 影刀RPA进阶教程Python代码指令做数据清洗——正则提取与字符串处理影刀的流程指令处理点击、输入、表格读写都很顺手但一到字符串处理就吃力了。比如从¥128.00里把128提取出来、从已售10万件里提取10万、从一堆描述文字里找到手机号。这些操作用Python的正则表达式re模块一行搞定但有一个前提Python图标要先点亮。一、在影刀里打开Python代码指令影刀流程画布左侧的指令面板里有一个Python代码指令。拖到画布上弹出一个代码编辑器。注意左下角的Python图标必须是亮的。如果灰色点一下它。代码编辑器里可以写任意Python代码流程中前面步骤产生的变量可以通过影刀内置的方式获取。拼多多店群自动化上架方案二、正则表达式入门从字符串里挑数字电商数据清洗里80%的Python需求都是这个# 从各种格式的价格文本里提取数字importre 价格文本¥128.00价格数字float(re.search(r\d\.?\d*,价格文本).group())# 结果128.0价格文本2 99.9起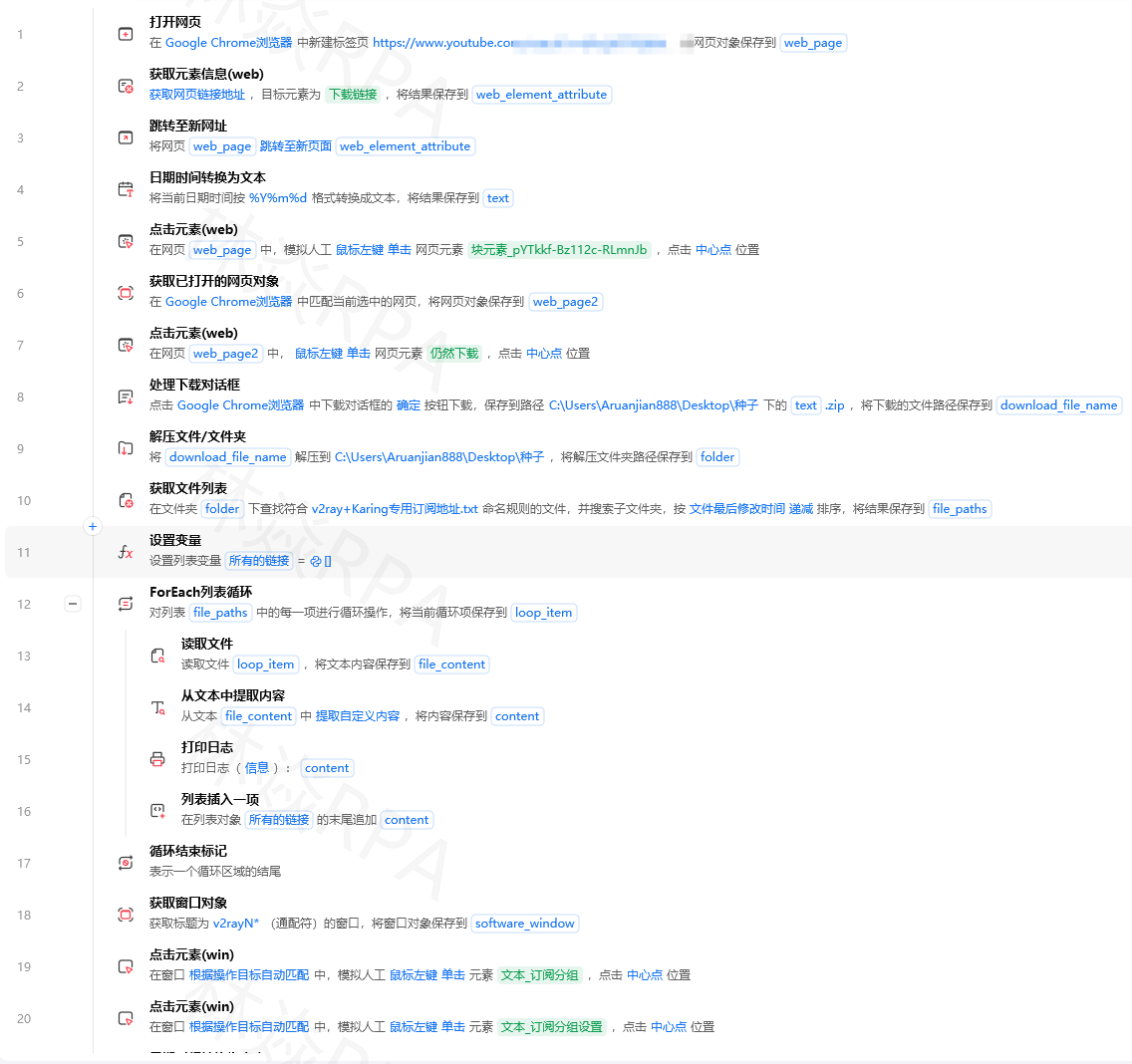价格数字2float(re.search(r\d\.?\d*,价格文本2).group())# 结果99.9价格文本3128价格数字3float(re.search(r\d\.?\d*,价格文本3).group())# 结果128.0正则解释\d\.?\d*\d至少一位数字\.?可选的小数点因为有些价格没有小数位\d*小数点后的数字0位或多位三、从销量文本里提取数字“已拼10万件” → 需要知道它到底是多少件。importredefparse_sales(text):把各种销量文本转成数字textstr(text).replace( ,)# 找数字部分matchre.search(r(\d\.?\d*),text)ifnotmatch:return0numfloat(match.group(1))# 判断单位if万intext:numnum*10000elif亿intext:numnum*100000000returnint(num)# 测试print(parse_sales(已拼10万件))# 100000print(parse_sales(已拼1.2万件))# 12000print(parse_sales(已拼556件))# 556print(parse_sales(即将抢光))# 0四、提取手机号、邮箱、URLimportre# 从文本中提取手机号defextract_phone(text):patternr1[3-9]\d{9}phonesre.findall(pattern,str(text))returnphones[0]ifphoneselse# 从文本中提取邮箱defextract_email(text):patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}emailsre.findall(pattern,str(text))returnemails[0]ifemailselse# 从文本中提取URLdefextract_url(text):patternrhttps?://[^\s{}|\\^\[\]]urlsre.findall(pattern,str(text))returnurls# 测试描述请联系客服微信13800138000或发送邮件到serviceshop.comprint(extract_phone(描述))# 13800138000print(extract_email(描述))# serviceshop.com五、字符串常见处理TEMU店群如何管理运营# 去空格和特殊符号 text 连衣裙 2026新款 texttext.strip()# 去首尾空格连衣裙 2026新款texttext.replace(\n,)# 去掉换行符texttext.replace(\t, )# 把tab换成空格# 截取部分文字 标题【顺丰包邮】夏季连衣裙女法式收腰显瘦2026新款# 去掉【】内容importre 标题re.sub(r【.