用 Agent ReadFile、Bash 能力对 skill 内容进行扩展。提供首次使用 Skill 的引导让用户的 agent 可以协助其完成配置。对于 scripts使用 bun TypeScript 文件有两个好处强类型约束agent 写的脚本代码更不容易犯错使用 bun 代替 NodeJS 做运行时不需要 TS 编译成 JS方便 Agent 维护迭代。看看效果生成一个“老黄”赶空军一号飞机的视频首次使用Agent 引导用户进行配置。配置完成调用 scripts/generate.ts 脚本开始生成。生成视频效果Tip使用技巧先在一轮对话中跑通流程让 Agent 使用 skill-creator 帮你创建 Skill使用 bun TypeScript 写 scripts强类型且不需要编译如果运行报错Agent 知道怎么改利用 LLM 天生喜欢使用 Bash Tool 的特点结合文件系统做动态披露和 Skill 扩展定制使用 skill-creator evaluate Skill并在实际流程中试验迭代 Skill。第三部分 · 安全与成本7. “Claude Code 的 auto permission mode 是怎么实现的为什么同一个 tool call第一次被拦截但告诉 agent 可以操作后就能执行成功”Claude Code 的 auto permission mode 是一个权限判断流水线核心流程如下代码先做普通权限判断显式 deny/ask/allow 规则、tool 自身权限、safety check、mode fast path如果结果是 ask 且当前是 auto代码把当前 tool call 和相关对话历史整理成classifier输入。classifier调 LLM 判断这次 action 是否应该 block。代码解析 LLM 结果并返回 allow 或 deny。如果用户之后明确说“可以操作”这句话进入下一次 classifier 的上下文所以同类 tool call 可能被允许。Tip使用技巧配置allow、ask、deny平衡 Agent loop 自动执行的效率和安全边界例如 allowBash(npm run test:*)denyRead(.env*)askBash(rm -rf:*)使用 auto mode 代替 bypass permission。8. “Claude Code 的 plan mode 是怎么设计的如何防止 Agent 跳过方案设计直接开始写代码”Claude Code 的 plan mode 有三层约束防止 Agent 跳过方案设计直接写代码。层级机制约束效果1Prompt 指令EnterPlanMode 的工具结果里明文写 “DO NOT write or edit any files yet”弱依赖模型遵循指令能力2Tool 的isReadOnly()标志每个工具自己声明只读 vs 会写入中影响模型选择工具3人工确认Plan mode 里尝试 Write 或 Edit 时会要求用户确认是否切换到acceptEdits强permission 代码约束人工确认为什么不直接 hardcode 「plan mode 时 Agent 没有 Write 和 Edit tool」模型需要使用 Write 和 Edit tool 在~/.claude/plans目录下创建和修改 Markdown 文件。Tip使用技巧上下文 200K 时Plan mode 的产出喂给新会话。新会话从一个干净的 context window 开始按一份明确方案执行比“在 plan 会话里直接 ExitPlanMode 继续干”效果更好上下文 1M 时退出 Plan mode 直接执行不新开会话。9. “如何借助 Prompt Cache更省钱地使用 Agent”首先需要简单了解模型内部的 KV cache。LLM 是 transformer推理时每个 token 都要算它对前面所有 token 的 attention。直接算的话N 个 token 是 O(N²)。KV cache 是个工程优化——把每个 token 的 KKey、VValue张量存起来下一个 token 只算它对已存 K/V 的 attention复杂度降到 O(N)。这个 cache 是模型内部的运行时数据。Prompt cache提示缓存是 API 服务方做的产品化把“完全相同前缀的 K/V 向量”在自己的服务器里短期保留。下次请求开头部分和上次一样就直接复用 K/V只对新增部分收正常价钱缓存部分按 10% 左右折扣计费。以 5 分钟 TTL 为例。超过 5 分钟没有命中缓存被清理掉。长会话中断 1 小时再继续比连续跑 10 分钟更贵。场景上下文新增费用近似Cache hit100K1K100K × 0.1× 1K × 1× ≈ 11K token 费用Cache miss100K1K101K × 1× 101K token 费用说真的这两年看着身边一个个搞Java、C、前端、数据、架构的开始卷大模型挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis稳稳当当过日子。结果GPT、DeepSeek火了之后整条线上的人都开始有点慌了大家都在想“我是不是要学大模型不然这饭碗还能保多久”我先给出最直接的答案一定要把现有的技术和大模型结合起来而不是抛弃你们现有技术掌握AI能力的Java工程师比纯Java岗要吃香的多。即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇这绝非空谈。数据说话2025年的最后一个月脉脉高聘发布了《2025年度人才迁徙报告》披露了2025年前10个月的招聘市场现状。AI领域的人才需求呈现出极为迫切的“井喷”态势2025年前10个月新发AI岗位量同比增长543%9月单月同比增幅超11倍。同时在薪资方面AI领域也显著领先。其中月薪排名前20的高薪岗位平均月薪均超过6万元而这些席位大部分被AI研发岗占据。与此相对应市场为AI人才支付了显著的溢价算法工程师中专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%产品经理岗位中AI方向的产品经理薪资也领先约20%。当你意识到“技术AI”是个人突围的最佳路径时整个就业市场的数据也印证了同一个事实AI大模型正成为高薪机会的最大源头。最后我在一线科技企业深耕十二载见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事早已在效率与薪资上形成代际优势我意识到有很多经验和知识值得分享给大家也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我整理出这套 AI 大模型突围资料包【允许白嫖】✅从入门到精通的全套视频教程✅AI大模型学习路线图0基础到项目实战仅需90天✅大模型书籍与技术文档PDF✅各大厂大模型面试题目详解✅640套AI大模型报告合集✅大模型入门实战训练这份完整版的大模型 AI 学习和面试资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】①从入门到精通的全套视频教程包含提示词工程、RAG、Agent等技术点② AI大模型学习路线图0基础到项目实战仅需90天全过程AI大模型学习路线③学习电子书籍和技术文档市面上的大模型书籍确实太多了这些是我精选出来的④各大厂大模型面试题目详解⑤640套AI大模型报告合集⑥大模型入门实战训练获取方式有需要的小伙伴可以保存图片到wx扫描二v码免费领取【保证100%免费】
