 分片Chunking是 RAG 中投入产出比最高的优化环节——分片策略对了不改模型、不换 Embedding检索质量就能有明显提升。分片策略错了后续的检索、重排序、Prompt 工程都是垃圾进、垃圾出。本文以 TMC 差旅财务知识库为业务背景梳理五种主流分片方式从最基础的一刀切到 LLM 驱动的智能分片。一、为什么要分片大模型有上下文窗口限制不可能一次把整本《差旅管理制度》塞进去。RAG 的做法是把文档拆成小文本块chunk检索时只取与问题最相关的那几个块拼入 Prompt 交给 LLM。分片是连接海量知识库和有限上下文窗口之间的关键桥梁。它直接影响•检索精度块太大→一个 chunk 含多个不相关主题语义不聚焦检索命中率低块太小→关键上下文被切断LLM 拿到的信息残缺•上下文利用率块太小→需要召回更多 chunk 才能覆盖完整信息消耗大量 token块刚好→几个 chunk 就能回答经济高效•生成质量chunk 的语义完整性决定 LLM 看到的上下文是否自包含、可理解术语说明Chunking、Splitting、分段、分片、分块——都指同一件事本文统一用分片。二、固定大小分片最简单的起点2.1 原理按字符数或 token 数固定切割不管内容是什么。两个参数•chunk_size每个块的字符/ token 数一般 500-1000•chunk_overlap相邻块的重叠字符数一般 50-200overlap 的作用是缓冲——固定切割必然在某个字符处切下overlap 确保切点前后的内容在相邻块中都有出现减少语义断裂。2.2 TMC 示例以系统模块职责.txt为例chunk_size150, overlap5# 付款申请PR流程## PR 的用途PRPayment Request付款申请用于以下场景1. 向供应商付款多数以 EXS 开头的 supplierCode2. 员工报销supplierCode 以 E 开头3. 退票产生的付款## PR 状态流转Raised已提交 → Approved已审批 → Paid已付款已付款后的 PR 可以 Void作废需在 Detail 中写明原因。## 操作标识- 给客户的 PRC Complete- 给供应商的 PRS Complete## 供应商付款详细流程1. 新增供应商设置编号2. 提交付款申请3. 签字审批完成4. AP应付账款根据付款申请做入账PR 状态变更为 Raised5. 审核后状态变更为 Approved6. 出纳付款7. AP 记录状态为 Paid 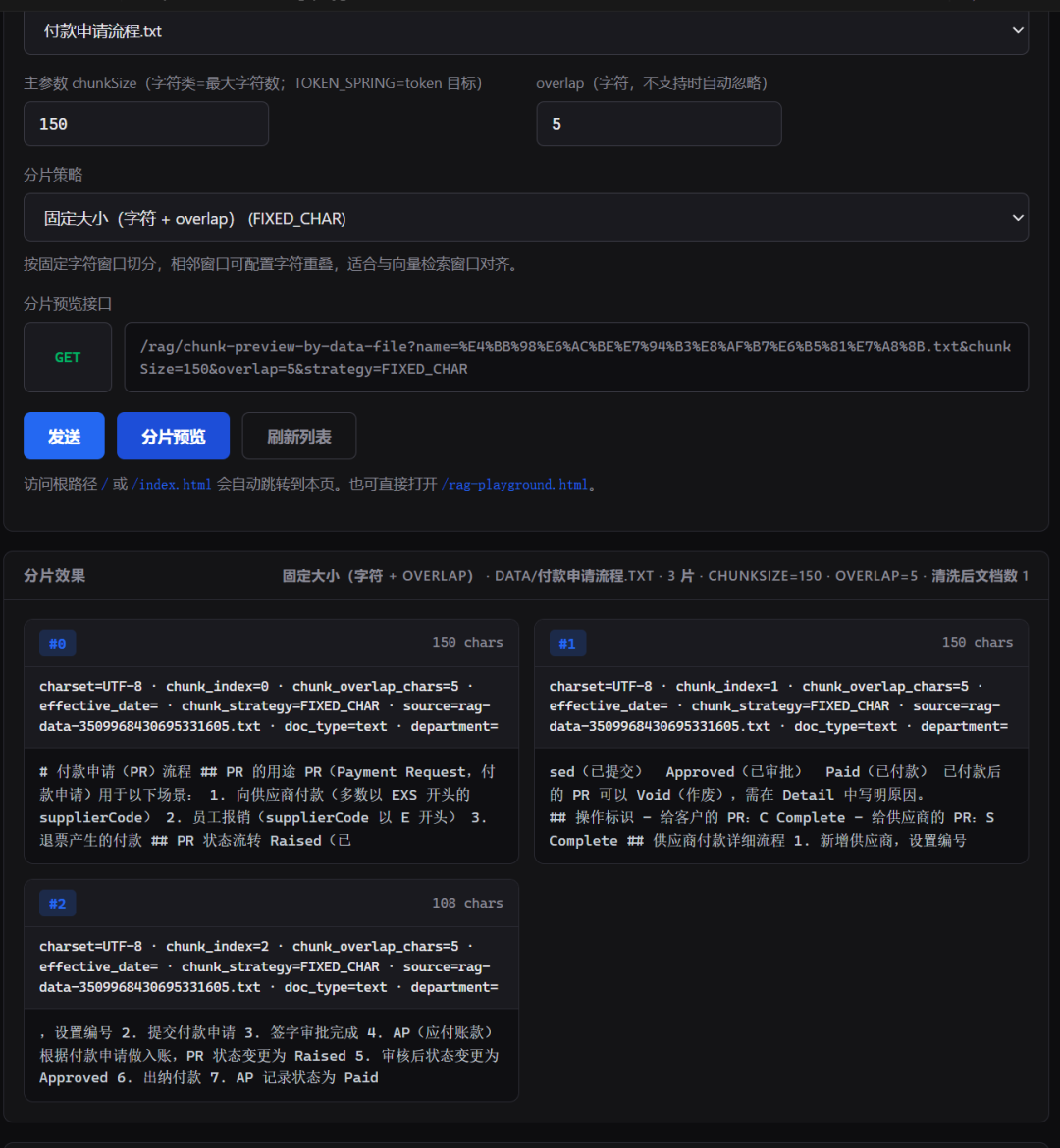 **问题很明显** 连贯的内容被拦腰斩断。“## PR 状态流转 Raised已” 被阶段下一个分块到了“sed已提交 Approved已审批 Paid已付款 已付款后的 PR 可以 Void作废需在 Detail 中写明原因。” ### 2.3 优缺点 | 优点 | 缺点 | | --- | --- | | 实现极其简单 | 完全无视文档结构 | | token 数精确可控 | 常在词语、句子中间切断 | | 适合做 Benchmark 基线 | 语义断裂导致检索召回率低 | **适用场景**仅适合快速原型验证和性能基线对比不建议用于生产环境。 --- 三、递归分片最常用的生产选择 --------------- ### 3.1 原理 指定一组分隔符按优先级逐级尝试切分。只有当当前分隔符无法切出合格大小的块时才降级使用下一个分隔符——这就是递归的含义。 plaintext // Spring AI Alibaba RecursiveCharacterTextSplitter 源码片段public RecursiveCharacterTextSplitter(int chunkSize, String[] separators) { this.chunkSize chunkSize; this.separators Objects.requireNonNullElse(separators, new String[] { \n\n, \n, 。, , , , , });}private void splitText(String text, int separatorIndex, ListString chunks) { if (text.isEmpty()) return; // 1. 如果文本已经够短直接作为一个块 if (text.length() chunkSize) { chunks.add(text); return; } // 2. 所有分隔符都用完了还没切好强制按 chunkSize 切割 if (separatorIndex separators.length) { for (int i 0; i text.length(); i chunkSize) { int end Math.min(i chunkSize, text.length()); chunks.add(text.substring(i, end)); } return; } // 3. 用当前分隔符切分 String separator separators[separatorIndex]; String[] splits text.split(separator); // 4. 递归处理每个分段够短的直接保留太长的用下一个分隔符继续切 for (String split : splits) { if (split.length() chunkSize) { splitText(split, separatorIndex 1, chunks); // 递归 } else { chunks.add(split); } }}递归体现在splitText调用自身分片太长时separatorIndex 1切换到下一级分隔符。相当于先用粗筛子失败了用细筛子再失败直接上刀。3.2 TMC 示例同样系统模块职责.txt使用默认分隔符[\n\n, \n, 。, , , , , ]chunk_size200切割结果Chunk 1:AR应收账款负责对账、生成 CreditNote贷项通知单、收款管理、预付款管理。Chunk 2:AP应付账款负责供应商付款管理、员工报销管理、付款申请PR管理。Chunk 3:GL总账负责手工账管理、系统账管理、科目维护、报表生成。递归分片优先在\n\n段落边界切分AR、AP、GL 各自独立成一个 chunk。用户搜AR 的职责时精准命中 Chunk1不会混入 AP、GL 的内容。3.3 为什么递归分片最常用从主流平台的配置就能看出来平台默认分片方式可调参数百炼智能切分递归语义分段标识符、最大长度、重叠度Dify通用分块递归分段标识符、最大长度、重叠长度Coze自定义分段递归分段标识符、最大长度、重叠长度三个平台的核心分片方案都是递归分片——实现简单、效果可预期、适配大部分文档类型。四、基于文档结构的分片4.1 原理递归分片依赖通用分隔符但 Markdown、HTML、代码等有结构标记的文档可以做得更精准——利用标题层级#/##/###、HTML 标签、代码语法树等结构信息在天然边界上切分。4.2 Markdown 标题分片TMC 推荐TMC 知识库的 5 份文档都是 Markdown 格式按##标题切分是最自然的选择付款申请流程.txt 的结构├── # 付款申请PR流程│ ├── ## PR 的用途 → Chunk 1│ │ ├── 1. 向供应商付款│ │ ├── 2. 员工报销│ │ └── 3. 退票产生的付款│ ├── ## PR 状态流转 → Chunk 2│ │ └── Raised → Approved → Paid → Void│ ├── ## 操作标识 → Chunk 3│ │ ├── C Complete给客户│ │ └── S Complete给供应商│ └── ## 供应商付款详细流程 → Chunk 4│ └── 7 步详细流程按##切分后每个 chunk 包含一个完整的子主题语义自包含。用户问PR 的状态流转Chunk2 被召回内容完整独立。4.3 HTML / 代码分片对于公司 Wiki 上的差旅 FAQHTML或自动化脚本文档Python/JS有专门的解析器// Spring AI MarkdownDocumentReader按标题切分MarkdownDocumentReaderConfig config MarkdownDocumentReaderConfig.builder() .withHorizontalRuleCreateDocument(true) // 水平线也作为分片边界 .withIncludeCodeBlock(false) // 排除代码块 .withIncludeBlockquote(false) // 排除引用 .withAdditionalMetadata(filename, 付款申请流程.txt) .build(); plaintext # LangChainHTML 标题分片from langchain.text_splitter import HTMLHeaderTextSplittersplitter HTMLHeaderTextSplitter( headers_to_split_on[(h1, h1), (h2, h2), (h3, h3)])chunks splitter.split_text(html_content)五、语义分片感知主题边界5.1 原理前面的方式只看结构和字符数不看语义。语义分片的核心思路相邻句子如果语义相似属于同一块相似度陡降就是切分点。句子序列的语义相似度曲线 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 ████████████░░░░██████████████████░░░░░░░ ↑ 都是PR用途 ↑切 ↑ 都是PR状态流转 ↑切实现方式有三种方式原理适用场景Embedding 阈值计算相邻句子的余弦相似度低于阈值则切分叙述性文档计算成本低NLP 句子分割用 OpenNLP 的SentenceDetectorME最大熵模型先拆句再按语义合并中英文混合文档LLM 判断直接让 LLM 标注切分位置并生成每个块的标题复杂嵌套结构的政策文档5.2 TMC 示例预存款与XO核销.txt包含两个截然不同的主题原始文本## 预存款来源1. 超额支付OverPayment结算时付款金额超出发票金额的部分2. 企业预付款销售完成后的预付款余额## 预存款用途1. 后续差旅消费2. 抵扣供应商 XOExchange Order外部订单固定分块可能把两个主题塞进同一个 chunk因为都不长。语义分块则能识别## 预存款来源和## 预存款用途之间的语义跳变在主题切换处切开生成两个独立的、语义聚焦的 chunk——用户搜预存款怎么用时直接命中 Chunk2不混入来源信息。5.3 实际实现// Spring AI / LangChain4J 中的语义分片核心实现SentenceDetectorME sentenceDetector new SentenceDetectorME(sentenceModel);String[] sentences sentenceDetector.sentDetect(text);// 将检测到的句子按 chunk_size 和语义相似度合并底层依赖 OpenNLP 的预训练句子模型opennlp-en-ud-ewt-sentence-1.2-2.5.0.bin基于最大熵模型判断句子边界。