第一篇文章学习 小绿鲸阅读器 通篇使用chatgpt生成答案
文章: https://arxiv.org/pdf/2012.15404
1. 文章概述
本文提出了一种基于Distilled BERT模型的统一普通话文本到语音前端模块。该模型通过预训练的中文BERT作为文本编码器,并采用多任务学习技术来适应TTS前端的两个重要任务:韵律结构预测(PSP)和字素到音素转换(G2P)。然后,通过使用TinyBERT的知识蒸馏技术将BERT编码器压缩为更小的模型,使整个模型的大小仅为基准前端模型的25%,同时在两个任务上保持竞争性能。通过这些方法,我们能够以轻量且统一的方式运行整个TTS前端模块,更适合在移动设备上部署。
2. 研究背景
本篇文章的研究背景是关于中文文本到语音合成(TTS)系统中前端模块的研究。前端模块在中文TTS系统中起着重要作用,它包括韵律结构预测(PSP)和字音转换(G2P)两个主要任务。传统的前端模块通常由多个文本处理组件组成,需要大量的工作来构建,并且容易导致模型累积和级联错误。因此,本文提出了一种基于预训练语言模型(PLM)的模型,同时解决了TTS前端的两个重要任务,即PSP和G2P。通过使用预训练的中文BERT作为文本编码器,并采用多任务学习技术来适应这两个任务,将BERT编码器通过知识蒸馏技术(TinyBERT)压缩为更小的模型,使整个模型的大小只有基准模型的25%,同时在两个任务上保持竞争性能。这种方法使得整个TTS前端模块能够以轻量和统一的方式运行,更适合在移动设备上部署。
3. 研究思路
本研究的研究思路是基于预训练语言模型(PLM)的方法,提出了一种基于中文BERT的统一普通话文本到语音(TTS)前端模型。该模型同时解决了TTS前端中最重要的两个任务,即韵律结构预测(PSP)和字音转换(G2P)。我们使用预训练的中文BERT作为文本编码器,并采用多任务学习技术将其适应于这两个TTS前端任务。然后,通过使用一种名为TinyBERT的知识蒸馏技术,将BERT编码器压缩为更小的模型,使整个模型的大小只有基准流水线模型的25%,同时在两个任务上保持竞争性能。
本研究解决了TTS前端模块的复杂性和模型累积大小的问题。传统的TTS前端模块通常由一系列独立的文本处理组件组成,需要大量的工作来构建,并容易产生大量的模型和级联错误。而我们提出的方法通过使用预训练语言模型,将PSP和G2P这两个组件统一起来,简化了整个TTS前端模块的结构。同时,通过知识蒸馏技术将模型压缩,使得模型在保持竞争性能的同时,模型大小只有基准流水线模型的25%。这使得整个TTS前端模块更轻量化和统一化,更适合在移动设备上部署。
4. 研究结果
这篇文章介绍了一个基于Distilled BERT模型的统一普通话TTS前端模型,并详细描述了每个步骤的研究结果。
1. 文章首先介绍了使用预训练的中文BERT模型进行文本编码的方法,并指出该模型能够捕捉到普通话语言的上下文和语义信息,从而有助于后续的NLP任务(如PSP和G2P任务)。
2. 接下来,文章介绍了多音字消歧的方法。通过使用BERT模型提取丰富的上下文特征,结合多层感知机(MLP)和softmax层,将多音字的发音预测任务转化为分类问题。实验结果表明,该方法在多音字消歧准确率上取得了显著的提升。
3. 文章还介绍了韵律结构预测的方法。通过假设每个字符后面都存在一个韵律断点,并使用四个类别的标签进行韵律断点的预测。实验结果表明,该方法在韵律结构预测的F1分数上取得了较好的表现。
此外,文章还进行了实验验证,使用了不同的系统进行多音字消歧和韵律结构预测,并对比了它们的性能。实验结果表明,基于Distilled BERT模型的多任务学习模型在多音字消歧和韵律结构预测任务上取得了优秀的结果,证明了实验的假设。
5. 研究结论与讨论
1、研究结论:本文的研究结论是通过使用基于Distilled BERT模型的统一前端模型,可以同时解决TTS前端中最重要的两个任务:韵律结构预测(PSP)和字音转换(G2P)。通过多任务学习技术,将预训练的中文BERT模型适应到这两个任务上,并通过TinyBERT知识蒸馏技术将BERT模型压缩成更小的模型,使整个模型的大小只有基准流水线模型的25%,同时在两个任务上保持竞争性能。
2、研究的创新性:本研究的创新性包括以下几个方面:
- 提出了基于Distilled BERT模型的统一前端模型,将PSP和G2P任务统一建模,简化了TTS前端的复杂性。
- 使用预训练的中文BERT模型作为文本编码器,并通过多任务学习技术适应到PSP和G2P任务上,提高了模型的性能。
- 利用TinyBERT知识蒸馏技术将BERT模型压缩,减小了模型的存储和计算开销,更适合在移动设备上部署。
3、研究的不足之处:本研究的不足之处包括:
- 本文没有详细讨论模型的具体实现细节和超参数选择,可能对读者的复现工作造成一定的困难。
- 本文只针对中文进行了研究,对于其他语言的TTS前端任务的适应性还需要进一步研究和验证。
4、研究展望:根据这项研究,后续可能的研究方向包括:
- 进一步优化模型的性能,尤其是在处理长文本和复杂语境下的表现。
- 探索更多的知识蒸馏技术,以进一步压缩模型并提高模型的效率和速度。
- 将该方法应用于其他语言的TTS前端任务,并进行性能评估和比较。
- 结合其他前端任务,如情感分析和语义理解,构建更全面的TTS前端模型。
5、研究意义:本研究的理论意义和实践意义包括:
- 理论意义:通过将PSP和G2P任务统一建模,提出了一种简化和统一的TTS前端模型,为TTS领域的研究提供了新的思路和方法。
- 实践意义:通过使用Distilled BERT模型和TinyBERT知识蒸馏技术,可以将TTS前端模型的大小和计算开销大大减小,更适合在移动设备等资源受限的环境中部署和应用。
遇到的术语解释
1. F1 score
polyphone disambiguation and F1 score of PW, PPH, IPH for prosodic structure. F1 score是什么 怎么计算的?