文章分析了Andrej Karpathy提出的两类AI用户差距问题指出理解AI原理对高效使用Agent至关重要。通过9个案例文章深入探讨了Claude Code、OpenClaw等Agent的上下文管理、能力扩展、安全与成本控制等关键技术涉及上下文工程、Subagent使用、Skill动态披露、权限控制、计划模式设计、Prompt Cache优化等内容旨在帮助读者提升AI Agent的使用水平。前言一个多月前Andrej Karpathy 发了一个推说他观察到 timeline 上的人分为两类并且这两类人之间的 gap 越来越大。•第一类低频使用的“白嫖”党“去年不知道在哪使用过免费的 ChatGPT由此形成对 AI 的认知”“嘲笑模型奇怪的回答和幻觉问 AI「我应该走路还是开车去洗车店」之类的问题”付费但无法发挥 Agent 全部能力开通了 SOTA 模型 $200/月的订阅但只用来做搜索、写作、寻求建议•第二类付费并在专业领域做专业的工作看 Agent 快速“融化”原本需要几天甚至几周的工作理解原理才能更好地使用本文将从 9 个具体的 case 出发浅析 Claude Code、OpenClaw 等 Agent harness 所做的 context engineering 工作和源码帮你更好地理解和使用你的 Agent。第一部分 · 上下文管理1. “我纠正了 AI 很多次但它还是不停地犯错…这种情况怎么办”Info场景……长历史上下文用户再写一个函数把数组里的元素累加起来。Agent我会稳稳接住你写了一个map没累加。用户不对是累加应该用reduce。Agent抱歉让我修复语法错了。用户这句根本编译不过……Agent再来一次又错在别处。……用户可能已经在心里或对话里开始骂“你怎么这么笨不应该这样应该那样”所有错误的 pattern都会留在 Agent 的 context list 里例如• 调用一个 tool被用户/权限配置拒绝• 调用一个 tooltool result 是一段报错信息• 输出一段内容被用户纠正• ……LLM 本质是 token in token out。当 context 累积变长模型会感受到 context pressure输出 EoSEnd of Sequence token 的概率提高导致模型能力下降表现为“无法遵循指令”“倾向于输出短句子结束对话”——即模型坍塌Model Collapse。因此当一轮对话中LLM 通过 tool call 试错或人工纠错轮次多了之后无效上下文占据了模型的 context window影响 agent 完成任务的能力。例如想让 Agent 帮我读一篇飞书文档总结核心内容并写入另一篇文档。当发现 LLM 调用了多轮 Fetch / Bash(curl) 工具都无法获取文档内容后就应该及时停止这轮对话新开一个会话。- User: 帮我读一篇飞书文档 xxx总结核心内容并写入另一篇文档。- Agent: 好的我会稳稳接住你。- Tool callFetch(xxx)- Tool resultForbidden- Tool call: Bash(curl xxx)- Tool resultHTTP Code 403……多轮 tool call 试错 及时 stop新开对话  新会话的提示词里直接告诉 Agent“使用 lark-cli 获取一篇飞书文档总结核心内容并写入另一篇文档”。 plaintext - User: 使用 lark-cli 获取一篇飞书文档 xxx总结核心内容并写入另一篇文档。- Agent: 好的我会稳稳接住你。- Tool callBash(which lark-cli lark-cli --version)- Tool resultx.y.z- Tool callBash(lark-cli fetch-doc xxx)- Tool result: xxx……多轮 tool call 完成任务 顺利完成任务  Tip **使用技巧** 1. 1. LLM tool call 试错太多或在对话中多次纠正 Agent 后果断放弃当前对话 2. 2. 新开对话在 prompt 中指定应该使用的工具或禁止不应尝试的路径。 ### ### 2. “我给 OpenClaw 派了不同的任务不同任务之间的上下文会互相影响吗OpenClaw 如何做的上下文隔离” Info **场景** * • 用户在飞书私聊 OpenClaw bot 让它写一份周报任务还没写完又想起来——这周还有个数据要它查和周报没任何关系。两个任务在同一个聊天里会不会互相影响如果过了一两天又新增了一个任务会影响吗 * • 群里 这个 bot 呢 * • 群里有人聊天没 bot但命中了关键词又是另一个会话吗 OpenClaw 通过 peerId、sessionKey 和 sessionId决定上下文如何分割。 * • peerIdIM 渠道侧「这个消息属于哪个聊天/话题/发言人范围」 * • sessionKey会话入口 key内部拼接 peerId一个 sessionKey 可能对应多个 session\_id * • session_id某个会话入口当前指向的实际 message list 文件 ID当 session\_id 过期或使用 /new 命令时生成新的 session\_id 并绑定到对应 sessionKey 上。  回到场景中的问题。 **私聊 OpenClaw bot 让它写一份周报任务还没写完又想起来——这周还有个数据要它查和周报没任何关系。** 上下文会互相影响。 **过了一两天又新增了一个任务。** OpenClaw 会判断历史的 session\_id 生成时间是否在本地网关时间 4:00 AM 之前。如果跨过了这个重置时间会生成新的 session\_id新消息不会携带历史上下文。 **群里 bot / 群聊命中关键词** 默认同群共享会话可以配置隔离。 | 配置 | 表现 | peerId pattern | | --- | --- | --- | | group\_sender | 按群中的发送人隔离同一个人发送的消息和收到的回复在同一个 context list 中 | chatId:sender:senderOpenId | | group\_topic | 按话题群的 topic 隔离同一个 topic 下的消息在同一个 context list 中 | chatId:topic:topicId | | group\_topic\_sender | 按话题群每个 topic 下的不同发送人隔离 | chatId:topic:topicId:sender:senderOpenId | Tip **使用技巧** 如果有并行任务需要 OpenClaw 处理并且不希望任务之间污染上下文。可以试试**创建一个专门的话题群用不同话题隔离上下文**。  ### ### 3. “Claude Code 和 OpenClaw 是如何‘记住’事情的OpenClaw 的 Dreaming 能力是什么怎么实现的记忆什么时候会被加载进上下文放在哪” Info **场景** * • Claude Code 在代码仓库中使用 npm 安装依赖用户纠正了一次“使用 pnpm”没有写入 CLAUDE.md 和 README.md但 Claude Code 记住了这个要求。 * • OpenClaw 还有个功能叫 **Dreaming**。它会在后台“做梦”然后会发现它的记忆变了。 Claude Code 和 OpenClaw 都用**文件系统**作为长期记忆载体。**模型本身没记忆**只是把需要“记住”的东西写在了 Markdown 文件里。下次对话时加载对应的 Markdown 文件。 **Claude Code 使用 Write/Edit 工具写入 memory分为两个时机** 1. 1. **Agent loop 中写**System prompt 中告诉模型“如果用户明确要求 remember就立即保存”。 2. 2. **后台写**每个完整 loop 结束后stopHook 触发 executeExtractMemories对这一轮 loop 的上下文进行 review更新 memory。 **Claude Code 加载 Memory 分为两层** 1. 1. **System prompt 加载“memory 机制说明”**memory 文件路径、什么时候保存、怎么保存、怎么读。 2. 2. **Memory 内容加载**一轮对话开始时通过 getUserContext函数和 CLAUDE.md 内容一起使用 system-reminder 标签注入 user message 里**memory 内容不会在 system prompt 里**。  OpenClaw 的 Memory 能力和 Claude Code 类似区别主要有两个 1. 1. 不会在 agent loop 结束后后台跑一个 agent 专门写 memory.md只是在执行过程中写 daily memory 2. 