六、LLM 驱动的智能分片6.1 Agentic Chunking让大模型做主import com.example.rag.chunk.config.ChunkConfig;import com.example.rag.chunk.config.LlmChunkConfig;import com.example.rag.dto.ParamDescriptor;import com.fasterxml.jackson.core.type.TypeReference;import com.fasterxml.jackson.databind.ObjectMapper;import org.springframework.ai.chat.messages.SystemMessage;import org.springframework.ai.chat.messages.UserMessage;import org.springframework.ai.chat.model.ChatModel;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.ai.document.Document;import org.springframework.beans.factory.ObjectProvider;import org.springframework.stereotype.Component;import java.util.ArrayList;import java.util.LinkedHashMap;import java.util.List;import java.util.Map;import java.util.regex.Matcher;import java.util.regex.Pattern;Componentpublic class LlmGuidedChunkStrategy implements ChunkStrategy { private static final int MAX_PROMPT_CHARS 12_000; private static final Pattern JSON_ARRAY Pattern.compile(\\[\\s*\(?:[^\\\\\]|\\\\.)*\(?:\\s*,\\s*\(?:[^\\\\\]|\\\\.)*\)*\\s*]); private final ObjectProviderChatModel chatModelProvider; private final ObjectMapper objectMapper new ObjectMapper(); public LlmGuidedChunkStrategy(ObjectProviderChatModel chatModelProvider) { this.chatModelProvider chatModelProvider; } Override public String id() { return LLM_SMART; } Override public String label() { return LLM 智能分片; } Override public String description() { return 调用已注册的 Spring AI ChatModel如 DashScope按提示词输出 JSON 字符串数组。overlapHint 在提示中作为软约束不保证严格字符重叠。; } Override public Class? extends ChunkConfig configType() { return LlmChunkConfig.class; } Override public boolean supportsOverlap() { return true; } Override public ListParamDescriptor parameters() { return List.of( new ParamDescriptor(chunkSize, 分片大小字符, int, 400, 200, 12000, LLM 分片的软约束目标字符数), new ParamDescriptor(overlapHint, 重叠提示字符, int, 0, 0, 500, LLM 上下文延续软约束不保证严格字符重叠), new ParamDescriptor(temperature, LLM 温度, double, 0.3, 0, 1, LLM 生成随机性越低越确定0 为确定输出)); } Override public ListDocument split(ListDocument documents, ChunkConfig config) { LlmChunkConfig cfg (LlmChunkConfig) config; ChatModel chatModel chatModelProvider.getIfAvailable(); if (chatModel null) { throw new IllegalStateException(未检测到 ChatModel Bean需配置 spring.ai.dashscope 等无法使用 LLM 分片); } String full ChunkTextMerge.joinText(documents); if (full.isEmpty()) { return List.of(); } int approx cfg.chunkSize(); int overlap cfg.overlapHint(); double temperature cfg.temperature(); String body full.length() MAX_PROMPT_CHARS ? full.substring(0, MAX_PROMPT_CHARS) : full; boolean truncated full.length() MAX_PROMPT_CHARS; SystemMessage system new SystemMessage( You are a text segmentation assistant for RAG. Output ONLY a valid JSON array of strings. Each string is one chunk. Chunks should be coherent topics. Target about approx characters per chunk when possible. If overlap is requested ( overlap ), let neighboring chunks share contextual continuity where natural. No markdown fences, no commentary.); UserMessage user new UserMessage(Document:\n body); // NOTE: 如需将 temperature 传递给 ChatModel可在此处通过 Prompt(Builder).chatOptions(...) 配置 Prompt prompt new Prompt(List.of(system, user)); String raw chatModel.call(prompt).getResult().getOutput().getText(); ListString pieces parseChunks(raw); if (pieces.isEmpty()) { pieces List.of(body.strip()); } MapString, Object base baseMeta(documents); base.put(llm_chunk_overlap_hint, overlap); base.put(llm_temperature, temperature); base.put(llm_input_truncated, truncated); return ChunkTextMerge.annotateIndices(ChunkTextMerge.fromTextPieces(pieces, id(), base)); } private ListString parseChunks(String raw) { if (raw null || raw.isBlank()) { return List.of(); } String trimmed stripCodeFence(raw.trim()); try { return objectMapper.readValue(trimmed, new TypeReference() { }); } catch (Exception ignored) { Matcher m JSON_ARRAY.matcher(trimmed); if (m.find()) { try { return objectMapper.readValue(m.group(), new TypeReference() { }); } catch (Exception ignored2) { // fall through } } } return new ArrayList(); } private static String stripCodeFence(String s) { if (s.startsWith()) { int i s.indexOf(\n); if (i 0) { s s.substring(i 1); } int j s.lastIndexOf(); if (j 0) { s s.substring(0, j).trim(); } } return s; } private static MapString, Object baseMeta(ListDocument documents) { MapString, Object md new LinkedHashMap(); if (!documents.isEmpty()) { md.putAll(new LinkedHashMap(documents.get(0).getMetadata())); } return md; }}把整篇文档交给 LLM让它自主判断在哪些位置切分并为每个块生成标题本手册旨在为您提供车辆操作、安全防护、保养维护等核心信息帮助您安全、高效地使用车辆。请在首次驾驶前通读本手册重点关注标有 “警告”“注意” 的内容相关术语解释可参考正文注释部分。 一、车辆操作基础1.1 点火启动系统本车型采用钥匙式点火启动系统点火开关位于仪表盘右侧具有四个档位操作流程如下• LOCK 档钥匙初始位置全车电路断开可插拔钥匙。• ACC 档顺时针旋转钥匙至第一档音响、车窗等附属电器通电发动机未启动。• ON 档继续旋转至第二档仪表盘指示灯亮起车辆进入自检模式油泵开始工作此过程需保持 3-5 秒。• START 档向前拧动钥匙至第三档并短暂保持不超过 5 秒起动机运转带动发动机启动成功后钥匙会自动回弹至 ON 档。启动注意事项• 启动前需确认手动挡挂空挡、自动挡挂 P 挡拉紧手刹。• 冬季冷启动时建议先拧至 ON 档等待 10 秒待油泵充分工作后再启动减少发动机磨损。• 若连续两次启动失败需间隔 15 秒后重试避免损坏蓄电池。1.2 驾驶舱核心控制• 方向盘按键左侧控制定速巡航右侧调节音响音量、切换曲目及接听蓝牙电话。• 空调系统物理旋钮调节温度与风量按键控制内外循环、除雾功能冬季除霜需开启 AC模式配合热风。• 挡位操作自动挡车型配备传统电子挡把P 挡锁止需踩下刹车解锁行驶中禁止直接切换至 R 挡或 P 挡。 二、安全防护系统2.1 被动安全配置全车配备前排双安全气囊、侧气囊及帘式气囊气囊触发需满足碰撞强度≥30km/h 且角度在±30° 范围内。前排安全带具备预紧功能身高 145cm 以下乘员需配合儿童安全座椅使用安装位置仅限后排座椅。2.2 主动安全提示车辆配备 ABS 防抱死系统与 EBD 制动力分配系统紧急制动时需持续踩下刹车踏板系统会自动调节制动力。雨天行驶需开启 ESP 车身稳定系统按键位于挡把左侧。 三、驾驶与保养规范3.1 驾驶操作指南• 冷车启动后无需长时间怠速热车怠速 30 秒至 1 分钟待转速稳定后即可行驶水温未达正常范围80-90℃时避免急加速。