F1 Score
F1 Score 是一种用于评估分类模型性能的指标,它是精确率(Precision)和召回率(Recall)的调和平均数。F1 Score 的取值范围是0到1,1表示模型性能最佳。
计算公式
F1 Score 的计算公式如下:
[ \text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} ]
其中:
-
Precision(精确率):正确预测的正样本数占所有预测为正样本数的比例。
[ \text{Precision} = \frac{TP}{TP + FP} ] -
Recall(召回率):正确预测的正样本数占所有实际为正样本数的比例。
[ \text{Recall} = \frac{TP}{TP + FN} ]
在这些公式中:
- TP(True Positives):正确预测为正样本的数量。
- FP(False Positives):错误预测为正样本的数量。
- FN(False Negatives):漏掉的正样本数量。
例子
假设我们有以下分类结果:
- True Positives (TP): 80
- False Positives (FP): 20
- False Negatives (FN): 10
我们可以计算 Precision 和 Recall:
Precision = T P T P + F P = 80 80 + 20 = 80 100 = 0.8 \text{Precision} = \frac{TP}{TP + FP} = \frac{80}{80 + 20} = \frac{80}{100} = 0.8 Precision=TP+FPTP=80+2080=10080=0.8
Recall = T P T P + F N = 80 80 + 10 = 80 90 ≈ 0.89 \text{Recall} = \frac{TP}{TP + FN} = \frac{80}{80 + 10} = \frac{80}{90} \approx 0.89 Recall=TP+FNTP=80+1080=9080≈0.89
然后,使用这些值计算 F1 Score:
F1 Score = 2 × Precision × Recall Precision + Recall = 2 × 0.8 × 0.89 0.8 + 0.89 ≈ 0.84 \text{F1 Score} = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} = 2 \times \frac{0.8 \times 0.89}{0.8 + 0.89} \approx 0.84 F1 Score=2×Precision+RecallPrecision×Recall=2×0.8+0.890.8×0.89≈0.84
多音字消歧和韵律结构的 F1 Score
在 TTS(Text-to-Speech)系统中,特别是涉及多音字消歧(polyphone disambiguation)和韵律结构(prosodic structure)评估时,F1 Score 常用于评估不同层次的韵律结构预测的性能,如:
- PW (Prosodic Word):韵律词
- PPH (Prosodic Phrase):韵律短语
- IPH (Intonational Phrase):语调短语
对于每一个韵律层次,可以分别计算 Precision、Recall 和 F1 Score,以评估模型在不同层次上的性能。
实际应用
假设我们有一个模型,用于预测韵律词(PW),韵律短语(PPH),和语调短语(IPH)的边界。我们可以根据模型的预测和实际标签计算每个层次的 TP、FP 和 FN,进而计算出 Precision、Recall 和 F1 Score。
例如,假设我们有以下预测和实际标签:
- PW:TP = 50, FP = 10, FN = 5
- PPH:TP = 40, FP = 15, FN = 10
- IPH:TP = 30, FP = 20, FN = 15
那么,我们可以分别计算每个层次的 F1 Score:
PW Precision = 50 50 + 10 = 50 60 = 0.83 \text{PW Precision} = \frac{50}{50 + 10} = \frac{50}{60} = 0.83 PW Precision=50+1050=6050=0.83
PW Recall = 50 50 + 5 = 50 55 = 0.91 \text{PW Recall} = \frac{50}{50 + 5} = \frac{50}{55} = 0.91 PW Recall=50+550=5550=0.91
PW F1 Score = 2 × 0.83 × 0.91 0.83 + 0.91 ≈ 0.87 \text{PW F1 Score} = 2 \times \frac{0.83 \times 0.91}{0.83 + 0.91} \approx 0.87 PW F1 Score=2×0.83+0.910.83×0.91≈0.87
以此类推,可以计算出 PPH 和 IPH 的 Precision、Recall 和 F1 Score。
通过这样的计算,可以全面了解模型在不同层次上的表现,并据此进行优化和改进。
2. F2 score
F2 Score 是一种用于评估分类模型性能的指标,它是 Precision(精确率)和 Recall(召回率)的加权调和平均数。与 F1 Score 不同的是,F2 Score 更加重视 Recall。
计算公式
F2 Score 的计算公式如下:
F2 Score = ( 1 + 2 2 ) × Precision × Recall 2 2 × Precision + Recall \text{F2 Score} = \frac{(1 + 2^2) \times \text{Precision} \times \text{Recall}}{2^2 \times \text{Precision} + \text{Recall}} F2 Score=22×Precision+Recall(1+22)×Precision×Recall
由于 β = 2 \beta = 2 β=2,这个公式可以简化为:
F2 Score = 5 × Precision × Recall 4 × Precision + Recall \text{F2 Score} = \frac{5 \times \text{Precision} \times \text{Recall}}{4 \times \text{Precision} + \text{Recall}} F2 Score=4×Precision+Recall5×Precision×Recall
其中:
-
Precision(精确率):正确预测的正样本数占所有预测为正样本数的比例。
Precision = T P T P + F P \text{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP -
Recall(召回率):正确预测的正样本数占所有实际为正样本数的比例。
Recall = T P T P + F N \text{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP
在这些公式中:
- TP(True Positives):正确预测为正样本的数量。
- FP(False Positives):错误预测为正样本的数量。
- FN(False Negatives):漏掉的正样本数量。
例子
假设我们有以下分类结果:
- True Positives (TP): 80
- False Positives (FP): 20
- False Negatives (FN): 10
我们可以计算 Precision 和 Recall:
Precision = T P T P + F P = 80 80 + 20 = 80 100 = 0.8 \text{Precision} = \frac{TP}{TP + FP} = \frac{80}{80 + 20} = \frac{80}{100} = 0.8 Precision=TP+FPTP=80+2080=10080=0.8
Recall = T P T P + F N = 80 80 + 10 = 80 90 ≈ 0.89 \text{Recall} = \frac{TP}{TP + FN} = \frac{80}{80 + 10} = \frac{80}{90} \approx 0.89 Recall=TP+FNTP=80+1080=9080≈0.89
然后,使用这些值计算 F2 Score:
F2 Score = 5 × Precision × Recall 4 × Precision + Recall = 5 × 0.8 × 0.89 4 × 0.8 + 0.89 ≈ 0.85 \text{F2 Score} = \frac{5 \times \text{Precision} \times \text{Recall}}{4 \times \text{Precision} + \text{Recall}} = \frac{5 \times 0.8 \times 0.89}{4 \times 0.8 + 0.89} \approx 0.85 F2 Score=4×Precision+Recall5×Precision×Recall=4×0.8+0.895×0.8×0.89≈0.85
何时使用 F2 Score
F2 Score 在以下情况下尤为有用:
- 需要更多关注召回率时:在某些应用中,错过正样本的代价较高(如医疗诊断、欺诈检测),因此需要更高的召回率。在这种情况下,F2 Score 比 F1 Score 更适合。
- 数据不平衡时:当正样本比负样本稀少时,F2 Score 可以更好地评估模型的性能,因为它更加关注召回率。
总结
F2 Score 是一个偏重于召回率的评估指标,通过增加 Recall 的权重,适用于需要特别关注召回率的应用场景。它的计算公式与 F1 Score 类似,但通过加权调和平均数更突出 Recall 的重要性。
3. BLSTM是什么模型
BLSTM(Bidirectional Long Short-Term Memory)是一种双向长短期记忆网络,是在传统的 LSTM(Long Short-Term Memory)基础上发展起来的。LSTM 是一种特殊的递归神经网络(RNN),它通过引入门控机制来有效解决 RNN 中的长时依赖问题。BLSTM 则进一步增强了 LSTM 的能力,使其能够从输入序列的前后两个方向进行信息处理,从而捕捉更多的上下文信息。
LSTM 简介
LSTM 通过其独特的门控结构(包括输入门、遗忘门和输出门),有效地控制信息在时间步之间的流动,从而解决了传统 RNN 中的梯度消失和梯度爆炸问题。LSTM 的结构使其能够在时间步之间记住和传递重要的信息,同时忽略无关的信息。
双向 LSTM (BLSTM)
BLSTM 是在 LSTM 的基础上引入双向处理的一种架构。BLSTM 包含两个独立的 LSTM 网络,一个从前向后处理序列,另一个从后向前处理序列。这样,BLSTM 能够同时利用前后的上下文信息进行预测或分类。
BLSTM 的架构
- 前向 LSTM(Forward LSTM):从时间步 t = 1 t = 1 t=1 到 t = T t = T t=T逐步处理输入序列。
- 后向 LSTM(Backward LSTM):从时间步 t = T t = T t=T 到 t = 1 t = 1 t=1 反向处理输入序列。
这两个 LSTM 网络的输出通常会在每个时间步进行拼接或其他形式的组合,从而得到一个包含前后文信息的输出。
BLSTM 的优势