2. MEMORY.md 和 memory.md 会加载进 system prompt但 daily memory 不会。 Dreaming 主要解决这个问题对 daily memory 等文件中的内容做筛选、打分、去重和验证得分高的写入 MEMORY.md后续对话中直接加载进上下文。  Tip **使用技巧** 1. 1. 定期让 Agent review memory 内容发现错误及时更正避免污染未来上下文。 2. 2. 控制 memory 文件长度只存关键内容保障 agent 工作质量降低 token 成本文章最后会聊 第二部分 · 能力扩展 ----------- ### 4. “什么时候应该用 Subagents / Multi-agents / Agent Teams多 Agent 相比单 Agent 有何优劣” 要理解什么时候应该用 Subagents得先了解多 Agent 之间是怎么传递信息的。  可以看到主 Agent 在启动 Subagent 的时候并不是原封不动的传递用户诉求和主 Agent context list 中的上下文而是**对上下文做总结之后使用自然语言作为 user prompt启动 Subagent**。  这样做有一个**好处**所有调研过程中Web Search 的 tool call 和 tool result都在 Subagent 的上下文里主 Agent 的上下文不会膨胀。Subagent 只会按照要求告诉主 Agent 调研报告结果。中间被过滤掉的 Web Search 结果**不会污染主 Agent 上下文**。 但显然也有**坏处**这里创建的 Subagent 上下文和主 Agent 原始接收的**上下文出现了不对齐**。 1. 1. 用户并没有说要“合法赚到”手动狗头 2. 2. 用户要求“Make no mistakes!”Subagent 没有“感受到这个压力”。  通过这个例子可以理解**决定是否使用 Subagents 完成任务的关键是“上下文是否应该独立”**。  一些常见的反例是用 Subagents 玩“过家家”试图以此提高完成任务的可能性和质量比如让一个“脾气暴躁的 PM Agent”和一个“脾气暴躁的 RD Agent”battle。 * • LLM 并不理解“脾气暴躁”这只是几个额外、无意义的 token甚至可能会影响其他生成的 token影响整体工作质量 * • “过家家”式使用 Subagents还需要承担上下文不对齐的风险。例如一个简单的任务拆分了 PM Agent 和 RD AgentPM Agent 使用自然语言告知 RD Agent 任务时RD Agent 并不完整具备 PM Agent 的完整上下文可能导致最终完成工作的效果甚至不如只使用一个 Agent。 并不是说仿照 PM、RD 角色使用 Subagents 一定不对而是要根据“**上下文是否应该独立**”决定是否使用 Subagents。  Tip **使用技巧** 在 * • 子任务独立 * • 不依赖主 Agent 完整上下文 * • 已知过程中会有较多“试错”上下文不希望污染主 Agent context list 时使用 Subagents。 ### ### 5. “Skill 的动态披露是怎么做的Claude Code 的 ToolSearchTool 是怎么实现的” Claude Code Skill 的“动态披露”主要是三层机制。 1. 1. **先披露索引不披露全文**启动时会扫描 Skill但给模型的只是 name / description / when\_to\_use 这类 frontmatter 摘要不把整个 SKILL.md 放进上下文。这些索引会放第一条 user prompt 的 system-reminder 标签里告诉 LLM 有哪些可用的 Skill 2. 2. **通过 SkillTool加载 SKILL.md** 3. a. 模型调用 SkillTool 4. b. SkillTool.call() 调 processPromptSlashCommand(...) 5. c. 读取/生成完整 Skill 内容 6. d. SKILL.md 的内容作为一条 user message加载进上下文中 7. 3. **按需使用 FileReadTool加载 references使用 BashTool 执行 scripts**。  那么 Claude Code 中配置的 MCP Server tool 又是怎么通过 ToolSearchTool 做的动态披露呢  1. 1. 启动工具列表时如果 isToolSearchEnabledOptimistic() 认为可能启用就把 ToolSearchTool 加进基础工具列表 2. 2. **被判定为 deferred 的工具不会一开始完整暴露给模型**isDeferredTool() 规则是 3. a. MCP Server tool 默认 defer 4. b. 普通工具 shouldDefer true 的例如 AskUserQuestionTool、EnterPlanModeTool、TaskCreateTool、CronCreateTool 等会 defer 5. c. 但标记 alwaysLoad 的 tool、以及 ToolSearchTool 自身不 defer 6. 3. API 层只发送非 deferred tool以及历史里已经通过 ToolSearchTool 发现过的 deferred tool需要 API 请求时开启 defer_loading 配置。 这样即使配置了很多 MCP Server tool加上 Claude Code 内置很多 Tool 的情况下不使用到的 Tool 不会预占上下文空间。  ToolSearchTool 输入只有两个字段query 和可选 max_results。支持两种搜索方式 1. 1. **select:tool_name**精确选择工具支持逗号分隔多选比如 select:A,B,C 2. 2. **关键词搜索**对 deferred 工具的名字、searchHint、完整 tool prompt/description 做打分 3. a. MCP tool name 按 mcp__server__action 拆词普通工具按 CamelCase/下划线拆词 4. b. 名字精确命中权重大MCP 名字命中更高 5. c. searchHint 命中加分 6. d. 工具 prompt/description 命中也加分 7. e. term 表示 required term必须命中才进入候选集。 ToolSearchTool 真正“加载”工具的方式是返回 Anthropic beta 的 tool_reference block若使用其他 LLM Provider需 MaaS 平台支持。匹配到工具后它把结果映射成 plaintext { type: tool_result, content: [ { type: tool_reference, tool_name: name } ]}后续请求会扫描消息历史里的这些 tool_reference提取已发现工具名再把这些工具的完整 schema 加回 tools 数组。Tip使用技巧写 Skill 的 description、when_to_use 时准确告诉 LLM “什么时候应该使用”以及“什么时候不要使用”而不是简单介绍这个 Skill 是做什么的在开发自己的 Agent 时可以支持 ToolSearch tool避免 tool 的描述默认占据大量上下文空间。6. “什么东西应该被沉淀为 Skill如何创建、评估 Skill”Note个人实践仅供参考从上面分析 Skill 加载原理可以看到SKILL.md 的内容其实只是作为 roleuser 的 prompt 内容被加载进了 Agent 上下文中。其本质是一段用户提示词。所以当发现自己重复在使用同一段提示词或发现自己有一些重复的工作需要完成时可以考虑沉淀为 Skill。例如自己希望使用 Seedance 2.0 模型生成视频。通常直接跟 Agent 聊我需求使用/skill-creator创建 Skill。- User/skill-creator 我想使用火山引擎的 Seedance 2.0 模型生成视频使用 AskUserQuestion Tool 明确我的需求并帮我创建这个 skill。