• 城市道路行驶保持与前车 2 秒以上车距高速公路增至 4 秒雨雪天气需加倍并降低车速至 60km/h 以下。• 手动挡车型换挡时需将离合器踩到底时速 20km/h 以下使用 1-2 挡40km/h 以上切换至3-4 挡避免低速高挡导致积碳。3.2 定期保养要求• 机油更换周期为 5000 公里或 6 个月推荐使用 5W-30 标号全合成机油更换时需同步更换机油滤芯。• 轮胎每月检查一次胎压标准值 2.3-2.5bar每 1 万公里进行交叉换位胎纹深度小于1.6 毫米时必须更换。• 蓄电池使用寿命约 3-5 年若出现启动无力、灯光变暗等现象需及时更换原厂蓄电池。 四、紧急情况处理4.1 启动故障排查• 钥匙拧至 ON 档无反应检查蓄电池接线柱是否松动氧化可用热水冲洗氧化物后紧固。• 启动时起动机异响立即停止操作检查钥匙是否完全插入若问题持续需联系售后检修。4.2 轮胎更换流程1. 将车辆停至平坦路面开启双闪灯并放置三角警示牌距离车后 50-150 米。2. 用千斤顶顶起车身至轮胎离地 2-3 厘米拆卸轮毂螺丝时遵循 “对角顺序”安装备胎后需将螺丝分次拧紧。 五、技术参数• 发动机1.5L 自然吸气最大功率 85kW峰值扭矩 148N・m。• 悬架系统前麦弗逊式独立悬架后三连杆独立悬架。• 燃油经济性综合油耗 6.2L/100km油箱容积 52L。注文档部分内容可能由 AI 生成优点语义完整性最好分片结果自带标题后续用标题做 embedding 能大幅提升检索命中率。缺点每次分片需要 LLM 调用成本高、速度慢。适合一次性构建知识库的离线预处理阶段不适合实时文档。6.2 Proposition Chunking拆成原子事实更进一步的方式——不是按主题分块而是把文本拆成不可再分的原子事实每个事实是一个独立的 chunk每个 Proposition 都是独立、自包含的事实陈述。检索时粒度最细精确度最高。代价是 LLM 调用量大chunk 数量爆炸。效果还是不错的七、五种分片方式对比分片方式切割依据语义完整性实现成本TMC 场景推荐固定大小字符/token 数差极低不推荐用于生产仅做基线递归分片分隔符优先级中低通用文本结构不明确的文档文档结构分片标题/标签层级好低Markdown 模块说明、HTML FAQ语义分片语义相似度好中混合主题的长政策文档LLM 智能分片LLM 自主判断极好高知识库初始构建时离线处理选择建议大部分 TMC 场景用文档结构分片按 H2 递归分片兜底即可。只有政策类长文档需要叠加语义分片。LLM 分片适合在初始构建时跑一次后续增量更新用结构分片。八、分片后的下一步分片不是终点。分完的 chunk 要真正好用还有两个关键增强8.1 语境增强CCHchunk 存入向量库后是孤立存在的——丢失了我来自哪的上下文。在每个 chunk 前预置文档级信息原始 Chunk - 供应商付款管理 - 员工报销管理CCH 增强后 [文档系统模块职责 | 章节AP应付账款] - 供应商付款管理 - 员工报销管理8.2 父子分片Hierarchical ChunkingDify 等平台支持的父子分段文档先按大粒度如 H2切成父块每个父块内部再按小粒度如段落切成子块。检索时用子块做精准匹配但返回给 LLM 的是完整的父块上下文。父块H2 层级 ## AP应付账款 供应商付款管理、员工报销管理、付款申请PR管理子块小粒度 员工报销管理供检索匹配用检索命中子块 → 向上找到父块 → 将完整父块拼入 Prompt。这种子检索、父返回的模式兼顾了检索精准度和上下文完整性。2026年AI行业最大的机会毫无疑问就在应用层字节跳动已有7个团队全速布局Agent大模型岗位暴增69%年薪破百万腾讯、京东、百度开放招聘技术岗80%与AI相关……如今超过60%的企业都在推进AI产品落地而真正能交付项目的大模型应用开发工程师****却极度稀缺落地AI应用绝对不是写几个prompt调几个API就能搞定的企业真正需要的是能搞定这三项核心能力的人✅RAG融入外部信息修正模型输出给模型装靠谱大脑✅Agent智能体让AI自主干活通过工具调用Tools环境交互多步推理完成复杂任务。比如做智能客服等等……✅微调针对特定任务优化让模型适配业务目前脉脉上有超过1000家企业发布大模型相关岗位人工智能岗平均月薪7.8w实习生日薪高达4000远超其他行业收入水平技术的稀缺性才是你「值钱」的关键具备AI能力的程序员比传统开发高出不止一截有的人早就转行AI方向拿到百万年薪AI浪潮正在重构程序员的核心竞争力现在入场仍是最佳时机我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】⭐️从大模型微调到AI Agent智能体搭建剖析AI技术的应用场景用实战经验落地AI技术。从GPT到最火的开源模型让你从容面对AI技术革新大模型微调掌握主流大模型如DeepSeek、Qwen等的微调技术针对特定场景优化模型性能。学习如何利用领域数据如制造、医药、金融等进行模型定制提升任务准确性和效率。RAG应用开发深入理解检索增强生成Retrieval-Augmented Generation, RAG技术构建高效的知识检索与生成系统。应用于垂类场景如法律文档分析、医疗诊断辅助、金融报告生成等实现精准信息提取与内容生成。AI Agent智能体搭建学习如何设计和开发AI Agent实现多任务协同、自主决策和复杂问题解决。构建垂类场景下的智能助手如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等。如果你也有以下诉求快速链接产品/业务团队参与前沿项目构建技术壁垒从竞争者中脱颖而出避开35岁裁员危险期顺利拿下高薪岗迭代技术水平延长未来20年的新职业发展……那这节课你一定要来听因为留给普通程序员的时间真的不多了立即扫码即可免费预约「AI技术原理 实战应用 职业发展」「大模型应用开发实战公开课」还有靠谱的内推机会直聘权益完课后赠送大模型应用案例集、AI商业落地白皮书
分片Chunking是 RAG 中投入产出比最高的优化环节——分片策略对了不改模型、不换 Embedding检索质量就能有明显提升。分片策略错了后续的检索、重排序、Prompt 工程都是垃圾进、垃圾出。本文以 TMC 差旅财务知识库为业务背景梳理五种主流分片方式从最基础的一刀切到 LLM 驱动的智能分片。一、为什么要分片大模型有上下文窗口限制不可能一次把整本《差旅管理制度》塞进去。RAG 的做法是把文档拆成小文本块chunk检索时只取与问题最相关的那几个块拼入 Prompt 交给 LLM。分片是连接海量知识库和有限上下文窗口之间的关键桥梁。它直接影响•检索精度块太大→一个 chunk 含多个不相关主题语义不聚焦检索命中率低块太小→关键上下文被切断LLM 拿到的信息残缺•上下文利用率块太小→需要召回更多 chunk 才能覆盖完整信息消耗大量 token块刚好→几个 chunk 就能回答经济高效•生成质量chunk 的语义完整性决定 LLM 看到的上下文是否自包含、可理解术语说明Chunking、Splitting、分段、分片、分块——都指同一件事本文统一用分片。二、固定大小分片最简单的起点2.1 原理按字符数或 token 数固定切割不管内容是什么。两个参数•chunk_size每个块的字符/ token 数一般 500-1000•chunk_overlap相邻块的重叠字符数一般 50-200overlap 的作用是缓冲——固定切割必然在某个字符处切下overlap 确保切点前后的内容在相邻块中都有出现减少语义断裂。2.2 TMC 示例以系统模块职责.txt为例chunk_size150, overlap5# 付款申请PR流程## PR 的用途PRPayment Request付款申请用于以下场景1. 向供应商付款多数以 EXS 开头的 supplierCode2. 员工报销supplierCode 以 E 开头3. 退票产生的付款## PR 状态流转Raised已提交 → Approved已审批 → Paid已付款已付款后的 PR 可以 Void作废需在 Detail 中写明原因。## 操作标识- 给客户的 PRC Complete- 给供应商的 PRS Complete## 供应商付款详细流程1. 新增供应商设置编号2. 提交付款申请3. 签字审批完成4. AP应付账款根据付款申请做入账PR 状态变更为 Raised5. 审核后状态变更为 Approved6. 出纳付款7. AP 记录状态为 Paid  **问题很明显** 连贯的内容被拦腰斩断。“## PR 状态流转 Raised已” 被阶段下一个分块到了“sed已提交 Approved已审批 Paid已付款 已付款后的 PR 可以 Void作废需在 Detail 中写明原因。” ### 2.3 优缺点 | 优点 | 缺点 | | --- | --- | | 实现极其简单 | 完全无视文档结构 | | token 数精确可控 | 常在词语、句子中间切断 | | 适合做 Benchmark 基线 | 语义断裂导致检索召回率低 | **适用场景**仅适合快速原型验证和性能基线对比不建议用于生产环境。 --- 三、递归分片最常用的生产选择 --------------- ### 3.1 原理 指定一组分隔符按优先级逐级尝试切分。只有当当前分隔符无法切出合格大小的块时才降级使用下一个分隔符——这就是递归的含义。 plaintext // Spring AI Alibaba RecursiveCharacterTextSplitter 源码片段public RecursiveCharacterTextSplitter(int chunkSize, String[] separators) { this.chunkSize chunkSize; this.separators Objects.requireNonNullElse(separators, new String[] { \n\n, \n, 。, , , , , });}private void splitText(String text, int separatorIndex, ListString chunks) { if (text.isEmpty()) return; // 1. 如果文本已经够短直接作为一个块 if (text.length() chunkSize) { chunks.add(text); return; } // 2. 所有分隔符都用完了还没切好强制按 chunkSize 切割 if (separatorIndex separators.length) { for (int i 0; i text.length(); i chunkSize) { int end Math.min(i chunkSize, text.length()); chunks.add(text.substring(i, end)); } return; } // 3. 用当前分隔符切分 String separator separators[separatorIndex]; String[] splits text.split(separator); // 4. 递归处理每个分段够短的直接保留太长的用下一个分隔符继续切 for (String split : splits) { if (split.length() chunkSize) { splitText(split, separatorIndex 1, chunks); // 递归 } else { chunks.add(split); } }}递归体现在splitText调用自身分片太长时separatorIndex 1切换到下一级分隔符。相当于先用粗筛子失败了用细筛子再失败直接上刀。3.2 TMC 示例同样系统模块职责.txt使用默认分隔符[\n\n, \n, 。, , , , , ]chunk_size200切割结果Chunk 1:AR应收账款负责对账、生成 CreditNote贷项通知单、收款管理、预付款管理。