*?】,,标题)# 夏季连衣裙女法式收腰显瘦2026新款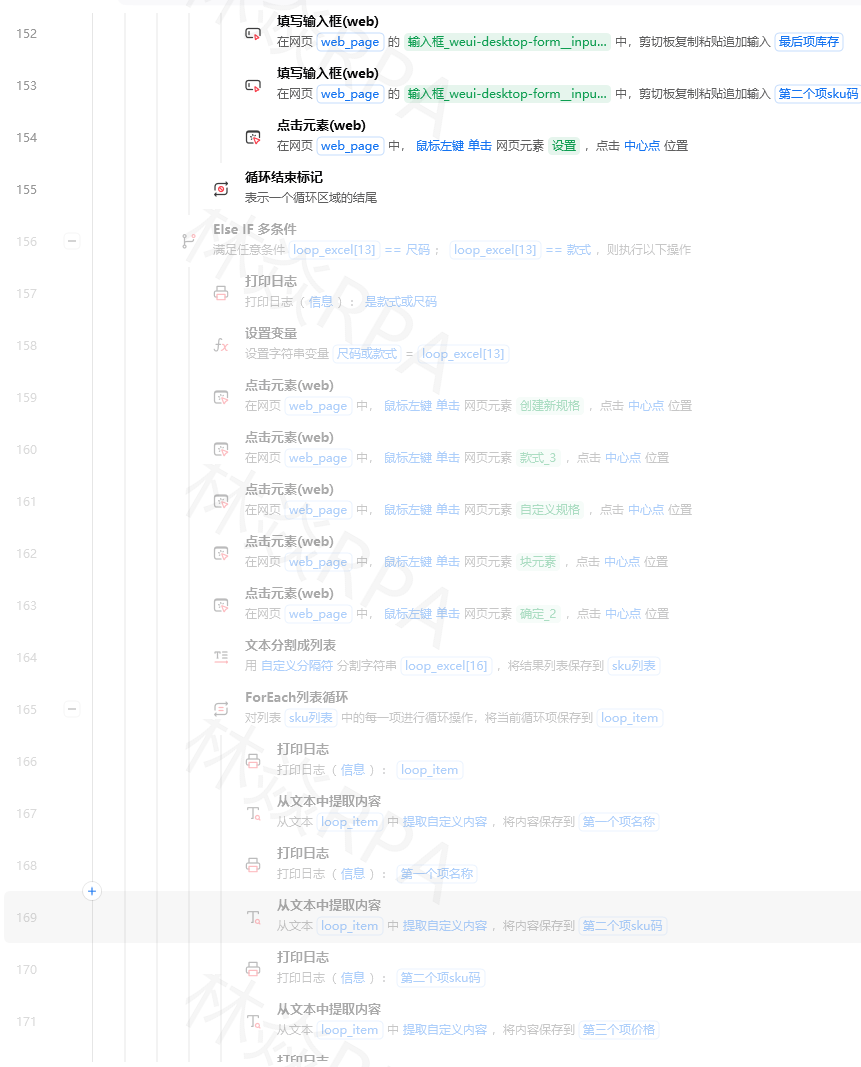# 判断文本包含 if连衣裙in标题and2026in标题:print(是新款连衣裙)# 大小写转换TEMU英文标题 英文标题Womens Summer Dress 2026 New Arrival小写英文标题.lower()# womens summer dress 2026 new arrival大写英文标题.upper()# WOMENS SUMMER DRESS 2026 NEW ARRIVAL六、在采集流程中集成# 影刀流程中采集每条商品时调用Python清洗# Python代码指令 importredefclean_price(price_str):matchre.search(r\d\.?\d*,str(price_str))returnfloat(match.group())ifmatchelse0.0defclean_sales(sales_str):textstr(sales_str)matchre.search(r(\d\.?\d*),text)ifnotmatch:return0numfloat(match.group(1))if万intext:num*10000if亿intext:num*100000000returnint(num)defclean_title(title_str):# 去掉【】[]包裹的内容titlere.sub(r[【\[].*?[】\]],,str(title_str))# 去掉多余空格titlere.sub(r\s, ,title).strip()returntitle# 假设从影刀流程传入raw_price, raw_sales, raw_title清洗后价格clean_price(raw_price)清洗后销量clean_sales(raw_sales)清洗后标题clean_title(raw_title)# 返回清洗后的数据给影刀后续步骤七、常见正则速查表需求正则说明提取数字\d\.?\d*至少一位整数 可选小数点提取手机号1[3-9]\d{9}1开头第二位3-9共11位提取邮箱[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}标准邮箱格式提取URLhttps?://[^\s]http或https开头的链接提取中文[\u4e00-\u9fff]所有中文字符去掉HTML标签[^]匹配HTML标签替换为空去掉空白字符\s空格、tab、换行等作者林焱本文为《影刀RPA学习手册》系列文章之一内容源于实操经验的整理与分享。
影刀RPA进阶教程Python代码指令做数据清洗——正则提取与字符串处理影刀的流程指令处理点击、输入、表格读写都很顺手但一到字符串处理就吃力了。比如从¥128.00里把128提取出来、从已售10万件里提取10万、从一堆描述文字里找到手机号。这些操作用Python的正则表达式re模块一行搞定但有一个前提Python图标要先点亮。一、在影刀里打开Python代码指令影刀流程画布左侧的指令面板里有一个Python代码指令。拖到画布上弹出一个代码编辑器。注意左下角的Python图标必须是亮的。如果灰色点一下它。代码编辑器里可以写任意Python代码流程中前面步骤产生的变量可以通过影刀内置的方式获取。拼多多店群自动化上架方案二、正则表达式入门从字符串里挑数字电商数据清洗里80%的Python需求都是这个# 从各种格式的价格文本里提取数字importre 价格文本¥128.00价格数字float(re.search(r\d\.?