- Agent好的我先了解火山引擎的上下文再问你问题明确需求。- Tool callWebSearch(火山引擎 API 文档 2026)- Tool result...……多轮 tool call- Tool callAskUserQuestion(...)- Tool result...……多轮 tool call- Agent我来测试一下这个 skill- Tool callBash(bun /path/to/skill/scripts/generate.ts)- Tool result视频保存至 ...- Agent使用 skill-creator 中的 eval 测试 skill……- Agent测试完成 Skill 创建完成在这个过程中只需要提供一些必要的上下文例如使用的baseURL以及 model ID 等。为了更好解耦 Skill 本身内容和每个用户可能不同的配置内容创建 skill 时在其中说明偏好配置文件位置规则。利用 Agent ReadFile、Bash 能力对 skill 内容进行扩展。提供首次使用 Skill 的引导让用户的 agent 可以协助其完成配置。对于 scripts使用 bun TypeScript 文件有两个好处强类型约束agent 写的脚本代码更不容易犯错使用 bun 代替 NodeJS 做运行时不需要 TS 编译成 JS方便 Agent 维护迭代。看看效果生成一个“老黄”赶空军一号飞机的视频首次使用Agent 引导用户进行配置。配置完成调用 scripts/generate.ts 脚本开始生成。生成视频效果Tip使用技巧先在一轮对话中跑通流程让 Agent 使用 skill-creator 帮你创建 Skill使用 bun TypeScript 写 scripts强类型且不需要编译如果运行报错Agent 知道怎么改利用 LLM 天生喜欢使用 Bash Tool 的特点结合文件系统做动态披露和 Skill 扩展定制使用 skill-creator evaluate Skill并在实际流程中试验迭代 Skill。第三部分 · 安全与成本7. “Claude Code 的 auto permission mode 是怎么实现的为什么同一个 tool call第一次被拦截但告诉 agent 可以操作后就能执行成功”Claude Code 的 auto permission mode 是一个权限判断流水线核心流程如下代码先做普通权限判断显式 deny/ask/allow 规则、tool 自身权限、safety check、mode fast path如果结果是 ask 且当前是 auto代码把当前 tool call 和相关对话历史整理成classifier输入。classifier调 LLM 判断这次 action 是否应该 block。代码解析 LLM 结果并返回 allow 或 deny。如果用户之后明确说“可以操作”这句话进入下一次 classifier 的上下文所以同类 tool call 可能被允许。Tip使用技巧配置allow、ask、deny平衡 Agent loop 自动执行的效率和安全边界例如 allowBash(npm run test:*)denyRead(.env*)askBash(rm -rf:*)使用 auto mode 代替 bypass permission。8. “Claude Code 的 plan mode 是怎么设计的如何防止 Agent 跳过方案设计直接开始写代码”Claude Code 的 plan mode 有三层约束防止 Agent 跳过方案设计直接写代码。层级机制约束效果1Prompt 指令EnterPlanMode 的工具结果里明文写 “DO NOT write or edit any files yet”弱依赖模型遵循指令能力2Tool 的isReadOnly()标志每个工具自己声明只读 vs 会写入中影响模型选择工具3人工确认Plan mode 里尝试 Write 或 Edit 时会要求用户确认是否切换到acceptEdits强permission 代码约束人工确认为什么不直接 hardcode 「plan mode 时 Agent 没有 Write 和 Edit tool」模型需要使用 Write 和 Edit tool 在~/.claude/plans目录下创建和修改 Markdown 文件。Tip使用技巧上下文 200K 时Plan mode 的产出喂给新会话。新会话从一个干净的 context window 开始按一份明确方案执行比“在 plan 会话里直接 ExitPlanMode 继续干”效果更好上下文 1M 时退出 Plan mode 直接执行不新开会话。9. “如何借助 Prompt Cache更省钱地使用 Agent”首先需要简单了解模型内部的 KV cache。LLM 是 transformer推理时每个 token 都要算它对前面所有 token 的 attention。直接算的话N 个 token 是 O(N²)。KV cache 是个工程优化——把每个 token 的 KKey、VValue张量存起来下一个 token 只算它对已存 K/V 的 attention复杂度降到 O(N)。这个 cache 是模型内部的运行时数据。Prompt cache提示缓存是 API 服务方做的产品化把“完全相同前缀的 K/V 向量”在自己的服务器里短期保留。下次请求开头部分和上次一样就直接复用 K/V只对新增部分收正常价钱缓存部分按 10% 左右折扣计费。以 5 分钟 TTL 为例。超过 5 分钟没有命中缓存被清理掉。长会话中断 1 小时再继续比连续跑 10 分钟更贵。场景上下文新增费用近似Cache hit100K1K100K × 0.1× 1K × 1× ≈ 11K token 费用Cache miss100K1K101K × 1× 101K token 费用说真的这两年看着身边一个个搞Java、C、前端、数据、架构的开始卷大模型挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis稳稳当当过日子。结果GPT、DeepSeek火了之后整条线上的人都开始有点慌了大家都在想“我是不是要学大模型不然这饭碗还能保多久”我先给出最直接的答案一定要把现有的技术和大模型结合起来而不是抛弃你们现有技术掌握AI能力的Java工程师比纯Java岗要吃香的多。即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇这绝非空谈。数据说话2025年的最后一个月脉脉高聘发布了《2025年度人才迁徙报告》披露了2025年前10个月的招聘市场现状。AI领域的人才需求呈现出极为迫切的“井喷”态势2025年前10个月新发AI岗位量同比增长543%9月单月同比增幅超11倍。同时在薪资方面AI领域也显著领先。其中月薪排名前20的高薪岗位平均月薪均超过6万元而这些席位大部分被AI研发岗占据。与此相对应市场为AI人才支付了显著的溢价算法工程师中专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%产品经理岗位中AI方向的产品经理薪资也领先约20%。当你意识到“技术AI”是个人突围的最佳路径时整个就业市场的数据也印证了同一个事实AI大模型正成为高薪机会的最大源头。最后我在一线科技企业深耕十二载见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事早已在效率与薪资上形成代际优势我意识到有很多经验和知识值得分享给大家也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我整理出这套 AI 大模型突围资料包【允许白嫖】✅从入门到精通的全套视频教程✅AI大模型学习路线图0基础到项目实战仅需90天✅大模型书籍与技术文档PDF✅各大厂大模型面试题目详解✅640套AI大模型报告合集✅大模型入门实战训练这份完整版的大模型 AI 学习和面试资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】①从入门到精通的全套视频教程包含提示词工程、RAG、Agent等技术点② AI大模型学习路线图0基础到项目实战仅需90天全过程AI大模型学习路线③学习电子书籍和技术文档市面上的大模型书籍确实太多了这些是我精选出来的④各大厂大模型面试题目详解⑤640套AI大模型报告合集⑥大模型入门实战训练获取方式有需要的小伙伴可以保存图片到wx扫描二v码免费领取【保证100%免费】