Chunk 2:AP应付账款负责供应商付款管理、员工报销管理、付款申请PR管理。Chunk 3:GL总账负责手工账管理、系统账管理、科目维护、报表生成。递归分片优先在\n\n段落边界切分AR、AP、GL 各自独立成一个 chunk。用户搜AR 的职责时精准命中 Chunk1不会混入 AP、GL 的内容。3.3 为什么递归分片最常用从主流平台的配置就能看出来平台默认分片方式可调参数百炼智能切分递归语义分段标识符、最大长度、重叠度Dify通用分块递归分段标识符、最大长度、重叠长度Coze自定义分段递归分段标识符、最大长度、重叠长度三个平台的核心分片方案都是递归分片——实现简单、效果可预期、适配大部分文档类型。四、基于文档结构的分片4.1 原理递归分片依赖通用分隔符但 Markdown、HTML、代码等有结构标记的文档可以做得更精准——利用标题层级#/##/###、HTML 标签、代码语法树等结构信息在天然边界上切分。4.2 Markdown 标题分片TMC 推荐TMC 知识库的 5 份文档都是 Markdown 格式按##标题切分是最自然的选择付款申请流程.txt 的结构├── # 付款申请PR流程│ ├── ## PR 的用途 → Chunk 1│ │ ├── 1. 向供应商付款│ │ ├── 2. 员工报销│ │ └── 3. 退票产生的付款│ ├── ## PR 状态流转 → Chunk 2│ │ └── Raised → Approved → Paid → Void│ ├── ## 操作标识 → Chunk 3│ │ ├── C Complete给客户│ │ └── S Complete给供应商│ └── ## 供应商付款详细流程 → Chunk 4│ └── 7 步详细流程按##切分后每个 chunk 包含一个完整的子主题语义自包含。用户问PR 的状态流转Chunk2 被召回内容完整独立。4.3 HTML / 代码分片对于公司 Wiki 上的差旅 FAQHTML或自动化脚本文档Python/JS有专门的解析器// Spring AI MarkdownDocumentReader按标题切分MarkdownDocumentReaderConfig config MarkdownDocumentReaderConfig.builder() .withHorizontalRuleCreateDocument(true) // 水平线也作为分片边界 .withIncludeCodeBlock(false) // 排除代码块 .withIncludeBlockquote(false) // 排除引用 .withAdditionalMetadata(filename, 付款申请流程.txt) .build(); plaintext # LangChainHTML 标题分片from langchain.text_splitter import HTMLHeaderTextSplittersplitter HTMLHeaderTextSplitter( headers_to_split_on[(h1, h1), (h2, h2), (h3, h3)])chunks splitter.split_text(html_content)五、语义分片感知主题边界5.1 原理前面的方式只看结构和字符数不看语义。语义分片的核心思路相邻句子如果语义相似属于同一块相似度陡降就是切分点。句子序列的语义相似度曲线 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 ████████████░░░░██████████████████░░░░░░░ ↑ 都是PR用途 ↑切 ↑ 都是PR状态流转 ↑切实现方式有三种方式原理适用场景Embedding 阈值计算相邻句子的余弦相似度低于阈值则切分叙述性文档计算成本低NLP 句子分割用 OpenNLP 的SentenceDetectorME最大熵模型先拆句再按语义合并中英文混合文档LLM 判断直接让 LLM 标注切分位置并生成每个块的标题复杂嵌套结构的政策文档5.2 TMC 示例预存款与XO核销.txt包含两个截然不同的主题原始文本## 预存款来源1. 超额支付OverPayment结算时付款金额超出发票金额的部分2. 企业预付款销售完成后的预付款余额## 预存款用途1. 后续差旅消费2. 抵扣供应商 XOExchange Order外部订单固定分块可能把两个主题塞进同一个 chunk因为都不长。语义分块则能识别## 预存款来源和## 预存款用途之间的语义跳变在主题切换处切开生成两个独立的、语义聚焦的 chunk——用户搜预存款怎么用时直接命中 Chunk2不混入来源信息。5.3 实际实现// Spring AI / LangChain4J 中的语义分片核心实现SentenceDetectorME sentenceDetector new SentenceDetectorME(sentenceModel);String[] sentences sentenceDetector.sentDetect(text);// 将检测到的句子按 chunk_size 和语义相似度合并底层依赖 OpenNLP 的预训练句子模型opennlp-en-ud-ewt-sentence-1.2-2.5.0.bin基于最大熵模型判断句子边界。六、LLM 驱动的智能分片6.1 Agentic Chunking让大模型做主import com.example.rag.chunk.config.ChunkConfig;import com.example.rag.chunk.config.LlmChunkConfig;import com.example.rag.dto.ParamDescriptor;import com.fasterxml.jackson.core.type.TypeReference;import com.fasterxml.jackson.databind.ObjectMapper;import org.springframework.ai.chat.messages.SystemMessage;import org.springframework.ai.chat.messages.UserMessage;import org.springframework.ai.chat.model.ChatModel;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.ai.document.Document;import org.springframework.beans.factory.ObjectProvider;import org.springframework.stereotype.Component;import java.util.ArrayList;import java.util.LinkedHashMap;import java.util.List;import java.util.Map;import java.util.regex.Matcher;import java.util.regex.Pattern;Componentpublic class LlmGuidedChunkStrategy implements ChunkStrategy { private static final int MAX_PROMPT_CHARS 12_000; private static final Pattern JSON_ARRAY Pattern.compile(\\[\\s*\(?:[^\\\\\]|\\\\.)*\(?:\\s*,\\s*\(?:[^\\\\\]|\\\\.)*\)*\\s*]); private final ObjectProviderChatModel chatModelProvider; private final ObjectMapper objectMapper new ObjectMapper(); public LlmGuidedChunkStrategy(ObjectProviderChatModel chatModelProvider) { this.chatModelProvider chatModelProvider; } Override public String id() { return LLM_SMART; } Override public String label() { return LLM 智能分片; } Override public String description() { return 调用已注册的 Spring AI ChatModel如 DashScope按提示词输出 JSON 字符串数组。overlapHint 在提示中作为软约束不保证严格字符重叠。; } Override public Class? extends ChunkConfig configType() { return LlmChunkConfig.class; } Override public boolean supportsOverlap() { return true; } Override public ListParamDescriptor parameters() { return List.of( new ParamDescriptor(chunkSize, 分片大小字符, int, 400, 200, 12000, LLM 分片的软约束目标字符数), new ParamDescriptor(overlapHint, 重叠提示字符, int, 0, 0, 500, LLM 上下文延续软约束不保证严格字符重叠), new ParamDescriptor(temperature, LLM 温度, double, 0.3, 0, 1, LLM 生成随机性越低越确定0 为确定输出)); } Override public ListDocument split(ListDocument documents, ChunkConfig config) { LlmChunkConfig cfg (LlmChunkConfig) config; ChatModel chatModel chatModelProvider.getIfAvailable(); if (chatModel null) { throw new IllegalStateException(未检测到 ChatModel Bean需配置 spring.ai.dashscope 等无法使用 LLM 分片); } String full ChunkTextMerge.joinText(documents); if (full.isEmpty()) { return List.of(); } int approx cfg.chunkSize(); int overlap cfg.overlapHint(); double temperature cfg.temperature(); String body full.length() MAX_PROMPT_CHARS ? full.substring(0, MAX_PROMPT_CHARS) : full; boolean truncated full.length() MAX_PROMPT_CHARS; SystemMessage system new SystemMessage( You are a text segmentation assistant for RAG. Output ONLY a valid JSON array of strings. Each string is one chunk. Chunks should be coherent topics. Target about approx characters per chunk when possible. If overlap is requested ( overlap ), let neighboring chunks share contextual continuity where natural. No markdown fences, no commentary.); UserMessage user new UserMessage(Document:\n body); // NOTE: 如需将 temperature 传递给 ChatModel可在此处通过 Prompt(Builder).chatOptions(...) 