\d*,价格文本).group())# 结果128.0价格文本2 99.9起价格数字2float(re.search(r\d\.?\d*,价格文本2).group())# 结果99.9价格文本3128价格数字3float(re.search(r\d\.?\d*,价格文本3).group())# 结果128.0正则解释\d\.?\d*\d至少一位数字\.?可选的小数点因为有些价格没有小数位\d*小数点后的数字0位或多位三、从销量文本里提取数字“已拼10万件” → 需要知道它到底是多少件。importredefparse_sales(text):把各种销量文本转成数字textstr(text).replace( ,)# 找数字部分matchre.search(r(\d\.?\d*),text)ifnotmatch:return0numfloat(match.group(1))# 判断单位if万intext:numnum*10000elif亿intext:numnum*100000000returnint(num)# 测试print(parse_sales(已拼10万件))# 100000print(parse_sales(已拼1.2万件))# 12000print(parse_sales(已拼556件))# 556print(parse_sales(即将抢光))# 0四、提取手机号、邮箱、URLimportre# 从文本中提取手机号defextract_phone(text):patternr1[3-9]\d{9}phonesre.findall(pattern,str(text))returnphones[0]ifphoneselse# 从文本中提取邮箱defextract_email(text):patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}emailsre.findall(pattern,str(text))returnemails[0]ifemailselse# 从文本中提取URLdefextract_url(text):patternrhttps?://[^\s{}|\\^\[\]]urlsre.findall(pattern,str(text))returnurls# 测试描述请联系客服微信13800138000或发送邮件到serviceshop.comprint(extract_phone(描述))# 13800138000print(extract_email(描述))# serviceshop.com五、字符串常见处理TEMU店群如何管理运营# 去空格和特殊符号 text 连衣裙 2026新款 texttext.strip()# 去首尾空格连衣裙 2026新款texttext.replace(\n,)# 去掉换行符texttext.replace(\t, )# 把tab换成空格# 截取部分文字 标题【顺丰包邮】夏季连衣裙女法式收腰显瘦2026新款# 去掉【】内容importre 标题re.sub(r【.*?】,,标题)# 夏季连衣裙女法式收腰显瘦2026新款# 判断文本包含 if连衣裙in标题and2026in标题:print(是新款连衣裙)# 大小写转换TEMU英文标题 英文标题Womens Summer Dress 2026 New Arrival小写英文标题.lower()# womens summer dress 2026 new arrival大写英文标题.upper()# WOMENS SUMMER DRESS 2026 NEW ARRIVAL六、在采集流程中集成# 影刀流程中采集每条商品时调用Python清洗# Python代码指令 importredefclean_price(price_str):matchre.search(r\d\.?