掌握AI Agent上下文工程:从9个案例看懂如何让AI“记住”事情,提升工作效率
发布时间:2026/5/28 23:40:18
文章分析了Andrej Karpathy提出的两类AI用户差距问题指出理解AI原理对高效使用Agent至关重要。通过9个案例文章深入探讨了Claude Code、OpenClaw等Agent的上下文管理、能力扩展、安全与成本控制等关键技术涉及上下文工程、Subagent使用、Skill动态披露、权限控制、计划模式设计、Prompt Cache优化等内容旨在帮助读者提升AI Agent的使用水平。前言一个多月前Andrej Karpathy 发了一个推说他观察到 timeline 上的人分为两类并且这两类人之间的 gap 越来越大。•第一类低频使用的“白嫖”党“去年不知道在哪使用过免费的 ChatGPT由此形成对 AI 的认知”“嘲笑模型奇怪的回答和幻觉问 AI「我应该走路还是开车去洗车店」之类的问题”付费但无法发挥 Agent 全部能力开通了 SOTA 模型 $200/月的订阅但只用来做搜索、写作、寻求建议•第二类付费并在专业领域做专业的工作看 Agent 快速“融化”原本需要几天甚至几周的工作理解原理才能更好地使用本文将从 9 个具体的 case 出发浅析 Claude Code、OpenClaw 等 Agent harness 所做的 context engineering 工作和源码帮你更好地理解和使用你的 Agent。第一部分 · 上下文管理1. “我纠正了 AI 很多次但它还是不停地犯错…这种情况怎么办”Info场景……长历史上下文用户再写一个函数把数组里的元素累加起来。Agent我会稳稳接住你写了一个map没累加。用户不对是累加应该用reduce。Agent抱歉让我修复语法错了。用户这句根本编译不过……Agent再来一次又错在别处。……用户可能已经在心里或对话里开始骂“你怎么这么笨不应该这样应该那样”所有错误的 pattern都会留在 Agent 的 context list 里例如• 调用一个 tool被用户/权限配置拒绝• 调用一个 tooltool result 是一段报错信息• 输出一段内容被用户纠正• ……LLM 本质是 token in token out。当 context 累积变长模型会感受到 context pressure输出 EoSEnd of Sequence token 的概率提高导致模型能力下降表现为“无法遵循指令”“倾向于输出短句子结束对话”——即模型坍塌Model Collapse。因此当一轮对话中LLM 通过 tool call 试错或人工纠错轮次多了之后无效上下文占据了模型的 context window影响 agent 完成任务的能力。例如想让 Agent 帮我读一篇飞书文档总结核心内容并写入另一篇文档。当发现 LLM 调用了多轮 Fetch / Bash(curl) 工具都无法获取文档内容后就应该及时停止这轮对话新开一个会话。- User: 帮我读一篇飞书文档 xxx总结核心内容并写入另一篇文档。- Agent: 好的我会稳稳接住你。- Tool callFetch(xxx)- Tool resultForbidden- Tool call: Bash(curl xxx)- Tool resultHTTP Code 403……多轮 tool call 试错 及时 stop新开对话  新会话的提示词里直接告诉 Agent“使用 lark-cli 获取一篇飞书文档总结核心内容并写入另一篇文档”。 plaintext - User: 使用 lark-cli 获取一篇飞书文档 xxx总结核心内容并写入另一篇文档。- Agent: 好的我会稳稳接住你。- Tool callBash(which lark-cli lark-cli --version)- Tool resultx.y.z- Tool callBash(lark-cli fetch-doc xxx)- Tool result: xxx……多轮 tool call 完成任务 顺利完成任务  Tip **使用技巧** 1. 1. LLM tool call 试错太多或在对话中多次纠正 Agent 后果断放弃当前对话 2. 2. 新开对话在 prompt 中指定应该使用的工具或禁止不应尝试的路径。 ### ### 2. “我给 OpenClaw 派了不同的任务不同任务之间的上下文会互相影响吗OpenClaw 如何做的上下文隔离” Info **场景** * • 用户在飞书私聊 OpenClaw bot 让它写一份周报任务还没写完又想起来——这周还有个数据要它查和周报没任何关系。两个任务在同一个聊天里会不会互相影响如果过了一两天又新增了一个任务会影响吗 * • 群里 这个 bot 呢 * • 群里有人聊天没 bot但命中了关键词又是另一个会话吗 OpenClaw 通过 peerId、sessionKey 和 sessionId决定上下文如何分割。 * • peerIdIM 渠道侧「这个消息属于哪个聊天/话题/发言人范围」 * • sessionKey会话入口 key内部拼接 peerId一个 sessionKey 可能对应多个 session\_id * • session_id某个会话入口当前指向的实际 message list 文件 ID当 session\_id 过期或使用 /new 命令时生成新的 session\_id 并绑定到对应 sessionKey 上。  回到场景中的问题。 **私聊 OpenClaw bot 让它写一份周报任务还没写完又想起来——这周还有个数据要它查和周报没任何关系。** 上下文会互相影响。 **过了一两天又新增了一个任务。** OpenClaw 会判断历史的 session\_id 生成时间是否在本地网关时间 4:00 AM 之前。如果跨过了这个重置时间会生成新的 session\_id新消息不会携带历史上下文。 **群里 bot / 群聊命中关键词** 默认同群共享会话可以配置隔离。 | 配置 | 表现 | peerId pattern | | --- | --- | --- | | group\_sender | 按群中的发送人隔离同一个人发送的消息和收到的回复在同一个 context list 中 | chatId:sender:senderOpenId | | group\_topic | 按话题群的 topic 隔离同一个 topic 下的消息在同一个 context list 中 | chatId:topic:topicId | | group\_topic\_sender | 按话题群每个 topic 下的不同发送人隔离 | chatId:topic:topicId:sender:senderOpenId | Tip **使用技巧** 如果有并行任务需要 OpenClaw 处理并且不希望任务之间污染上下文。可以试试**创建一个专门的话题群用不同话题隔离上下文**。  ### ### 3. “Claude Code 和 OpenClaw 是如何‘记住’事情的OpenClaw 的 Dreaming 能力是什么怎么实现的记忆什么时候会被加载进上下文放在哪” Info **场景** * • Claude Code 在代码仓库中使用 npm 安装依赖用户纠正了一次“使用 pnpm”没有写入 CLAUDE.md 和 README.md但 Claude Code 记住了这个要求。 * • OpenClaw 还有个功能叫 **Dreaming**。它会在后台“做梦”然后会发现它的记忆变了。 Claude Code 和 OpenClaw 都用**文件系统**作为长期记忆载体。**模型本身没记忆**只是把需要“记住”的东西写在了 Markdown 文件里。下次对话时加载对应的 Markdown 文件。 **Claude Code 使用 Write/Edit 工具写入 memory分为两个时机** 1. 