配置 Prompt prompt new Prompt(List.of(system, user)); String raw chatModel.call(prompt).getResult().getOutput().getText(); ListString pieces parseChunks(raw); if (pieces.isEmpty()) { pieces List.of(body.strip()); } MapString, Object base baseMeta(documents); base.put(llm_chunk_overlap_hint, overlap); base.put(llm_temperature, temperature); base.put(llm_input_truncated, truncated); return ChunkTextMerge.annotateIndices(ChunkTextMerge.fromTextPieces(pieces, id(), base)); } private ListString parseChunks(String raw) { if (raw null || raw.isBlank()) { return List.of(); } String trimmed stripCodeFence(raw.trim()); try { return objectMapper.readValue(trimmed, new TypeReference() { }); } catch (Exception ignored) { Matcher m JSON_ARRAY.matcher(trimmed); if (m.find()) { try { return objectMapper.readValue(m.group(), new TypeReference() { }); } catch (Exception ignored2) { // fall through } } } return new ArrayList(); } private static String stripCodeFence(String s) { if (s.startsWith()) { int i s.indexOf(\n); if (i 0) { s s.substring(i 1); } int j s.lastIndexOf(); if (j 0) { s s.substring(0, j).trim(); } } return s; } private static MapString, Object baseMeta(ListDocument documents) { MapString, Object md new LinkedHashMap(); if (!documents.isEmpty()) { md.putAll(new LinkedHashMap(documents.get(0).getMetadata())); } return md; }}把整篇文档交给 LLM让它自主判断在哪些位置切分并为每个块生成标题本手册旨在为您提供车辆操作、安全防护、保养维护等核心信息帮助您安全、高效地使用车辆。请在首次驾驶前通读本手册重点关注标有 “警告”“注意” 的内容相关术语解释可参考正文注释部分。 一、车辆操作基础1.1 点火启动系统本车型采用钥匙式点火启动系统点火开关位于仪表盘右侧具有四个档位操作流程如下• LOCK 档钥匙初始位置全车电路断开可插拔钥匙。• ACC 档顺时针旋转钥匙至第一档音响、车窗等附属电器通电发动机未启动。• ON 档继续旋转至第二档仪表盘指示灯亮起车辆进入自检模式油泵开始工作此过程需保持 3-5 秒。• START 档向前拧动钥匙至第三档并短暂保持不超过 5 秒起动机运转带动发动机启动成功后钥匙会自动回弹至 ON 档。启动注意事项• 启动前需确认手动挡挂空挡、自动挡挂 P 挡拉紧手刹。• 冬季冷启动时建议先拧至 ON 档等待 10 秒待油泵充分工作后再启动减少发动机磨损。• 若连续两次启动失败需间隔 15 秒后重试避免损坏蓄电池。1.2 驾驶舱核心控制• 方向盘按键左侧控制定速巡航右侧调节音响音量、切换曲目及接听蓝牙电话。• 空调系统物理旋钮调节温度与风量按键控制内外循环、除雾功能冬季除霜需开启 AC模式配合热风。• 挡位操作自动挡车型配备传统电子挡把P 挡锁止需踩下刹车解锁行驶中禁止直接切换至 R 挡或 P 挡。 二、安全防护系统2.1 被动安全配置全车配备前排双安全气囊、侧气囊及帘式气囊气囊触发需满足碰撞强度≥30km/h 且角度在±30° 范围内。前排安全带具备预紧功能身高 145cm 以下乘员需配合儿童安全座椅使用安装位置仅限后排座椅。2.2 主动安全提示车辆配备 ABS 防抱死系统与 EBD 制动力分配系统紧急制动时需持续踩下刹车踏板系统会自动调节制动力。雨天行驶需开启 ESP 车身稳定系统按键位于挡把左侧。 三、驾驶与保养规范3.1 驾驶操作指南• 冷车启动后无需长时间怠速热车怠速 30 秒至 1 分钟待转速稳定后即可行驶水温未达正常范围80-90℃时避免急加速。• 城市道路行驶保持与前车 2 秒以上车距高速公路增至 4 秒雨雪天气需加倍并降低车速至 60km/h 以下。• 手动挡车型换挡时需将离合器踩到底时速 20km/h 以下使用 1-2 挡40km/h 以上切换至3-4 挡避免低速高挡导致积碳。3.2 定期保养要求• 机油更换周期为 5000 公里或 6 个月推荐使用 5W-30 标号全合成机油更换时需同步更换机油滤芯。• 轮胎每月检查一次胎压标准值 2.3-2.5bar每 1 万公里进行交叉换位胎纹深度小于1.6 毫米时必须更换。• 蓄电池使用寿命约 3-5 年若出现启动无力、灯光变暗等现象需及时更换原厂蓄电池。 四、紧急情况处理4.1 启动故障排查• 钥匙拧至 ON 档无反应检查蓄电池接线柱是否松动氧化可用热水冲洗氧化物后紧固。• 启动时起动机异响立即停止操作检查钥匙是否完全插入若问题持续需联系售后检修。4.2 轮胎更换流程1. 将车辆停至平坦路面开启双闪灯并放置三角警示牌距离车后 50-150 米。2. 用千斤顶顶起车身至轮胎离地 2-3 厘米拆卸轮毂螺丝时遵循 “对角顺序”安装备胎后需将螺丝分次拧紧。 五、技术参数• 发动机1.5L 自然吸气最大功率 85kW峰值扭矩 148N・m。• 悬架系统前麦弗逊式独立悬架后三连杆独立悬架。• 燃油经济性综合油耗 6.2L/100km油箱容积 52L。注文档部分内容可能由 AI 生成优点语义完整性最好分片结果自带标题后续用标题做 embedding 能大幅提升检索命中率。缺点每次分片需要 LLM 调用成本高、速度慢。适合一次性构建知识库的离线预处理阶段不适合实时文档。6.2 Proposition Chunking拆成原子事实更进一步的方式——不是按主题分块而是把文本拆成不可再分的原子事实每个事实是一个独立的 chunk每个 Proposition 都是独立、自包含的事实陈述。检索时粒度最细精确度最高。代价是 LLM 调用量大chunk 数量爆炸。效果还是不错的七、五种分片方式对比分片方式切割依据语义完整性实现成本TMC 场景推荐固定大小字符/token 数差极低不推荐用于生产仅做基线递归分片分隔符优先级中低通用文本结构不明确的文档文档结构分片标题/标签层级好低Markdown 模块说明、HTML FAQ语义分片语义相似度好中混合主题的长政策文档LLM 智能分片LLM 自主判断极好高知识库初始构建时离线处理选择建议大部分 TMC 场景用文档结构分片按 H2 递归分片兜底即可。只有政策类长文档需要叠加语义分片。LLM 分片适合在初始构建时跑一次后续增量更新用结构分片。八、分片后的下一步分片不是终点。分完的 chunk 要真正好用还有两个关键增强8.1 语境增强CCHchunk 存入向量库后是孤立存在的——丢失了我来自哪的上下文。在每个 chunk 前预置文档级信息原始 Chunk - 供应商付款管理 - 员工报销管理CCH 增强后 [文档系统模块职责 | 章节AP应付账款] - 供应商付款管理 - 员工报销管理8.2 父子分片Hierarchical ChunkingDify 等平台支持的父子分段文档先按大粒度如 H2切成父块每个父块内部再按小粒度如段落切成子块。检索时用子块做精准匹配但返回给 LLM 的是完整的父块上下文。父块H2 层级 ## AP应付账款 供应商付款管理、员工报销管理、付款申请PR管理子块小粒度 员工报销管理供检索匹配用检索命中子块 → 向上找到父块 → 将完整父块拼入 Prompt。这种子检索、父返回的模式兼顾了检索精准度和上下文完整性。2026年AI行业最大的机会毫无疑问就在应用层字节跳动已有7个团队全速布局Agent大模型岗位暴增69%年薪破百万腾讯、京东、百度开放招聘技术岗80%与AI相关……如今超过60%的企业都在推进AI产品落地而真正能交付项目的大模型应用开发工程师****却极度稀缺落地AI应用绝对不是写几个prompt调几个API就能搞定的企业真正需要的是能搞定这三项核心能力的人✅RAG融入外部信息修正模型输出给模型装靠谱大脑✅Agent智能体让AI自主干活通过工具调用Tools环境交互多步推理完成复杂任务。比如做智能客服等等……✅微调针对特定任务优化让模型适配业务目前脉脉上有超过1000家企业发布大模型相关岗位人工智能岗平均月薪7.8w实习生日薪高达4000远超其他行业收入水平技术的稀缺性才是你「值钱」的关键具备AI能力的程序员比传统开发高出不止一截有的人早就转行AI方向拿到百万年薪AI浪潮正在重构程序员的核心竞争力现在入场仍是最佳时机我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】⭐️从大模型微调到AI Agent智能体搭建剖析AI技术的应用场景用实战经验落地AI技术。从GPT到最火的开源模型让你从容面对AI技术革新大模型微调掌握主流大模型如DeepSeek、Qwen等的微调技术针对特定场景优化模型性能。学习如何利用领域数据如制造、医药、金融等进行模型定制提升任务准确性和效率。RAG应用开发深入理解检索增强生成Retrieval-Augmented Generation, RAG技术构建高效的知识检索与生成系统。应用于垂类场景如法律文档分析、医疗诊断辅助、金融报告生成等实现精准信息提取与内容生成。AI Agent智能体搭建学习如何设计和开发AI Agent实现多任务协同、自主决策和复杂问题解决。构建垂类场景下的智能助手如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等。如果你也有以下诉求快速链接产品/业务团队参与前沿项目构建技术壁垒从竞争者中脱颖而出避开35岁裁员危险期顺利拿下高薪岗迭代技术水平延长未来20年的新职业发展……那这节课你一定要来听因为留给普通程序员的时间真的不多了立即扫码即可免费预约「AI技术原理 实战应用 职业发展」「大模型应用开发实战公开课」还有靠谱的内推机会直聘权益完课后赠送大模型应用案例集、AI商业落地白皮书
分片策略决定 RAG 效率:5 种主流方式详解,从基础到 LLM 驱动智能分片
发布时间:2026/6/16 0:29:27