\d*,str(price_str))returnfloat(match.group())ifmatchelse0.0defclean_sales(sales_str):textstr(sales_str)matchre.search(r(\d\.?\d*),text)ifnotmatch:return0numfloat(match.group(1))if万intext:num*10000if亿intext:num*100000000returnint(num)defclean_title(title_str):# 去掉【】[]包裹的内容titlere.sub(r[【\[].*?[】\]],,str(title_str))# 去掉多余空格titlere.sub(r\s, ,title).strip()returntitle# 假设从影刀流程传入raw_price, raw_sales, raw_title清洗后价格clean_price(raw_price)清洗后销量clean_sales(raw_sales)清洗后标题clean_title(raw_title)# 返回清洗后的数据给影刀后续步骤七、常见正则速查表需求正则说明提取数字\d\.?\d*至少一位整数 可选小数点提取手机号1[3-9]\d{9}1开头第二位3-9共11位提取邮箱[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}标准邮箱格式提取URLhttps?://[^\s]http或https开头的链接提取中文[\u4e00-\u9fff]所有中文字符去掉HTML标签[^]匹配HTML标签替换为空去掉空白字符\s空格、tab、换行等作者林焱本文为《影刀RPA学习手册》系列文章之一内容源于实操经验的整理与分享。
影刀RPA进阶教程_Python代码指令数据清洗正则字符串处理
发布时间:2026/6/11 10:17:00
影刀RPA进阶教程Python代码指令做数据清洗——正则提取与字符串处理影刀的流程指令处理点击、输入、表格读写都很顺手但一到字符串处理就吃力了。比如从¥128.00里把128提取出来、从已售10万件里提取10万、从一堆描述文字里找到手机号。这些操作用Python的正则表达式re模块一行搞定但有一个前提Python图标要先点亮。一、在影刀里打开Python代码指令影刀流程画布左侧的指令面板里有一个Python代码指令。拖到画布上弹出一个代码编辑器。注意左下角的Python图标必须是亮的。如果灰色点一下它。代码编辑器里可以写任意Python代码流程中前面步骤产生的变量可以通过影刀内置的方式获取。拼多多店群自动化上架方案二、正则表达式入门从字符串里挑数字电商数据清洗里80%的Python需求都是这个# 从各种格式的价格文本里提取数字importre 价格文本¥128.00价格数字float(re.search(r\d\.?\d*,价格文本).group())# 结果128.0价格文本2 99.9起价格数字2float(re.search(r\d\.?\d*,价格文本2).group())# 结果99.9价格文本3128价格数字3float(re.search(r\d\.?\d*,价格文本3).group())# 结果128.0正则解释\d\.?\d*\d至少一位数字\.?可选的小数点因为有些价格没有小数位\d*小数点后的数字0位或多位三、从销量文本里提取数字“已拼10万件” → 需要知道它到底是多少件。importredefparse_sales(text):把各种销量文本转成数字textstr(text).replace( ,)# 找数字部分matchre.search(r(\d\.?