1. **Agent loop 中写**System prompt 中告诉模型“如果用户明确要求 remember就立即保存”。 2. 2. **后台写**每个完整 loop 结束后stopHook 触发 executeExtractMemories对这一轮 loop 的上下文进行 review更新 memory。 **Claude Code 加载 Memory 分为两层** 1. 1. **System prompt 加载“memory 机制说明”**memory 文件路径、什么时候保存、怎么保存、怎么读。 2. 2. **Memory 内容加载**一轮对话开始时通过 getUserContext函数和 CLAUDE.md 内容一起使用 system-reminder 标签注入 user message 里**memory 内容不会在 system prompt 里**。  OpenClaw 的 Memory 能力和 Claude Code 类似区别主要有两个 1. 1. 不会在 agent loop 结束后后台跑一个 agent 专门写 memory.md只是在执行过程中写 daily memory 2. 2. MEMORY.md 和 memory.md 会加载进 system prompt但 daily memory 不会。 Dreaming 主要解决这个问题对 daily memory 等文件中的内容做筛选、打分、去重和验证得分高的写入 MEMORY.md后续对话中直接加载进上下文。  Tip **使用技巧** 1. 1. 定期让 Agent review memory 内容发现错误及时更正避免污染未来上下文。 2. 2. 控制 memory 文件长度只存关键内容保障 agent 工作质量降低 token 成本文章最后会聊 第二部分 · 能力扩展 ----------- ### 4. “什么时候应该用 Subagents / Multi-agents / Agent Teams多 Agent 相比单 Agent 有何优劣” 要理解什么时候应该用 Subagents得先了解多 Agent 之间是怎么传递信息的。  可以看到主 Agent 在启动 Subagent 的时候并不是原封不动的传递用户诉求和主 Agent context list 中的上下文而是**对上下文做总结之后使用自然语言作为 user prompt启动 Subagent**。  这样做有一个**好处**所有调研过程中Web Search 的 tool call 和 tool result都在 Subagent 的上下文里主 Agent 的上下文不会膨胀。Subagent 只会按照要求告诉主 Agent 调研报告结果。中间被过滤掉的 Web Search 结果**不会污染主 Agent 上下文**。 但显然也有**坏处**这里创建的 Subagent 上下文和主 Agent 原始接收的**上下文出现了不对齐**。 1. 1. 用户并没有说要“合法赚到”手动狗头 2. 2. 用户要求“Make no mistakes!”Subagent 没有“感受到这个压力”。  通过这个例子可以理解**决定是否使用 Subagents 完成任务的关键是“上下文是否应该独立”**。  一些常见的反例是用 Subagents 玩“过家家”试图以此提高完成任务的可能性和质量比如让一个“脾气暴躁的 PM Agent”和一个“脾气暴躁的 RD Agent”battle。 * • LLM 并不理解“脾气暴躁”这只是几个额外、无意义的 token甚至可能会影响其他生成的 token影响整体工作质量 * • “过家家”式使用 Subagents还需要承担上下文不对齐的风险。例如一个简单的任务拆分了 PM Agent 和 RD AgentPM Agent 使用自然语言告知 RD Agent 任务时RD Agent 并不完整具备 PM Agent 的完整上下文可能导致最终完成工作的效果甚至不如只使用一个 Agent。 并不是说仿照 PM、RD 角色使用 Subagents 一定不对而是要根据“**上下文是否应该独立**”决定是否使用 Subagents。  Tip **使用技巧** 在 * • 子任务独立 * • 不依赖主 Agent 完整上下文 * • 已知过程中会有较多“试错”上下文不希望污染主 Agent context list 时使用 Subagents。 ### ### 5. “Skill 的动态披露是怎么做的Claude Code 的 ToolSearchTool 是怎么实现的” Claude Code Skill 的“动态披露”主要是三层机制。 1. 1. **先披露索引不披露全文**启动时会扫描 Skill但给模型的只是 name / description / when\_to\_use 这类 frontmatter 摘要不把整个 SKILL.md 放进上下文。这些索引会放第一条 user prompt 的 system-reminder 标签里告诉 LLM 有哪些可用的 Skill 2. 2. **通过 SkillTool加载 SKILL.md** 3. a. 模型调用 SkillTool 4. b. SkillTool.call() 调 processPromptSlashCommand(...) 5. c. 读取/生成完整 Skill 内容 6. d. SKILL.md 的内容作为一条 user message加载进上下文中 7. 3. **按需使用 FileReadTool加载 references使用 BashTool 执行 scripts**。  那么 Claude Code 中配置的 MCP Server tool 又是怎么通过 ToolSearchTool 做的动态披露呢  1. 1. 启动工具列表时如果 isToolSearchEnabledOptimistic() 认为可能启用就把 ToolSearchTool 加进基础工具列表 2. 2. **被判定为 deferred 的工具不会一开始完整暴露给模型**isDeferredTool() 规则是 3. a. MCP Server tool 默认 defer 4. b. 普通工具 shouldDefer true 的例如 AskUserQuestionTool、EnterPlanModeTool、TaskCreateTool、CronCreateTool 等会 defer 5. c. 但标记 alwaysLoad 的 tool、以及 ToolSearchTool 自身不 defer 6. 3. API 层只发送非 deferred tool以及历史里已经通过 ToolSearchTool 发现过的 deferred tool需要 API 请求时开启 defer_loading 配置。 这样即使配置了很多 MCP Server tool加上 Claude Code 内置很多 Tool 的情况下不使用到的 Tool 不会预占上下文空间。  ToolSearchTool 输入只有两个字段query 和可选 max_results。支持两种搜索方式 1. 1. **select:tool_name**精确选择工具支持逗号分隔多选比如 select:A,B,C 2. 2. **关键词搜索**对 deferred 工具的名字、searchHint、完整 tool prompt/description 做打分 3. a. MCP tool name 按 mcp__server__action 拆词普通工具按 CamelCase/下划线拆词 4. b. 名字精确命中权重大MCP 名字命中更高 5. c. searchHint 命中加分 6. d. 工具 prompt/description 命中也加分 7. e. term 表示 required term必须命中才进入候选集。 ToolSearchTool 真正“加载”工具的方式是返回 Anthropic beta 的 tool_reference block若使用其他 LLM Provider需 MaaS 平台支持。匹配到工具后它把结果映射成 plaintext { type: tool_result, content: [ { type: tool_reference, tool_name: name } ]}后续请求会扫描消息历史里的这些 tool_reference提取已发现工具名再把这些工具的完整 schema 加回 tools 数组。