- 捕捉上下文信息:通过同时处理前向和后向的序列,BLSTM 可以捕捉到比单向 LSTM 更丰富的上下文信息。
- 提高模型性能:在许多自然语言处理(NLP)任务中,如语音识别、文本生成和命名实体识别,BLSTM 通常表现优于单向 LSTM,因为它能够更好地理解句子的整体结构和上下文关系。
BLSTM 的应用
BLSTM 在许多任务中都表现出色,特别是在需要捕捉上下文信息的序列处理任务中。以下是一些常见的应用领域:
- 语音识别:BLSTM 能够同时考虑语音信号的前后信息,提高识别准确率。
- 自然语言处理(NLP):
- 命名实体识别(NER):通过前后文信息识别文本中的特定实体。
- 机器翻译:更好地理解和生成翻译结果。
- 情感分析:通过前后文信息更准确地判断文本情感。
- 时间序列预测:在金融市场预测、传感器数据分析等领域,通过双向信息处理提高预测准确性。
示例代码
以下是一个使用 PyTorch 构建 BLSTM 模型的示例代码:
import torch
import torch.nn as nnclass BLSTM(nn.Module):def __init__(self, input_size, hidden_size, num_layers, num_classes):super(BLSTM, self).__init__()self.hidden_size = hidden_sizeself.num_layers = num_layersself.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True)self.fc = nn.Linear(hidden_size * 2, num_classes) # 2 for bidirectiondef forward(self, x):# Set initial hidden and cell states h0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(x.device) # 2 for bidirection c0 = torch.zeros(self.num_layers * 2, x.size(0), self.hidden_size).to(x.device)# Forward propagate LSTMout, _ = self.lstm(x, (h0, c0)) # out: tensor of shape (batch_size, seq_length, hidden_size*2)# Decode the hidden state of the last time stepout = self.fc(out[:, -1, :])return out
总结
BLSTM 是一种增强版的 LSTM,通过同时从前后两个方向处理序列数据,能够更好地捕捉上下文信息,在许多序列处理任务中表现优异。它在语音识别、自然语言处理和时间序列预测等领域得到了广泛应用。
4. 级联错误 cascade errors
在中文语音合成系统(Text-to-Speech, TTS)的前端模块中,cascade errors(级联错误)指的是在处理流水线中,一个阶段的错误会传递并影响后续阶段的处理结果,从而导致最终输出的错误累积和放大。
级联错误的具体解释
在一个典型的 TTS 系统中,前端模块通常包含多个连续的文本处理组件,例如分词、词性标注、音节分割、韵律边界预测、音素映射等。这些组件按照特定的顺序逐个处理输入文本,每个组件的输出会作为下一个组件的输入。如果某一个组件出现错误,这个错误会传递给下一个组件,从而影响整个处理流水线的结果。以下是一些级联错误的具体例子:
-
分词错误:
- 如果分词组件将句子错误地切分成词语,这些错误的分词结果会直接影响后续的词性标注和音节分割。例如,“自然语言处理”被错误地分词为“自然 语言 处理”或“自然语 言处理”。
-
词性标注错误:
- 如果词性标注组件对某些词的词性标注错误,这些错误的词性信息会影响后续的韵律边界预测和音素映射。例如,将“处理”错误地标注为名词而不是动词,会导致错误的韵律结构预测。
-
音节分割错误:
- 如果音节分割组件错误地确定音节边界,这些错误会影响最终的音素映射和语音合成的准确性。例如,将“语言”错误地分割为“语 言”而不是“语音”。
-
韵律边界预测错误:
- 如果韵律边界预测组件错误地确定句子的韵律结构,这些错误会影响最终的语音合成的自然性和流畅性。例如,将一个停顿错误地插入到不合适的位置。
级联错误的影响
级联错误会导致以下问题:
- 误差积累:每个阶段的错误都会积累,使得最终的输出与真实的语音有显著偏差。
- 性能下降:系统的整体性能和准确性会因为这些错误而显著下降,影响用户体验。
- 难以调试:由于错误可能在多个组件之间传递和积累,定位和修正这些错误变得更加困难。
解决方法
为了减轻级联错误的影响,可以考虑以下方法:
- 端到端模型:使用端到端的深度学习模型,如基于序列到序列的TTS模型,可以避免传统流水线中每个独立组件的错误传递和累积。
- 错误反馈机制:在各个组件之间引入错误检测和反馈机制,可以及时修正错误,避免其传递。
- 模型集成:结合多种模型的预测结果,采用集成方法可以提高整体的鲁棒性和准确性,减少单一模型错误的影响。
总结
级联错误在 TTS 系统的前端模块中是一个常见问题,它会导致错误的逐步传递和累积,影响最终的语音合成质量。通过端到端模型、错误反馈机制和模型集成等方法,可以有效减轻级联错误的影响,提高系统的整体性能。
5. jieba WS POS
在你提到的上下文中,Jieba 中的 WS 指的是 Word Segmentation(分词)。分词是自然语言处理(NLP)中的一个基本操作,它将连续的文本字符串切分成独立的词语。这在处理中文文本时尤为重要,因为中文句子中的词语通常没有空格分隔。
Jieba 分词 (Word Segmentation, WS)