\d*),text)ifnotmatch:return0numfloat(match.group(1))# 判断单位if万intext:numnum*10000elif亿intext:numnum*100000000returnint(num)# 测试print(parse_sales(已拼10万件))# 100000print(parse_sales(已拼1.2万件))# 12000print(parse_sales(已拼556件))# 556print(parse_sales(即将抢光))# 0四、提取手机号、邮箱、URLimportre# 从文本中提取手机号defextract_phone(text):patternr1[3-9]\d{9}phonesre.findall(pattern,str(text))returnphones[0]ifphoneselse# 从文本中提取邮箱defextract_email(text):patternr[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}emailsre.findall(pattern,str(text))returnemails[0]ifemailselse# 从文本中提取URLdefextract_url(text):patternrhttps?://[^\s{}|\\^\[\]]urlsre.findall(pattern,str(text))returnurls# 测试描述请联系客服微信13800138000或发送邮件到serviceshop.comprint(extract_phone(描述))# 13800138000print(extract_email(描述))# serviceshop.com五、字符串常见处理TEMU店群如何管理运营# 去空格和特殊符号 text 连衣裙 2026新款 texttext.strip()# 去首尾空格连衣裙 2026新款texttext.replace(\n,)# 去掉换行符texttext.replace(\t, )# 把tab换成空格# 截取部分文字 标题【顺丰包邮】夏季连衣裙女法式收腰显瘦2026新款# 去掉【】内容importre 标题re.sub(r【.*?】,,标题)# 夏季连衣裙女法式收腰显瘦2026新款# 判断文本包含 if连衣裙in标题and2026in标题:print(是新款连衣裙)# 大小写转换TEMU英文标题 英文标题Womens Summer Dress 2026 New Arrival小写英文标题.lower()# womens summer dress 2026 new arrival大写英文标题.upper()# WOMENS SUMMER DRESS 2026 NEW ARRIVAL六、在采集流程中集成# 影刀流程中采集每条商品时调用Python清洗# Python代码指令 importredefclean_price(price_str):matchre.search(r\d\.?\d*,str(price_str))returnfloat(match.group())ifmatchelse0.0defclean_sales(sales_str):textstr(sales_str)matchre.search(r(\d\.?\d*),text)ifnotmatch:return0numfloat(match.group(1))if万intext:num*10000if亿intext:num*100000000returnint(num)defclean_title(title_str):# 去掉【】[]包裹的内容titlere.sub(r[【\[].*?