Tip使用技巧写 Skill 的 description、when_to_use 时准确告诉 LLM “什么时候应该使用”以及“什么时候不要使用”而不是简单介绍这个 Skill 是做什么的在开发自己的 Agent 时可以支持 ToolSearch tool避免 tool 的描述默认占据大量上下文空间。6. “什么东西应该被沉淀为 Skill如何创建、评估 Skill”Note个人实践仅供参考从上面分析 Skill 加载原理可以看到SKILL.md 的内容其实只是作为 roleuser 的 prompt 内容被加载进了 Agent 上下文中。其本质是一段用户提示词。所以当发现自己重复在使用同一段提示词或发现自己有一些重复的工作需要完成时可以考虑沉淀为 Skill。例如自己希望使用 Seedance 2.0 模型生成视频。通常直接跟 Agent 聊我需求使用/skill-creator创建 Skill。- User/skill-creator 我想使用火山引擎的 Seedance 2.0 模型生成视频使用 AskUserQuestion Tool 明确我的需求并帮我创建这个 skill。- Agent好的我先了解火山引擎的上下文再问你问题明确需求。- Tool callWebSearch(火山引擎 API 文档 2026)- Tool result...……多轮 tool call- Tool callAskUserQuestion(...)- Tool result...……多轮 tool call- Agent我来测试一下这个 skill- Tool callBash(bun /path/to/skill/scripts/generate.ts)- Tool result视频保存至 ...- Agent使用 skill-creator 中的 eval 测试 skill……- Agent测试完成 Skill 创建完成在这个过程中只需要提供一些必要的上下文例如使用的baseURL以及 model ID 等。为了更好解耦 Skill 本身内容和每个用户可能不同的配置内容创建 skill 时在其中说明偏好配置文件位置规则。利用 Agent ReadFile、Bash 能力对 skill 内容进行扩展。提供首次使用 Skill 的引导让用户的 agent 可以协助其完成配置。对于 scripts使用 bun TypeScript 文件有两个好处强类型约束agent 写的脚本代码更不容易犯错使用 bun 代替 NodeJS 做运行时不需要 TS 编译成 JS方便 Agent 维护迭代。看看效果生成一个“老黄”赶空军一号飞机的视频首次使用Agent 引导用户进行配置。配置完成调用 scripts/generate.ts 脚本开始生成。生成视频效果Tip使用技巧先在一轮对话中跑通流程让 Agent 使用 skill-creator 帮你创建 Skill使用 bun TypeScript 写 scripts强类型且不需要编译如果运行报错Agent 知道怎么改利用 LLM 天生喜欢使用 Bash Tool 的特点结合文件系统做动态披露和 Skill 扩展定制使用 skill-creator evaluate Skill并在实际流程中试验迭代 Skill。第三部分 · 安全与成本7. “Claude Code 的 auto permission mode 是怎么实现的为什么同一个 tool call第一次被拦截但告诉 agent 可以操作后就能执行成功”Claude Code 的 auto permission mode 是一个权限判断流水线核心流程如下代码先做普通权限判断显式 deny/ask/allow 规则、tool 自身权限、safety check、mode fast path如果结果是 ask 且当前是 auto代码把当前 tool call 和相关对话历史整理成classifier输入。classifier调 LLM 判断这次 action 是否应该 block。代码解析 LLM 结果并返回 allow 或 deny。如果用户之后明确说“可以操作”这句话进入下一次 classifier 的上下文所以同类 tool call 可能被允许。Tip使用技巧配置allow、ask、deny平衡 Agent loop 自动执行的效率和安全边界例如 allowBash(npm run test:*)denyRead(.env*)askBash(rm -rf:*)使用 auto mode 代替 bypass permission。8. “Claude Code 的 plan mode 是怎么设计的如何防止 Agent 跳过方案设计直接开始写代码”Claude Code 的 plan mode 有三层约束防止 Agent 跳过方案设计直接写代码。层级机制约束效果1Prompt 指令EnterPlanMode 的工具结果里明文写 “DO NOT write or edit any files yet”弱依赖模型遵循指令能力2Tool 的isReadOnly()标志每个工具自己声明只读 vs 会写入中影响模型选择工具3人工确认Plan mode 里尝试 Write 或 Edit 时会要求用户确认是否切换到acceptEdits强permission 代码约束人工确认为什么不直接 hardcode 「plan mode 时 Agent 没有 Write 和 Edit tool」模型需要使用 Write 和 Edit tool 在~/.claude/plans目录下创建和修改 Markdown 文件。Tip使用技巧上下文 200K 时Plan mode 的产出喂给新会话。新会话从一个干净的 context window 开始按一份明确方案执行比“在 plan 会话里直接 ExitPlanMode 继续干”效果更好上下文 1M 时退出 Plan mode 直接执行不新开会话。9. “如何借助 Prompt Cache更省钱地使用 Agent”首先需要简单了解模型内部的 KV cache。LLM 是 transformer推理时每个 token 都要算它对前面所有 token 的 attention。直接算的话N 个 token 是 O(N²)。KV cache 是个工程优化——把每个 token 的 KKey、VValue张量存起来下一个 token 只算它对已存 K/V 的 attention复杂度降到 O(N)。这个 cache 是模型内部的运行时数据。Prompt cache提示缓存是 API 服务方做的产品化把“完全相同前缀的 K/V 向量”在自己的服务器里短期保留。下次请求开头部分和上次一样就直接复用 K/V只对新增部分收正常价钱缓存部分按 10% 左右折扣计费。以 5 分钟 TTL 为例。超过 5 分钟没有命中缓存被清理掉。长会话中断 1 小时再继续比连续跑 10 分钟更贵。场景上下文新增费用近似Cache hit100K1K100K × 0.1× 1K × 1× ≈ 11K token 费用Cache miss100K1K101K × 1× 101K token 费用说真的这两年看着身边一个个搞Java、C、前端、数据、架构的开始卷大模型挺唏嘘的。大家最开始都是写接口、搞Spring Boot、连数据库、配Redis稳稳当当过日子。结果GPT、DeepSeek火了之后整条线上的人都开始有点慌了大家都在想“我是不是要学大模型不然这饭碗还能保多久”我先给出最直接的答案一定要把现有的技术和大模型结合起来而不是抛弃你们现有技术掌握AI能力的Java工程师比纯Java岗要吃香的多。即使现在裁员、降薪、团队解散的比比皆是……但后续的趋势一定是AI应用落地大模型方向才是实现职业升级、提升薪资待遇的绝佳机遇这绝非空谈。数据说话2025年的最后一个月脉脉高聘发布了《2025年度人才迁徙报告》披露了2025年前10个月的招聘市场现状。AI领域的人才需求呈现出极为迫切的“井喷”态势2025年前10个月新发AI岗位量同比增长543%9月单月同比增幅超11倍。同时在薪资方面AI领域也显著领先。其中月薪排名前20的高薪岗位平均月薪均超过6万元而这些席位大部分被AI研发岗占据。