分片Chunking是 RAG 中投入产出比最高的优化环节——分片策略对了不改模型、不换 Embedding检索质量就能有明显提升。分片策略错了后续的检索、重排序、Prompt 工程都是垃圾进、垃圾出。本文以 TMC 差旅财务知识库为业务背景梳理五种主流分片方式从最基础的一刀切到 LLM 驱动的智能分片。一、为什么要分片大模型有上下文窗口限制不可能一次把整本《差旅管理制度》塞进去。RAG 的做法是把文档拆成小文本块chunk检索时只取与问题最相关的那几个块拼入 Prompt 交给 LLM。分片是连接海量知识库和有限上下文窗口之间的关键桥梁。它直接影响•检索精度块太大→一个 chunk 含多个不相关主题语义不聚焦检索命中率低块太小→关键上下文被切断LLM 拿到的信息残缺•上下文利用率块太小→需要召回更多 chunk 才能覆盖完整信息消耗大量 token块刚好→几个 chunk 就能回答经济高效•生成质量chunk 的语义完整性决定 LLM 看到的上下文是否自包含、可理解术语说明Chunking、Splitting、分段、分片、分块——都指同一件事本文统一用分片。二、固定大小分片最简单的起点2.1 原理按字符数或 token 数固定切割不管内容是什么。两个参数•chunk_size每个块的字符/ token 数一般 500-1000•chunk_overlap相邻块的重叠字符数一般 50-200overlap 的作用是缓冲——固定切割必然在某个字符处切下overlap 确保切点前后的内容在相邻块中都有出现减少语义断裂。2.2 TMC 示例以系统模块职责.txt为例chunk_size150, overlap5# 付款申请PR流程## PR 的用途PRPayment Request付款申请用于以下场景1. 向供应商付款多数以 EXS 开头的 supplierCode2. 员工报销supplierCode 以 E 开头3. 退票产生的付款## PR 状态流转Raised已提交 → Approved已审批 → Paid已付款已付款后的 PR 可以 Void作废需在 Detail 中写明原因。## 操作标识- 给客户的 PRC Complete- 给供应商的 PRS Complete## 供应商付款详细流程1. 新增供应商设置编号2. 提交付款申请3. 签字审批完成4. AP应付账款根据付款申请做入账PR 状态变更为 Raised5. 审核后状态变更为 Approved6. 出纳付款7. AP 记录状态为 Paid  **问题很明显** 连贯的内容被拦腰斩断。“## PR 状态流转 Raised已” 被阶段下一个分块到了“sed已提交 Approved已审批 Paid已付款 已付款后的 PR 可以 Void作废需在 Detail 中写明原因。” ### 2.3 优缺点 | 优点 | 缺点 | | --- | --- | | 实现极其简单 | 完全无视文档结构 | | token 数精确可控 | 常在词语、句子中间切断 | | 适合做 Benchmark 基线 | 语义断裂导致检索召回率低 | **适用场景**仅适合快速原型验证和性能基线对比不建议用于生产环境。 --- 三、递归分片最常用的生产选择 --------------- ### 3.1 原理 指定一组分隔符按优先级逐级尝试切分。只有当当前分隔符无法切出合格大小的块时才降级使用下一个分隔符——这就是递归的含义。 plaintext // Spring AI Alibaba RecursiveCharacterTextSplitter 源码片段public RecursiveCharacterTextSplitter(int chunkSize, String[] separators) { this.chunkSize chunkSize; this.separators Objects.requireNonNullElse(separators, new String[] { \n\n, \n, 。, , , , , });}private void splitText(String text, int separatorIndex, ListString chunks) { if (text.isEmpty()) return; // 1. 如果文本已经够短直接作为一个块 if (text.length() chunkSize) { chunks.add(text); return; } // 2. 所有分隔符都用完了还没切好强制按 chunkSize 切割 if (separatorIndex separators.length) { for (int i 0; i text.length(); i chunkSize) { int end Math.min(i chunkSize, text.length()); chunks.add(text.substring(i, end)); } return; } // 3. 用当前分隔符切分 String separator separators[separatorIndex]; String[] splits text.split(separator); // 4. 递归处理每个分段够短的直接保留太长的用下一个分隔符继续切 for (String split : splits) { if (split.length() chunkSize) { splitText(split, separatorIndex 1, chunks); // 递归 } else { chunks.add(split); } }}递归体现在splitText调用自身分片太长时separatorIndex 1切换到下一级分隔符。相当于先用粗筛子失败了用细筛子再失败直接上刀。3.2 TMC 示例同样系统模块职责.txt使用默认分隔符[\n\n, \n, 。, , , , , ]chunk_size200切割结果Chunk 1:AR应收账款负责对账、生成 CreditNote贷项通知单、收款管理、预付款管理。Chunk 2:AP应付账款负责供应商付款管理、员工报销管理、付款申请PR管理。Chunk 3:GL总账负责手工账管理、系统账管理、科目维护、报表生成。递归分片优先在\n\n段落边界切分AR、AP、GL 各自独立成一个 chunk。用户搜AR 的职责时精准命中 Chunk1不会混入 AP、GL 的内容。3.3 为什么递归分片最常用从主流平台的配置就能看出来平台默认分片方式可调参数百炼智能切分递归语义分段标识符、最大长度、重叠度Dify通用分块递归分段标识符、最大长度、重叠长度Coze自定义分段递归分段标识符、最大长度、重叠长度三个平台的核心分片方案都是递归分片——实现简单、效果可预期、适配大部分文档类型。四、基于文档结构的分片4.1 原理递归分片依赖通用分隔符但 Markdown、HTML、代码等有结构标记的文档可以做得更精准——利用标题层级#/##/###、HTML 标签、代码语法树等结构信息在天然边界上切分。4.2 Markdown 标题分片TMC 推荐TMC 知识库的 5 份文档都是 Markdown 格式按##标题切分是最自然的选择付款申请流程.txt 的结构├── # 付款申请PR流程│ ├── ## PR 的用途 → Chunk 1│ │ ├── 1. 向供应商付款│ │ ├── 2. 员工报销│ │ └── 3. 退票产生的付款│ ├── ## PR 状态流转 → Chunk 2│ │ └── Raised → Approved → Paid → Void│ ├── ## 操作标识 → Chunk 3│ │ ├── C Complete给客户│ │ └── S Complete给供应商│ └── ## 供应商付款详细流程 → Chunk 4│ └── 7 步详细流程按##切分后每个 chunk 包含一个完整的子主题语义自包含。用户问PR 的状态流转Chunk2 被召回内容完整独立。4.3 HTML / 代码分片对于公司 Wiki 上的差旅 FAQHTML或自动化脚本文档Python/JS有专门的解析器// Spring AI MarkdownDocumentReader按标题切分MarkdownDocumentReaderConfig config MarkdownDocumentReaderConfig.builder() .withHorizontalRuleCreateDocument(true) // 水平线也作为分片边界 .withIncludeCodeBlock(false) // 排除代码块 .withIncludeBlockquote(false) // 排除引用 .withAdditionalMetadata(filename, 付款申请流程.txt) .build(); plaintext # LangChainHTML 标题分片from langchain.text_splitter import HTMLHeaderTextSplittersplitter HTMLHeaderTextSplitter( headers_to_split_on[(h1, h1), (h2, h2), (h3, h3)])chunks splitter.split_text(html_content)五、语义分片感知主题边界5.1 原理前面的方式只看结构和字符数不看语义。语义分片的核心思路相邻句子如果语义相似属于同一块相似度陡降就是切分点。句子序列的语义相似度曲线 S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 ████████████░░░░██████████████████░░░░░░░ ↑ 都是PR用途 ↑切 ↑ 都是PR状态流转 ↑切实现方式有三种方式原理适用场景Embedding 阈值计算相邻句子的余弦相似度低于阈值则切分叙述性文档计算成本低NLP 句子分割用 OpenNLP 的SentenceDetectorME最大熵模型先拆句再按语义合并中英文混合文档LLM 判断直接让 LLM 标注切分位置并生成每个块的标题复杂嵌套结构的政策文档5.2 TMC 示例预存款与XO核销.txt包含两个截然不同的主题原始文本## 预存款来源1. 超额支付OverPayment结算时付款金额超出发票金额的部分2. 企业预付款销售完成后的预付款余额## 预存款用途1. 后续差旅消费2. 抵扣供应商 XOExchange Order外部订单固定分块可能把两个主题塞进同一个 chunk因为都不长。语义分块则能识别## 预存款来源和## 预存款用途之间的语义跳变在主题切换处切开生成两个独立的、语义聚焦的 chunk——用户搜预存款怎么用时直接命中 Chunk2不混入来源信息。5.3 实际实现// Spring AI / LangChain4J 中的语义分片核心实现SentenceDetectorME sentenceDetector new SentenceDetectorME(sentenceModel);String[] sentences sentenceDetector.sentDetect(text);// 将检测到的句子按 chunk_size 和语义相似度合并底层依赖 OpenNLP 的预训练句子模型opennlp-en-ud-ewt-sentence-1.2-2.5.0.bin基于最大熵模型判断句子边界。