Jieba 是一个用于中文文本处理的开源分词工具,它提供了高效的分词功能。分词的目的是将句子切分成单词序列,使得后续的文本分析和处理更加容易。Jieba 支持三种分词模式:
- 精确模式:试图将句子最精确地切开,适合文本分析。
- 全模式:把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义。
- 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
示例代码
以下是使用 Jieba 进行分词的示例代码:
import jiebasentence = "我爱自然语言处理"
# 精确模式
words = jieba.cut(sentence, cut_all=False)
print("精确模式: " + "/".join(words))# 全模式
words = jieba.cut(sentence, cut_all=True)
print("全模式: " + "/".join(words))# 搜索引擎模式
words = jieba.cut_for_search(sentence)
print("搜索引擎模式: " + "/".join(words))
输出示例:
精确模式: 我/爱/自然/语言/处理
全模式: 我/爱/自然/语言/自然语言/处理
搜索引擎模式: 我/爱/自然/语言/处理/自然语言
Jieba 词性标注 (POS)
Jieba 也支持词性标注(Part-of-Speech Tagging, POS),这是将分词结果中的每个词标注上对应的词性(如名词、动词、形容词等)。这有助于更深入地理解句子的结构和语义。
示例代码
以下是使用 Jieba 进行分词和词性标注的示例代码:
import jieba.posseg as psegsentence = "我爱自然语言处理"
words = pseg.cut(sentence)for word, flag in words:print(f"{word}: {flag}")
输出示例:
我: r
爱: v
自然语言处理: n
在这个例子中,r 表示代词,v 表示动词,n 表示名词。
总结
在你提到的上下文中,Jieba 的 WS(Word Segmentation)指的是分词操作,将中文文本切分成独立的词语。POS(Part-of-Speech Tagging)则是对分词结果进行词性标注。这两个操作在中文自然语言处理任务中是基本且重要的步骤,能够帮助更好地理解和处理文本数据。
6. 公式原文解释 where Wx is the set of indices of the polyphonic words in the training sentence x, 1 is the indicator function, kω is the true label of character ω. 解释下Wx 1 kw这三个参数
在给定的上下文中,Wx、1 和 kω 是用于描述训练句子中多音字处理的一些参数。以下是对这些参数的解释:
-
Wx:
- 定义:
Wx是训练句子x中多音字的索引集合。 - 解释:在一个句子中,某些汉字是多音字(即在不同的上下文中可能有不同的发音)。
Wx表示所有这些多音字在句子x中的位置索引的集合。 - 示例:假设句子
x是“我喜欢打篮球和打排球”,如果“打”是多音字,那么Wx可能包含它在句子中的索引位置,例如[3, 8]。
- 定义:
-
1 (Indicator function, 指示函数):
- 定义:
1是指示函数,通常表示某个条件是否成立。 - 解释:指示函数
1(condition)在条件为真时取值为 1,在条件为假时取值为 0。 - 示例:如果我们有一个条件
1(i ∈ Wx),那么当i是多音字的索引时,指示函数的值为 1,否则为 0。
- 定义:
-
kω (True label, 真实标签):
- 定义:
kω是字符ω的真实标签。 - 解释:在多音字消歧任务中,
kω代表多音字ω的正确发音标签。多音字可以在不同上下文中有不同的读音,而kω指的是当前上下文中的正确读音。 - 示例:假设
ω是汉字“行”,它在“银行”和“行走”中的读音不同,那么kω就分别是“háng”和“xíng”。
- 定义:
总结
Wx是包含训练句子x中多音字位置索引的集合。1是一个指示函数,用于表示某个条件是否成立。kω是字符ω的真实发音标签,在当前上下文中的正确读音。
这些参数通常用于构建和训练用于多音字消歧的模型,通过标记和区分多音字的正确发音来提高模型的准确性。
7. 多音字消歧预测层损失函数公式解释
让我们详细解释一下这个公式 Lpoly 以及其中的各个部分:
公式解释
L p o l y = − 1 ∣ W x ∣ ∑ ω ∈ W x ∑ c 1 { c = k ω } × log y c L_{poly} = -\frac{1}{|W_x|} \sum_{\omega \in W_x} \sum_{c} 1\{c = k_{\omega}\} \times \log y_c Lpoly=−∣Wx∣1ω∈Wx∑c∑1{c=kω}×logyc
这是一个损失函数,用于计算多音字消歧任务中的损失。下面是对公式中每个部分的解释:
-
Lpoly:
- 定义:这是多音字消歧任务的损失函数。
- 解释:它衡量的是模型在处理多音字时的性能,具体来说,模型对每个多音字的发音预测与真实发音标签之间的差距。
-
-1/|Wx|:
- 定义:这是归一化系数,
|W_x|是训练句子x中多音字的数量。 - 解释:通过将总损失除以多音字的数量,我们得到了每个多音字的平均损失。这有助于防止损失函数因为多音字数量的不同而导致不平衡。
- 定义:这是归一化系数,
-
∑ω∈Wx:
- 定义:这是对句子
x中所有多音字的求和。 - 解释:我们要对训练句子
x中的每个多音字计算损失。
- 定义:这是对句子
-
∑c:
- 定义:这是对所有可能的发音标签
c的求和。 - 解释:我们需要考虑所有可能的发音标签,以便计算每个标签的预测概率。