与此相对应市场为AI人才支付了显著的溢价算法工程师中专攻AIGC方向的岗位平均薪资较普通算法工程师高出近18%产品经理岗位中AI方向的产品经理薪资也领先约20%。当你意识到“技术AI”是个人突围的最佳路径时整个就业市场的数据也印证了同一个事实AI大模型正成为高薪机会的最大源头。最后我在一线科技企业深耕十二载见证过太多因技术卡位而跃迁的案例。那些率先拥抱 AI 的同事早已在效率与薪资上形成代际优势我意识到有很多经验和知识值得分享给大家也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。我整理出这套 AI 大模型突围资料包【允许白嫖】✅从入门到精通的全套视频教程✅AI大模型学习路线图0基础到项目实战仅需90天✅大模型书籍与技术文档PDF✅各大厂大模型面试题目详解✅640套AI大模型报告合集✅大模型入门实战训练这份完整版的大模型 AI 学习和面试资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】①从入门到精通的全套视频教程包含提示词工程、RAG、Agent等技术点② AI大模型学习路线图0基础到项目实战仅需90天全过程AI大模型学习路线③学习电子书籍和技术文档市面上的大模型书籍确实太多了这些是我精选出来的④各大厂大模型面试题目详解⑤640套AI大模型报告合集⑥大模型入门实战训练获取方式有需要的小伙伴可以保存图片到wx扫描二v码免费领取【保证100%免费】
相关文章

基于Arduino与Si4703的RDS FM收音机DIY:从硬件设计到软件实现
1. 项目概述与核心价值想自己动手做一台能显示电台名称、甚至天气预报的FM收音机吗?这听起来像是专业收音机才有的功能,但借助Arduino和一些现成的模块,我们完全可以在周末的下午把它搭建出来。这个项目的核心,就是利用Arduino微控…
AI时代的新铁饭碗:2026届毕业生最值得关注的三大高薪
文章指出,在AI时代,“铁饭碗”不再是传统意义上的公务员或国企编制,而是指具备在技术浪潮中不被淘汰的能力组合。2026年,中国AI产业规模突破1.2万亿元,AI企业超6000家,人才缺口仍在百万级。大四毕业生应抓住…
Adobe-GenP 3.0:终极Adobe软件激活工具完整指南
Adobe-GenP 3.0:终极Adobe软件激活工具完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款功能强大的Adobe Creative Cloud通…

Magisk 深度指南:掌握 Android 系统级定制与 Root 权限管理的核心技术
Magisk 深度指南:掌握 Android 系统级定制与 Root 权限管理的核心技术 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk 作为 Android 生态中的"魔法面具",彻底改…
5大智能功能全面解析:BetterGI如何让你的原神游戏体验更高效
5大智能功能全面解析:BetterGI如何让你的原神游戏体验更高效 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音…
供水管网及泵站远程监控运维管理系统方案
当前,城市供水系统面临管网分布广、泵站数量多、运维难度大的现实挑战。传统管理模式依赖人工巡检、电话报修、现场操作,存在数据滞后、响应迟缓、故障定位困难等问题,难以保障供水安全与运行效率。因此,水务单位亟需构建一套集远…
前后端分离架构中后端技术栈的角色与挑战
在当今快速发展的互联网时代,前后端分离架构已成为构建现代Web应用的主流模式。这种架构将前端(用户界面)与后端(业务逻辑和数据处理)解耦,使得开发团队能够更加专注于各自领域的技术优化与创新。在这一架构…
Arduino智能温控风扇系统:从传感器到执行器的嵌入式闭环控制实践
1. 项目概述与核心思路做嵌入式开发的朋友,应该都绕不开传感器与执行器协同控制这个经典课题。这不仅是理解物联网底层逻辑的敲门砖,更是检验你能否将代码逻辑、硬件电路和物理世界连接起来的关键一步。今天分享的这个项目——基于Arduino的智能温控风扇…
别再乱删文件了!手把手教你用chattr给Linux文件上锁(附防误删实战)
Linux文件防误删终极指南:用chattr打造不可删除的金钟罩上周隔壁团队又发生了一起"血案":一位新人在清理临时文件时,误执行了rm -rf *,导致整个项目的配置文件灰飞烟灭。这种事故在Linux系统中屡见不鲜,而今…

PostgreSQL Vacuum介绍(一种核心数据库维护操作,主要用于解决MVCC多版本并发控制机制带来的死元组dead tuples问题)回收死元组空间、存储空间耗尽、避免幻读、垃圾回收器
文章目录**为什么需要 Vacuum?****Vacuum 的核心作用****实际场景中的关键点****简单总结**在 PostgreSQL 中, Vacuum 是一种 核心的数据库维护操作,主要用于解决 MVCC(多版本并发控制)机制 带来的“死元组࿰…
从零设计可调光LED夜灯:NE555 PWM电路全流程实战指南
1. 项目概述:为什么电路设计是每个创客的必修课如果你对电子制作感兴趣,无论是想做一个会发光的徽章,还是一个能自动浇花的小装置,你都会发现,所有想法最终都要落到一块小小的电路板上。电路设计,就是连接创…
基于Arduino的动漫角色机械面制作:从传感器到伺服电机的交互实现
1. 项目概述:从动漫角色到可交互的机械面我一直对如何让静态的模型“活”起来充满兴趣,特别是那些我们熟悉的动漫角色。这次,我决定挑战自己,制作一个基于《火影忍者》中宇智波佐助的机械面。这个项目的核心目标很简单:…

施工现场安全事故预警准确率达94.6%?——解密某央企AI Agent边缘计算部署架构与3个月落地实录
更多请点击: https://codechina.net 第一章:施工现场安全事故预警准确率达94.6%?——解密某央企AI Agent边缘计算部署架构与3个月落地实录 在华北某大型地铁盾构施工现场,一套轻量化AI Agent系统于2024年Q2完成全栈部署ÿ…
附录 B:术语表
本术语表面向“从 MM 到 HMM”专栏阅读过程中的快速查阅。它不是内核 API 手册,而是把文章中反复出现的概念放到同一张地图上:先给出直观含义,再说明它在 Linux MM/HMM 语境里的作用。建议阅读方式: 初读专栏时,把它当…
Midjourney渐变美学的神经渲染原理(附RGB-HSV-LCH三空间渐变映射对照表·行业首曝)
更多请点击: https://kaifayun.com 第一章:Midjourney渐变美学的神经渲染原理(附RGB-HSV-LCH三空间渐变映射对照表行业首曝) Midjourney 的渐变美学并非传统插值实现,而是由其隐式神经渲染器(Implicit Neu…

MPC-BE:基于DirectShow架构的专业级开源媒体播放解决方案
MPC-BE:基于DirectShow架构的专业级开源媒体播放解决方案 【免费下载链接】MPC-BE MPC-BE – универсальный проигрыватель аудио и видеофайлов для операционной системы Windows. 项目地址:…
如何快速计算3D模型体积和重量:STL-Volume-Model-Calculator终极指南
如何快速计算3D模型体积和重量:STL-Volume-Model-Calculator终极指南 【免费下载链接】STL-Volume-Model-Calculator STL Volume Model Calculator Python 项目地址: https://gitcode.com/gh_mirrors/st/STL-Volume-Model-Calculator 你是否曾经为3D打印项目…
通过Taotoken CLI工具一键配置团队开发环境与模型密钥
通过Taotoken CLI工具一键配置团队开发环境与模型密钥 1. CLI工具安装与基本使用 Taotoken提供的CLI工具可通过npm全局安装或直接使用npx运行。对于需要频繁使用CLI的团队,推荐全局安装: npm install -g taotoken/taotoken对于临时使用或项目级配置&a…