六、LLM 驱动的智能分片6.1 Agentic Chunking让大模型做主import com.example.rag.chunk.config.ChunkConfig;import com.example.rag.chunk.config.LlmChunkConfig;import com.example.rag.dto.ParamDescriptor;import com.fasterxml.jackson.core.type.TypeReference;import com.fasterxml.jackson.databind.ObjectMapper;import org.springframework.ai.chat.messages.SystemMessage;import org.springframework.ai.chat.messages.UserMessage;import org.springframework.ai.chat.model.ChatModel;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.ai.document.Document;import org.springframework.beans.factory.ObjectProvider;import org.springframework.stereotype.Component;import java.util.ArrayList;import java.util.LinkedHashMap;import java.util.List;import java.util.Map;import java.util.regex.Matcher;import java.util.regex.Pattern;Componentpublic class LlmGuidedChunkStrategy implements ChunkStrategy { private static final int MAX_PROMPT_CHARS 12_000; private static final Pattern JSON_ARRAY Pattern.compile(\\[\\s*\(?:[^\\\\\]|\\\\.)*\(?:\\s*,\\s*\(?:[^\\\\\]|\\\\.)*\)*\\s*]); private final ObjectProviderChatModel chatModelProvider; private final ObjectMapper objectMapper new ObjectMapper(); public LlmGuidedChunkStrategy(ObjectProviderChatModel chatModelProvider) { this.chatModelProvider chatModelProvider; } Override public String id() { return LLM_SMART; } Override public String label() { return LLM 智能分片; } Override public String description() { return 调用已注册的 Spring AI ChatModel如 DashScope按提示词输出 JSON 字符串数组。overlapHint 在提示中作为软约束不保证严格字符重叠。; } Override public Class? extends ChunkConfig configType() { return LlmChunkConfig.class; } Override public boolean supportsOverlap() { return true; } Override public ListParamDescriptor parameters() { return List.of( new ParamDescriptor(chunkSize, 分片大小字符, int, 400, 200, 12000, LLM 分片的软约束目标字符数), new ParamDescriptor(overlapHint, 重叠提示字符, int, 0, 0, 500, LLM 上下文延续软约束不保证严格字符重叠), new ParamDescriptor(temperature, LLM 温度, double, 0.3, 0, 1, LLM 生成随机性越低越确定0 为确定输出)); } Override public ListDocument split(ListDocument documents, ChunkConfig config) { LlmChunkConfig cfg (LlmChunkConfig) config; ChatModel chatModel chatModelProvider.getIfAvailable(); if (chatModel null) { throw new IllegalStateException(未检测到 ChatModel Bean需配置 spring.ai.dashscope 等无法使用 LLM 分片); } String full ChunkTextMerge.joinText(documents); if (full.isEmpty()) { return List.of(); } int approx cfg.chunkSize(); int overlap cfg.overlapHint(); double temperature cfg.temperature(); String body full.length() MAX_PROMPT_CHARS ? full.substring(0, MAX_PROMPT_CHARS) : full; boolean truncated full.length() MAX_PROMPT_CHARS; SystemMessage system new SystemMessage( You are a text segmentation assistant for RAG. Output ONLY a valid JSON array of strings. Each string is one chunk. Chunks should be coherent topics. Target about approx characters per chunk when possible. If overlap is requested ( overlap ), let neighboring chunks share contextual continuity where natural. No markdown fences, no commentary.); UserMessage user new UserMessage(Document:\n body); // NOTE: 如需将 temperature 传递给 ChatModel可在此处通过 Prompt(Builder).chatOptions(...) 配置 Prompt prompt new Prompt(List.of(system, user)); String raw chatModel.call(prompt).getResult().getOutput().getText(); ListString pieces parseChunks(raw); if (pieces.isEmpty()) { pieces List.of(body.strip()); } MapString, Object base baseMeta(documents); base.put(llm_chunk_overlap_hint, overlap); base.put(llm_temperature, temperature); base.put(llm_input_truncated, truncated); return ChunkTextMerge.annotateIndices(ChunkTextMerge.fromTextPieces(pieces, id(), base)); } private ListString parseChunks(String raw) { if (raw null || raw.isBlank()) { return List.of(); } String trimmed stripCodeFence(raw.trim()); try { return objectMapper.readValue(trimmed, new TypeReference() { }); } catch (Exception ignored) { Matcher m JSON_ARRAY.matcher(trimmed); if (m.find()) { try { return objectMapper.readValue(m.group(), new TypeReference() { }); } catch (Exception ignored2) { // fall through } } } return new ArrayList(); } private static String stripCodeFence(String s) { if (s.startsWith()) { int i s.indexOf(\n); if (i 0) { s s.substring(i 1); } int j s.lastIndexOf(); if (j 0) { s s.substring(0, j).trim(); } } return s; } private static MapString, Object baseMeta(ListDocument documents) { MapString, Object md new LinkedHashMap(); if (!documents.isEmpty()) { md.putAll(new LinkedHashMap(documents.get(0).getMetadata())); } return md; }}把整篇文档交给 LLM让它自主判断在哪些位置切分并为每个块生成标题本手册旨在为您提供车辆操作、安全防护、保养维护等核心信息帮助您安全、高效地使用车辆。请在首次驾驶前通读本手册重点关注标有 “警告”“注意” 的内容相关术语解释可参考正文注释部分。 一、车辆操作基础1.1 点火启动系统本车型采用钥匙式点火启动系统点火开关位于仪表盘右侧具有四个档位操作流程如下• LOCK 档钥匙初始位置全车电路断开可插拔钥匙。• ACC 档顺时针旋转钥匙至第一档音响、车窗等附属电器通电发动机未启动。• ON 档继续旋转至第二档仪表盘指示灯亮起车辆进入自检模式油泵开始工作此过程需保持 3-5 秒。• START 档向前拧动钥匙至第三档并短暂保持不超过 5 秒起动机运转带动发动机启动成功后钥匙会自动回弹至 ON 档。启动注意事项• 启动前需确认手动挡挂空挡、自动挡挂 P 挡拉紧手刹。• 冬季冷启动时建议先拧至 ON 档等待 10 秒待油泵充分工作后再启动减少发动机磨损。• 若连续两次启动失败需间隔 15 秒后重试避免损坏蓄电池。1.2 驾驶舱核心控制• 方向盘按键左侧控制定速巡航右侧调节音响音量、切换曲目及接听蓝牙电话。• 空调系统物理旋钮调节温度与风量按键控制内外循环、除雾功能冬季除霜需开启 AC模式配合热风。• 挡位操作自动挡车型配备传统电子挡把P 挡锁止需踩下刹车解锁行驶中禁止直接切换至 R 挡或 P 挡。 二、安全防护系统2.1 被动安全配置全车配备前排双安全气囊、侧气囊及帘式气囊气囊触发需满足碰撞强度≥30km/h 且角度在±30° 范围内。前排安全带具备预紧功能身高 145cm 以下乘员需配合儿童安全座椅使用安装位置仅限后排座椅。2.2 主动安全提示车辆配备 ABS 防抱死系统与 EBD 制动力分配系统紧急制动时需持续踩下刹车踏板系统会自动调节制动力。雨天行驶需开启 ESP 车身稳定系统按键位于挡把左侧。 三、驾驶与保养规范3.1 驾驶操作指南• 冷车启动后无需长时间怠速热车怠速 30 秒至 1 分钟待转速稳定后即可行驶水温未达正常范围80-90℃时避免急加速。• 城市道路行驶保持与前车 2 秒以上车距高速公路增至 4 秒雨雪天气需加倍并降低车速至 60km/h 以下。