- 定义:这是对所有可能的发音标签
-
1{c = kω}:
- 定义:这是指示函数,当
c等于真实标签kω时,它的值为 1,否则为 0。 - 解释:这用于选择正确的标签
kω,从而在损失计算中只考虑正确标签对应的预测概率。
- 定义:这是指示函数,当
-
log yc:
- 定义:这是模型预测标签
c的概率的对数值。 - 解释:对数概率
log yc用于计算交叉熵损失,它衡量的是预测概率分布与真实标签分布之间的差异。交叉熵损失越小,表示模型预测越准确。
- 定义:这是模型预测标签
损失函数工作原理
-
指示函数筛选:
- 指示函数
1{c = kω}确保我们只对正确的标签kω计算损失。
- 指示函数
-
交叉熵损失:
- 对正确标签
kω,取其预测概率的对数值log yc,并乘以指示函数的结果(1),这样只有正确标签的预测概率对损失有贡献。
- 对正确标签
-
平均化损失:
- 对所有多音字的损失求和后,除以多音字的数量
|W_x|,得到平均损失。
- 对所有多音字的损失求和后,除以多音字的数量
总结
这个损失函数的目标是最小化正确标签的对数概率的负值。通过最小化这个损失函数,我们可以训练模型使其更好地预测多音字的正确发音。
8. 交叉熵损失函数
交叉熵损失(Cross-Entropy Loss)是一种常用的损失函数,特别是在分类问题中。它衡量的是两个概率分布之间的差异。交叉熵损失的目标是最小化预测分布和真实分布之间的差异,从而提高模型的预测准确性。
交叉熵损失的定义
对于单个样本,交叉熵损失的公式为:
L = − ∑ i y i log ( y ^ i ) L = -\sum_{i} y_i \log(\hat{y}_i) L=−∑iyilog(y^i)
其中:
- y i y_i yi是真实标签的概率分布。
- y ^ i \hat{y}_i y^i 是模型预测的概率分布。
如果真实标签是一个独热编码(one-hot encoding),即只有一个类别为 1,其余类别为 0,那么交叉熵损失可以简化为:
L = − log ( y ^ c ) L = -\log(\hat{y}_c) L=−log(y^c)
其中 ( c ) 是真实标签对应的类别。
交叉熵损失的工作原理
-
预测分布:
- 模型输出的是对每个类别的预测概率,这些概率之和为 1。
-
真实分布:
- 真实标签通常用独热编码表示,只有真实类别的概率为 1,其余类别的概率为 0。
-
损失计算:
- 交叉熵损失计算的是真实标签与模型预测之间的差异。如果模型预测的概率越接近真实概率,损失就越小。
例子
假设我们有一个分类问题,有三个类别,真实标签为类别 2(独热编码为 [0, 1, 0]),模型预测的概率分布为 [0.2, 0.7, 0.1]。
计算交叉熵损失:
L = − ∑ i y i log ( y ^ i ) L = -\sum_{i} y_i \log(\hat{y}_i) L=−∑iyilog(y^i)
= − [ 0 log ( 0.2 ) + 1 log ( 0.7 ) + 0 log ( 0.1 ) ] = -[0 \log(0.2) + 1 \log(0.7) + 0 \log(0.1)] =−[0log(0.2)+1log(0.7)+0log(0.1)]
= − log ( 0.7 ) = -\log(0.7) =−log(0.7)
= 0.3567 = 0.3567 =0.3567
使用场景
交叉熵损失广泛应用于分类问题,如:
- 图像分类
- 自然语言处理中的文本分类
- 语音识别中的标签预测
优点
- 明确的概率解释:输出为概率分布,容易解释和分析。
- 优化稳定性:在梯度下降中表现良好,有助于加快收敛。
总结
交叉熵损失通过量化真实分布与预测分布之间的差异,指导模型参数更新,以提高模型的预测准确性。它是分类任务中最常用且效果良好的损失函数之一。
9. multi-head attention matrix是什么
原文For attention based distillation, the student tries to learn the multi-head attention matrix (AS) from that in the teacher network (AT).
在深度学习中,特别是在Transformer模型中,multi-head attention matrix 是多头注意力机制中每个注意力头的权重矩阵。多头注意力机制通过并行的多个注意力头来捕捉不同的注意力模式,从而使模型能够关注输入序列的不同部分。让我们详细探讨这个概念。
多头注意力机制
多头注意力机制(multi-head attention)通过多个注意力头(attention heads)来扩展传统的单头注意力机制。这些注意力头能够并行工作,并关注输入序列的不同方面,增强模型的表达能力。具体来说,多头注意力机制的工作流程如下:
- 输入嵌入分割:输入嵌入(输入特征向量)被分成多组,每组对应一个注意力头。
- 线性变换:每个注意力头有独立的线性变换矩阵,用于计算查询(Query)、键(Key)和值(Value)向量。
- 计算注意力:每个注意力头独立计算其注意力权重和输出。这些注意力权重是通过点积注意力(dot-product attention)计算得到的,通常经过softmax归一化。
- 合并输出:所有注意力头的输出被连接起来,然后通过另一个线性变换矩阵合并,形成最终的多头注意力输出。
Multi-Head Attention Matrix
在多头注意力机制中,attention matrix 是注意力权重矩阵,表示每个查询向量对所有键向量的注意力权重。在多头注意力中,每个头都有自己的注意力权重矩阵。这些矩阵共同构成了multi-head attention matrix。
假设有 h 个注意力头,每个头的注意力矩阵可以表示为 A_i,其中 i 是头的索引。multi-head attention matrix 可以表示为:
Multi-Head Attention = { A 1 , A 2 , … , A h } \text{Multi-Head Attention} = \{A_1, A_2, \ldots, A_h\} Multi-Head Attention={A1,A2,…,Ah}
具体例子
假设我们有一个输入序列 X,通过多头注意力机制计算注意力权重。对于每个注意力头,计算注意力权重的过程如下:
-
查询、键和值向量:
- Query: Q i = X W i Q Q_i = XW_i^Q Qi=XWiQ
- Key: K i = X W i K K_i = XW_i^K Ki=XWiK
- Value: V i = X W i V V_i = XW_i^V Vi=XWiV
-
计算注意力权重:
- Attention weights: A i = softmax ( Q i K i T d k ) A_i = \text{softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right) Ai=softmax(dkQiKiT)
-
计算头的输出:
- Head output: head i = A i V i \text{head}_i = A_i V_i headi=AiVi
最后,所有头的输出被连接起来并线性变换,得到多头注意力的最终输出。
总结
在注意力机制中,multi-head attention matrix 是指在多头注意力机制中,每个注意力头独立计算的注意力权重矩阵的集合。这些矩阵使模型能够从不同角度关注输入序列的不同部分,增强模型的表达能力和性能。
Multi-Head Attention = {A_1, A_2, ..., A_h}
其中每个 A i A_i Ai是一个注意力头的注意力权重矩阵。
在attention-based distillation中,学生网络试图从教师网络中学习这些multi-head attention matrices,以提高自身的性能。
10. 基于注意力头蒸馏的损失函数–注意力损失
在注意力机制蒸馏(attention-based distillation)过程中,学生模型(student model)试图从教师模型(teacher model)中学习多头注意力矩阵(multi-head attention matrices)。你给出的公式表示的是注意力损失(attention loss),其中学生模型和教师模型之间的多头注意力矩阵的均方误差(MSE)被用作损失函数。
公式解释
给定公式:
[ L_{\text{attn}} = \frac{1}{h} \sum_{i=1}^{h} \text{MSE}(A^S_i, A^T_i) ]
这个公式表示对每个注意力头计算学生模型和教师模型之间的注意力矩阵的均方误差,并对所有注意力头取平均。下面是详细解释:
- L attn L_{\text{attn}} Lattn:注意力损失(attention loss)。
- h h h:注意力头的数量。
- A i S A^S_i AiS:第 i i i 个注意力头在学生模型中的注意力矩阵。
- A i T A^T_i AiT:第 i i i个注意力头在教师模型中的注意力矩阵。
- MSE ( A i S , A i T ) \text{MSE}(A^S_i, A^T_i) MSE(AiS,AiT):学生模型和教师模型第 i i i 个注意力头的注意力矩阵之间的均方误差。
均方误差(MSE)
均方误差(Mean Squared Error, MSE)是一个常用的损失函数,用于测量预测值与真实值之间的差异。对于两个矩阵 ( A ) 和 ( B ),其 MSE 定义如下:
MSE ( A , B ) = 1 n ∑ j = 1 n ( A j − B j ) 2 \text{MSE}(A, B) = \frac{1}{n} \sum_{j=1}^{n} (A_j - B_j)^2 MSE(A,B)=n1∑j=1n(Aj−Bj)2
其中 n n n是矩阵中元素的数量, A j A_j Aj 和 B j B_j Bj 是矩阵 A A A 和 B B B 中的第 j j j个元素。
示例解释
假设我们有一个教师模型和一个学生模型,它们都有 h = 4 h = 4 h=4个注意力头。我们计算每个注意力头的注意力矩阵之间的 MSE,然后取平均值,得到注意力损失。
- 对于每个注意力头 i i i,计算学生模型和教师模型的注意力矩阵 A i S A^S_i AiS 和 A i T A^T_i AiT 之间的 MSE。
- 对所有注意力头的 MSE 取平均,作为总的注意力损失 L attn L_{\text{attn}} Lattn。
总结
这个公式表示在注意力机制蒸馏过程中,学生模型通过最小化其注意力矩阵与教师模型对应注意力矩阵之间的均方误差来学习多头注意力机制。这样做可以帮助学生模型更好地模仿教师模型的行为,从而提高性能。
L_{\text{attn}} = \frac{1}{h} \sum_{i=1}^{h} \text{MSE}(A^S_i, A^T_i)
该公式中的均方误差(MSE)测量了学生模型和教师模型在每个注意力头上的注意力矩阵的差异,并将这些误差平均作为最终的注意力损失。
11. 理解基于隐藏状态的蒸馏
好的,我们重新理解一下这个公式及其内容:
正确的公式
L embed = MSE ( H S W h , H T ) L_{\text{embed}} = \text{MSE}(H^S W_h, H^T) Lembed=MSE(HSWh,HT)
解释内容
这段话描述了基于隐藏状态的蒸馏方法及其训练损失定义:
-
Hidden states based distillation:
- 隐藏状态基于蒸馏是一种将Transformer层输出中的知识进行蒸馏的方法。
-
In each Transformer layer:
- 在每个Transformer层中,学生模型尝试学习一个简化的输出状态矩阵 H S H^S HS,该矩阵来自于教师模型的对应输出 H T H^T HT。
-
Reduced output state matrix ( H^S ):
- 学生模型的输出状态矩阵 H S H^S HS 是教师模型输出状态矩阵$ H^T$ 的简化版本。
-
Training loss definition L embed = MSE ( H S W h , H T ) L_{\text{embed}} = \text{MSE}(H^S W_h, H^T) Lembed=MSE(HSWh,HT):
- 训练损失 L embed L_{\text{embed}} Lembed 被定义为学生模型简化输出状态矩阵 ( H^S ) 经过一个权重矩阵 W h W_h Wh 线性变换后的结果与教师模型输出状态矩阵 H T H^T HT 之间的均方误差 M S E MSE MSE。
公式解释
L embed = MSE ( H S W h , H T ) L_{\text{embed}} = \text{MSE}(H^S W_h, H^T) Lembed=MSE(HSWh,HT)
这个公式表示的是通过均方误差(MSE)来衡量学生模型与教师模型之间的差异,具体步骤如下:
-
学生模型输出状态矩阵 ( H^S ):
- 学生模型生成的输出状态矩阵 H S H^S HS。
-
线性变换 W h W_h Wh:
- 使用权重矩阵 W h W_h Wh 将学生模型的简化输出 H S H^S HS 转换到与教师模型输出 H T H^T HT相同的维度。这一步的目的是确保学生模型的输出与教师模型的输出具有相同的形状和尺度。
-
教师模型输出状态矩阵 H T H^T HT:
- 教师模型的输出状态矩阵 H T H^T HT。
-
均方误差 MSE ( H S W h , H T ) \text{MSE}(H^S W_h, H^T) MSE(HSWh,HT):
- 计算经过线性变换后的学生模型输出 H S W h H^S W_h HSWh 与教师模型输出 H T H^T HT之间的均方误差。这种方式确保学生模型能够学习并接近教师模型的输出。
均方误差(MSE)
均方误差(Mean Squared Error, MSE)是一个常用的损失函数,用于测量预测值与真实值之间的差异。对于两个矩阵 ( A ) 和 ( B ),其 MSE 定义如下:
MSE ( A , B ) = 1 n ∑ i = 1 n ( A i − B i ) 2 \text{MSE}(A, B) = \frac{1}{n} \sum_{i=1}^{n} (A_i - B_i)^2 MSE(A,B)=n1∑i=1n(Ai−Bi)2
其中 n n n是矩阵中元素的数量, A i A_i Ai和 $B_i$ 是矩阵 A A A 和 B B B 中的第 i i i 个元素。
理解过程
-
学生模型简化输出 H S H^S HS:
- 学生模型生成一个简化的输出状态矩阵 H S H^S HS,其维度可能小于教师模型输出状态矩阵 H T H^T HT。
-
线性变换 W h W_h Wh:
- 使用权重矩阵 W h W_h Wh 将学生模型的简化输出 H S H^S HS转换到与教师模型输出 H T H^T HT 相同的维度。
-
计算误差:
- 计算经过线性变换后的学生模型输出 H S W h H^S W_h HSWh与教师模型输出 H T H^T HT 之间的均方误差。这种方式确保学生模型能够学习并接近教师模型的输出。
-
最小化损失:
- 通过最小化均方误差 MSE ( H S W h , H T ) \text{MSE}(H^S W_h, H^T) MSE(HSWh,HT),学生模型逐渐学习教师模型的行为,达到知识迁移的目的。
总结
基于隐藏状态的蒸馏方法旨在通过最小化学生模型和教师模型在每个Transformer层输出上的差异,将知识从教师模型迁移到学生模型。训练损失 L embed L_{\text{embed}} Lembed 的定义体现了这种知识迁移过程,其中学生模型的输出状态矩阵经过线性变换后与教师模型的输出状态矩阵进行对比,使用均方误差作为度量标准。
L_{\text{embed}} = \text{MSE}(H^S W_h, H^T)
这种方法使学生模型能够逐渐逼近教师模型的表现,从而在保证性能的同时,减少模型的复杂度和参数量。
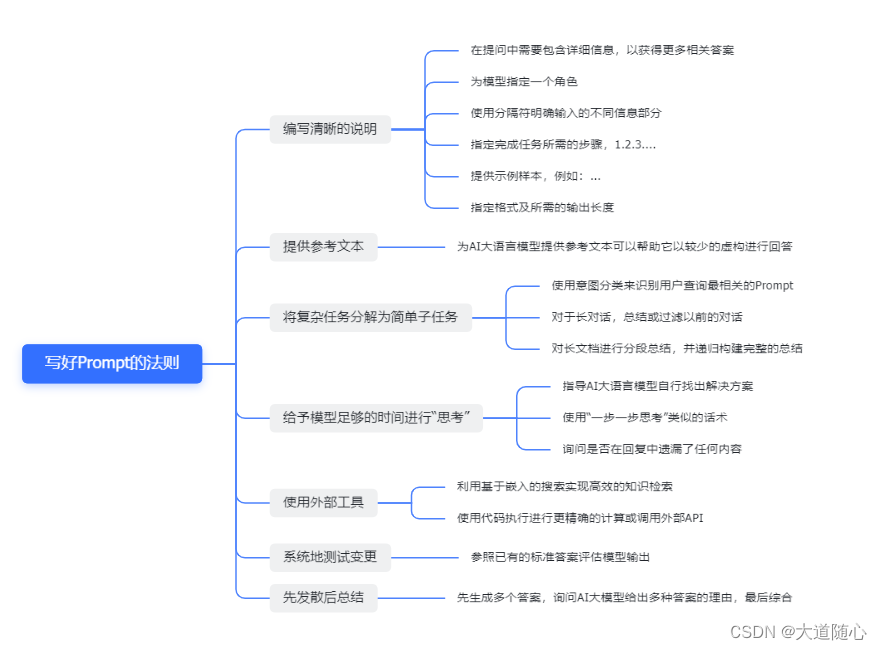
小绿鲸思维导图技巧
基本技巧
大纲笔记和思维导图的主题是一一对应的
中心主题与笔记的标题一致,修改后笔记标题会同步变化
双击主题或按【空格键】修改内容,单击空白处退出修改
点击【Enter】创建同级主题
点击【Tab】创建子主题
点击【Enter+Shift】可在主题内换行
鼠标移入主题,后方会出现“+/-”,点击可展开/收起子主题
单击按住主题,可拖动主题至任意位置
选中主题出现功能栏,可进行如下操作:添加子主题、修改样式、添加描述、添加总结、添加外框、添加连线、添加图片
进阶技巧
如何添加图片:选中主题,出现功能栏,点击"添加"图片"按钮
如何编辑描述:选中主题,出现功能栏,点击"添加描述"按钮,编辑完成点击【√】
如何添加编号和完成百分比:选中主题,出现功能栏,点击"修改样式"按钮,滑到下方"优先级"和"百分比"处添加
如何添加总结/外框:选中主题,出现功能栏,点击"添加总结/外框"按钮,再次点击添加上的“总结/外框”,上下移动蓝色选框,可将多个同级主题涵盖在里面
如何添加连线:选中主题,出现功能栏,点击"添加连线"按钮,鼠标将连线箭头指向目标主题。点击连线,两端会出现小圆点,鼠标拖动小圆点可改变连线的弯曲弧度


![[图解]建模相关的基础知识-12](https://img-blog.csdnimg.cn/direct/58c970fd961f4a1ea528b85fc52fd422.png)