[】\]],,str(title_str))# 去掉多余空格titlere.sub(r\s, ,title).strip()returntitle# 假设从影刀流程传入raw_price, raw_sales, raw_title清洗后价格clean_price(raw_price)清洗后销量clean_sales(raw_sales)清洗后标题clean_title(raw_title)# 返回清洗后的数据给影刀后续步骤七、常见正则速查表需求正则说明提取数字\d\.?\d*至少一位整数 可选小数点提取手机号1[3-9]\d{9}1开头第二位3-9共11位提取邮箱[a-zA-Z0-9._%-][a-zA-Z0-9.-]\.[a-zA-Z]{2,}标准邮箱格式提取URLhttps?://[^\s]http或https开头的链接提取中文[\u4e00-\u9fff]所有中文字符去掉HTML标签[^]匹配HTML标签替换为空去掉空白字符\s空格、tab、换行等作者林焱本文为《影刀RPA学习手册》系列文章之一内容源于实操经验的整理与分享。
相关文章

AI 推理性能调优:KV Cache 优化与显存管理的工程实践
AI 推理性能调优:KV Cache 优化与显存管理的工程实践一、显存墙:为什么大模型推理总是"卡在显存不够" 大模型推理的性能瓶颈往往不是计算力(FLOPS),而是显存带宽与容量。以 Llama-3-8B 为例,模型…
PotPlayer字幕翻译插件终极指南:免费实现实时多语言字幕翻译
PotPlayer字幕翻译插件终极指南:免费实现实时多语言字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer百度…
Java毕设选题推荐:基于jspm网上公路车销售系统【附源码、mysql、文档、调试+代码讲解+全bao等】
博主介绍:✌️码农一枚 ,专注于大学生项目实战开发、讲解和毕业🚢文撰写修改等。全栈领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java、小程序技术领域和毕业项目实战 ✌️技术范围:&am…

实战突破:iTop开源ITSM平台的深度配置管理与企业级运维架构设计
实战突破:iTop开源ITSM平台的深度配置管理与企业级运维架构设计 【免费下载链接】iTop A simple, web based CMDB & IT Service Management tool 项目地址: https://gitcode.com/gh_mirrors/it/iTop 在数字化转型的浪潮中,企业IT运维团队正面…
go2rtc终极指南:打造零延迟的智能摄像头流媒体网关
go2rtc终极指南:打造零延迟的智能摄像头流媒体网关 【免费下载链接】go2rtc Ultimate camera streaming application 项目地址: https://gitcode.com/GitHub_Trending/go/go2rtc 想象一下,你刚刚购买了几个不同品牌的智能摄像头——海康威视、TP-…
SAP Retail 里的 Hierarchy Article,为什么一个价值型商品能承接多个商品分类的销售
在 SAP Retail 项目里,Hierarchy Article 这个概念很容易被低估。它不像普通 Single Article 那样每天被采购员、门店、仓库反复维护,也不像 Generic Article 和 Variant 那样经常出现在服装鞋帽行业的尺码颜色场景里。它更像一个藏在商品分类体系背后的会计和库存承接点,一…
别再手动抄BOM了!用C#+SolidWorks API一键读取Excel明细表(附完整代码)
告别低效:用C#与SolidWorks API实现BOM表自动化提取每次完成装配体设计后,面对屏幕上密密麻麻的BOM表格,你是否也经历过这样的痛苦?机械工程师小张上周花了整整三个小时,盯着屏幕逐行核对Excel明细表,结果还…
COMSOL三维压电悬臂梁频域仿真模板:参数化建模+共振频率扫描+能量采集性能评估