• 手动挡车型换挡时需将离合器踩到底时速 20km/h 以下使用 1-2 挡40km/h 以上切换至3-4 挡避免低速高挡导致积碳。3.2 定期保养要求• 机油更换周期为 5000 公里或 6 个月推荐使用 5W-30 标号全合成机油更换时需同步更换机油滤芯。• 轮胎每月检查一次胎压标准值 2.3-2.5bar每 1 万公里进行交叉换位胎纹深度小于1.6 毫米时必须更换。• 蓄电池使用寿命约 3-5 年若出现启动无力、灯光变暗等现象需及时更换原厂蓄电池。 四、紧急情况处理4.1 启动故障排查• 钥匙拧至 ON 档无反应检查蓄电池接线柱是否松动氧化可用热水冲洗氧化物后紧固。• 启动时起动机异响立即停止操作检查钥匙是否完全插入若问题持续需联系售后检修。4.2 轮胎更换流程1. 将车辆停至平坦路面开启双闪灯并放置三角警示牌距离车后 50-150 米。2. 用千斤顶顶起车身至轮胎离地 2-3 厘米拆卸轮毂螺丝时遵循 “对角顺序”安装备胎后需将螺丝分次拧紧。 五、技术参数• 发动机1.5L 自然吸气最大功率 85kW峰值扭矩 148N・m。• 悬架系统前麦弗逊式独立悬架后三连杆独立悬架。• 燃油经济性综合油耗 6.2L/100km油箱容积 52L。注文档部分内容可能由 AI 生成优点语义完整性最好分片结果自带标题后续用标题做 embedding 能大幅提升检索命中率。缺点每次分片需要 LLM 调用成本高、速度慢。适合一次性构建知识库的离线预处理阶段不适合实时文档。6.2 Proposition Chunking拆成原子事实更进一步的方式——不是按主题分块而是把文本拆成不可再分的原子事实每个事实是一个独立的 chunk每个 Proposition 都是独立、自包含的事实陈述。检索时粒度最细精确度最高。代价是 LLM 调用量大chunk 数量爆炸。效果还是不错的七、五种分片方式对比分片方式切割依据语义完整性实现成本TMC 场景推荐固定大小字符/token 数差极低不推荐用于生产仅做基线递归分片分隔符优先级中低通用文本结构不明确的文档文档结构分片标题/标签层级好低Markdown 模块说明、HTML FAQ语义分片语义相似度好中混合主题的长政策文档LLM 智能分片LLM 自主判断极好高知识库初始构建时离线处理选择建议大部分 TMC 场景用文档结构分片按 H2 递归分片兜底即可。只有政策类长文档需要叠加语义分片。LLM 分片适合在初始构建时跑一次后续增量更新用结构分片。八、分片后的下一步分片不是终点。分完的 chunk 要真正好用还有两个关键增强8.1 语境增强CCHchunk 存入向量库后是孤立存在的——丢失了我来自哪的上下文。在每个 chunk 前预置文档级信息原始 Chunk - 供应商付款管理 - 员工报销管理CCH 增强后 [文档系统模块职责 | 章节AP应付账款] - 供应商付款管理 - 员工报销管理8.2 父子分片Hierarchical ChunkingDify 等平台支持的父子分段文档先按大粒度如 H2切成父块每个父块内部再按小粒度如段落切成子块。检索时用子块做精准匹配但返回给 LLM 的是完整的父块上下文。父块H2 层级 ## AP应付账款 供应商付款管理、员工报销管理、付款申请PR管理子块小粒度 员工报销管理供检索匹配用检索命中子块 → 向上找到父块 → 将完整父块拼入 Prompt。这种子检索、父返回的模式兼顾了检索精准度和上下文完整性。2026年AI行业最大的机会毫无疑问就在应用层字节跳动已有7个团队全速布局Agent大模型岗位暴增69%年薪破百万腾讯、京东、百度开放招聘技术岗80%与AI相关……如今超过60%的企业都在推进AI产品落地而真正能交付项目的大模型应用开发工程师****却极度稀缺落地AI应用绝对不是写几个prompt调几个API就能搞定的企业真正需要的是能搞定这三项核心能力的人✅RAG融入外部信息修正模型输出给模型装靠谱大脑✅Agent智能体让AI自主干活通过工具调用Tools环境交互多步推理完成复杂任务。比如做智能客服等等……✅微调针对特定任务优化让模型适配业务目前脉脉上有超过1000家企业发布大模型相关岗位人工智能岗平均月薪7.8w实习生日薪高达4000远超其他行业收入水平技术的稀缺性才是你「值钱」的关键具备AI能力的程序员比传统开发高出不止一截有的人早就转行AI方向拿到百万年薪AI浪潮正在重构程序员的核心竞争力现在入场仍是最佳时机我把大模型的学习全流程已经整理好了抓住AI时代风口轻松解锁职业新可能希望大家都能把握机遇实现薪资/职业跃迁这份完整版的大模型 AI 学习资料已经上传CSDN朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】⭐️从大模型微调到AI Agent智能体搭建剖析AI技术的应用场景用实战经验落地AI技术。从GPT到最火的开源模型让你从容面对AI技术革新大模型微调掌握主流大模型如DeepSeek、Qwen等的微调技术针对特定场景优化模型性能。学习如何利用领域数据如制造、医药、金融等进行模型定制提升任务准确性和效率。RAG应用开发深入理解检索增强生成Retrieval-Augmented Generation, RAG技术构建高效的知识检索与生成系统。应用于垂类场景如法律文档分析、医疗诊断辅助、金融报告生成等实现精准信息提取与内容生成。AI Agent智能体搭建学习如何设计和开发AI Agent实现多任务协同、自主决策和复杂问题解决。构建垂类场景下的智能助手如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等。如果你也有以下诉求快速链接产品/业务团队参与前沿项目构建技术壁垒从竞争者中脱颖而出避开35岁裁员危险期顺利拿下高薪岗迭代技术水平延长未来20年的新职业发展……那这节课你一定要来听因为留给普通程序员的时间真的不多了立即扫码即可免费预约「AI技术原理 实战应用 职业发展」「大模型应用开发实战公开课」还有靠谱的内推机会直聘权益完课后赠送大模型应用案例集、AI商业落地白皮书
相关文章

AI 数据库性能诊断:从指标异常到根因定位的智能化路径
AI 数据库性能诊断:从指标异常到根因定位的智能化路径 一、数据库排障的经验瓶颈:指标太多,根因太少 数据库性能问题的典型表现是"慢了"——查询延迟升高、连接池耗尽、CPU 满载。但"慢了"只是症状,根因可能来…
数据建模怎么做?一文解析8种经典数据建模方法
AI能力越往业务一线渗透,企业的数据治理水平就越藏不住。数据标准是否统一,口径是否一致,链路是否清晰,最终都会体现在分析结果和模型效果上。而在整个数据治理体系里,数据建模是非常关键的一环。它不只是把数据整理成…
太仓市高新技术企业认定的所需材料及申报流程
一、高新技术企业认定基本条件在准备材料之前,企业应先对照《高新技术企业认定管理办法》(国科发火〔2016〕32号)第十一条进行自我评价,确认是否满足以下核心条件:1.成立时间:注册成立一年(365个…

沙箱环境(详细介绍)
目录 一、基本定义 二、核心特性 三、常见分类 & 应用场景 1. 软件开发 / 接口类沙箱(最常用) 2. 测试环境沙箱(测试域) 3. 安全沙箱(安全防护) 4. 系统 / 应用沙箱 5. 金融 / 风控沙箱 四、沙…
飞思卡尔DSPI寄存器实战:从HCR、CTAR到FIFO,驱动SPI外设全解析
1. 项目概述:从手册到实战,拆解DSPI核心寄存器如果你正在使用飞思卡尔(现恩智浦)的PXS20系列微控制器,或者任何基于其内核的芯片,并且需要驱动SPI外设,那么你大概率绕不开一个模块:D…
数据分析师是业务与数据之间的翻译官
1. 这份职业到底在解决什么真实问题?——从超市收银台说起你有没有注意过,每次在超市结账时,收银员扫完商品条码,屏幕右下角会跳出一行小字:“您本次消费中,有3件商品参与‘满99减15’活动”?或…
【新手入门】SQL注入之报错注入
【新手入门】SQL注入之报错注入 一、概念 报错注入指在MYSQL中使用一些指定的函数来制造报错,从而从报错信息中获取设定的信息。 常见的select/insert/update/delete注入都可以使用报错方式来获取信息。为什么要用函数报错? 是因为我们之前学到的一些注入…
2026 GEO第三方度量平台解析:主流工具选型与功能详解
当AI对话模型逐步成为消费者了解品牌、筛选产品的重要入口,大众的信息获取方式已经发生明显转变。用户不再局限于传统网页检索,而是直接向各类大模型咨询品牌对比、产品推荐等问题。品牌在AI回答中的曝光状态、推荐位置以及信息引用来源,都会潜移默化影响用户的消费决策。目前,…
MSC711x AHB-Lite Crossbar Switch仲裁机制详解与性能调优
1. 项目概述与核心价值在嵌入式系统,尤其是像MSC711x这类集成了高性能DSP核心、多通道DMA以及丰富外设的复杂SoC设计中,一个核心的挑战是如何让多个“发号施令者”(主设备,Master)高效、有序地访问共享的“资源库”&am…

《LangChain 系列》Human-in-the-loop:什么时候必须让人工介入?
前面几章我们已经把 Agent、Tool、LangGraph 都讲完了。现在要补上最关键的一环:人工介入。 没有 HITL 的 Agent,很像没有刹车的自动驾驶。它能跑,也可能跑得很快,但真正上线会让人害怕。 企业里最危险的不是模型回答错一句话&a…
3步彻底移除Windows Defender:终极Windows Defender Remover使用指南
3步彻底移除Windows Defender:终极Windows Defender Remover使用指南 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/…
永春堂商业模式积分系统介绍:从理念到实践的转变
永春堂商业模式系统小程序开发方案:合规化健康零售服务平台技术实现指南 本方案依托永春堂品牌大健康产品(如营养补充剂、草本洗护、五谷杂粮等普通食品/日化品类) 找演示:看专栏⬆️ 一、系统定位:去层级化、重产品…

音乐文件解锁实战指南:3个场景解决你的播放困境
音乐文件解锁实战指南:3个场景解决你的播放困境 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://git…
从Landsat到高分系列:手把手教你选择适合自己项目的遥感卫星数据
遥感卫星数据选型实战指南:从参数解析到场景化应用当面对GEE、PIE-Engine等云平台上数十种遥感数据源时,许多研究者常陷入选择困难——Landsat的历史连续性、Sentinel-2的红边波段优势、高分系列的亚米级分辨率各有千秋。本文将打破常规参数罗列式对比&a…
MC68302 AutoBaud技术:硬件级串口波特率自动检测原理与实现
1. 项目概述:MC68302 AutoBaud技术深度解析在嵌入式系统开发,尤其是那些需要与外部设备进行串口通信的场景里,最让人头疼的环节之一就是波特率匹配。想象一下,你设计了一个数据采集终端,需要连接来自不同厂家、不同年代…

Zotero Duplicates Merger:5步彻底清理文献库重复条目
Zotero Duplicates Merger:5步彻底清理文献库重复条目 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 还在为文献库中堆积如山的重…
利用随机有限集理论对蜂群的ILQR和MPC控制研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室🍊个人信条:格物致知,完整Matlab代码及仿真咨询…
为什么你的Gemini邮件CTE低于行业均值2.8倍?:从Prompt架构到发送时序的深度归因
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini邮件CTE低于行业均值2.8倍?:从Prompt架构到发送时序的深度归因 Gemini邮件的客户转化效率(CTE)显著偏低,根本原因常被误判为…