本文还有配套的精品资源,点击获取 简介:直接可用的COMSOL Multiphysics三维仿真模型,专为压电陶瓷悬臂梁在稳态振动下的频域响应分析设计。模型已集成结构力学与静电物理场耦合,内置几何参数(长度、厚度、电极尺寸&…
ECharts饼图数据项太多?试试用渐变色区分系列,提升可读性(附避坑指南)
ECharts饼图多分类场景下的渐变色设计实战指南当我们需要展示公司产品线分布、用户来源渠道等包含5个以上分类的饼图时,相邻色块的颜色区分度不足往往会导致数据阅读困难。本文将深入探讨如何通过精心设计的渐变色方案,在视觉上形成自然过渡和清晰边界&a…

LLM 多轮对话状态管理:从无状态 API 到有状态会话
LLM 多轮对话状态管理:从无状态 API 到有状态会话一、大模型 API 的无状态困境:上下文窗口的有限性与会话连续性 大模型的 Chat API 本质上是无状态的——每次请求都需要发送完整的对话历史。这种设计简化了服务端实现,但给后端架构带来了两个…
Spring Boot 3 与 GraalVM 原生镜像:从 JIT 到 AOT 的启动革命
Spring Boot 3 与 GraalVM 原生镜像:从 JIT 到 AOT 的启动革命 一、JVM 冷启动的性能困境:云原生环境下的启动延迟 Java 应用在云原生环境中面临的核心挑战是冷启动延迟。一个典型的 Spring Boot 2 应用,启动时间约 3-8 秒,内存占…
Go 错误处理与错误链:从哨兵错误到自定义错误类型的工程实践
Go 错误处理与错误链:从哨兵错误到自定义错误类型的工程实践一、Go 错误处理的工程困境:哨兵值与信息丢失 Go 的错误处理采用显式返回值模式,if err ! nil 是每个 Go 开发者最熟悉的代码片段。然而,当项目规模增长后,简…

LED驱动技术全解析:从核心架构到实战选型与避坑指南
1. 从一颗灯珠到千亿市场:LED驱动的技术演进与商业逻辑十几年前,当我第一次从料盘上拿起一颗0603封装的白色LED时,它微弱的光晕和高达几块钱的单颗成本,让我很难想象今天它几乎照亮了我们生活的每一个角落。从手机屏幕的一抹背光&…
索引堆及其优化
索引堆及其优化 引言 索引堆是一种数据结构,广泛应用于计算机科学和软件工程领域。它主要用于解决优先队列问题,如最小堆和最大堆。本文将详细介绍索引堆的概念、实现方法以及优化策略。 索引堆的定义 索引堆是一种基于堆数据结构的索引机制。它通过维护一个堆来存储数据…
从零到日增237精准粉丝,我靠CSDN这张AI卡片爆了!手把手复刻全流程,含配置避坑清单
更多请点击: https://intelliparadigm.com 第一章:CSDN AI 数字营销的官方引流卡片是什么功能? CSDN AI 数字营销平台推出的「官方引流卡片」,是一种面向技术创作者的轻量级、可嵌入式内容分发组件,专为提升博文、教程…

Zotero Duplicates Merger:5步彻底清理文献库重复条目
Zotero Duplicates Merger:5步彻底清理文献库重复条目 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 还在为文献库中堆积如山的重…
利用随机有限集理论对蜂群的ILQR和MPC控制研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室🍊个人信条:格物致知,完整Matlab代码及仿真咨询…
为什么你的Gemini邮件CTE低于行业均值2.8倍?:从Prompt架构到发送时序的深度归因
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini邮件CTE低于行业均值2.8倍?:从Prompt架构到发送时序的深度归因 Gemini邮件的客户转化效率(CTE)显著偏低,根本原因常被误判为…