 告别海外账号与网络限制稳定直连全球优质大模型限时半价接入中。 点击领取海量免费额度观察 Taotoken 在多模型间路由的响应表现与容灾切换体感在构建依赖大模型的应用时服务的稳定性是核心考量之一。单一模型供应商的接口波动或临时性延迟都可能直接影响终端用户的体验。Taotoken 作为大模型聚合分发平台其设计目标之一便是通过多模型路由与容灾机制来提升整体服务的可用性。本文将以一次模拟的主模型延迟升高场景为例描述在 Taotoken 平台上观察到的路由切换表现与相关体感帮助开发者理解其稳定性设计。1. 理解 Taotoken 的路由与容灾基础Taotoken 平台允许用户通过一个统一的 OpenAI 兼容 API 端点接入多家模型供应商。其路由逻辑可以根据预设的策略将请求智能地分发到不同的模型后端。当某个模型或供应商出现响应缓慢、高错误率或不可用时平台的路由系统可以依据配置将后续请求导向其他健康的备用模型。这种机制的核心价值在于它为开发者提供了一个抽象层使得应用无需在代码中硬编码复杂的重试和切换逻辑而是由平台层面来保障请求的最终成功。关于路由策略的具体配置选项如基于延迟、成本或手动指定的优先级用户可以在 Taotoken 控制台的相关模块进行查看和设置。2. 模拟场景主模型延迟升高为了直观感受路由切换的过程我们设计了一个简单的模拟测试。假设我们在 Taotoken 控制台中为某个应用配置了路由策略优先使用模型 A当其平均响应延迟超过 5 秒或错误率升高时自动将流量切换至备用模型 B。我们使用一个脚本以固定频率向 Taotoken 的统一端点https://taotoken.net/api/v1/chat/completions发送请求。初始阶段所有请求均被路由至模型 A响应延迟稳定在 1-2 秒左右。随后我们通过外部手段此部分为模拟非平台操作人为地引入了模型 A 后端网络的延迟使其响应时间逐渐增加至 8-10 秒。此时我们持续观察发送到 Taotoken 端点的请求响应情况。3. 切换过程中的观察与体感在模型 A 延迟升高的初期约持续 1-2 个请求周期通过 Taotoken 发出的请求依然会路由至模型 A因此体验到的延迟同步升高。这个过程可以理解为平台的监控系统正在收集和评估模型 A 的健康指标。很快在接下来的请求中我们观察到响应时间出现了显著变化。大部分请求的延迟回落到了 2-3 秒的水平与之前使用模型 B 的基准测试结果相符。通过检查返回的响应体中的model字段可以确认请求已被路由至模型 B。这标志着自动切换已经生效。在整个切换窗口期大约持续了 3-5 个请求没有观察到因切换导致的请求完全失败例如返回 HTTP 5xx 错误。所有请求最终都成功返回了内容。这意味着切换过程对于客户端而言是相对平滑的没有造成服务中断。从开发者的体感来看最直接的感受是在模型 A 发生问题时应用没有“卡死”在超时等待上而是短暂经历波动后恢复了正常响应速度。这避免了自己去实现和运维一套复杂的故障检测与切换系统。4. 手动干预与策略配置的灵活性除了自动切换Taotoken 也提供了手动干预的灵活性。例如在控制台的“模型广场”或相关路由配置页面用户可以临时调整某个模型的权重将其设置为“禁用”或直接指定当前请求使用的供应商。在本次模拟中当自动切换发生后我们尝试在控制台手动将模型 A 的权重调至最低。随后发送的请求几乎立即全部流向模型 B响应延迟保持稳定。这体现了平台在提供自动保障的同时也给予了运维人员根据实际情况进行快速调控的能力。需要强调的是具体的路由算法、切换阈值和生效时间可能因平台策略优化而调整。因此在实际业务中建议开发者以 Taotoken 官方文档和控制台实时信息为准并结合自身业务的 SLA 要求进行测试和配置。5. 总结稳定性设计的可感知价值通过这次简单的模拟观察我们可以体会到 Taotoken 在多模型路由与容灾方面的设计所带来的价值。它将模型供应商的不可控因素部分转化为了平台层可控的稳定性风险缓解措施。对于开发者而言这意味着降低运维复杂度无需为每一个模型接口单独编写熔断、降级和切换逻辑。提升最终用户体验当单一模型出现问题时服务仍能通过备用通道继续提供避免了长时间的不可用状态。增强成本与效果的平衡能力可以结合路由策略在性能、成本和效果之间进行更灵活的权衡与配置。最终这些能力的有效发挥依赖于对平台路由规则的合理配置以及对各模型特性的了解。建议开发者在 Taotoken 控制台中仔细查阅相关功能说明并根据自身业务场景进行充分的测试与验证。开始体验 Taotoken 的多模型路由与稳定性功能请访问 Taotoken。 告别海外账号与网络限制稳定直连全球优质大模型限时半价接入中。 点击领取海量免费额度
告别海外账号与网络限制稳定直连全球优质大模型限时半价接入中。 点击领取海量免费额度观察 Taotoken 在多模型间路由的响应表现与容灾切换体感在构建依赖大模型的应用时服务的稳定性是核心考量之一。单一模型供应商的接口波动或临时性延迟都可能直接影响终端用户的体验。Taotoken 作为大模型聚合分发平台其设计目标之一便是通过多模型路由与容灾机制来提升整体服务的可用性。本文将以一次模拟的主模型延迟升高场景为例描述在 Taotoken 平台上观察到的路由切换表现与相关体感帮助开发者理解其稳定性设计。1. 理解 Taotoken 的路由与容灾基础Taotoken 平台允许用户通过一个统一的 OpenAI 兼容 API 端点接入多家模型供应商。其路由逻辑可以根据预设的策略将请求智能地分发到不同的模型后端。当某个模型或供应商出现响应缓慢、高错误率或不可用时平台的路由系统可以依据配置将后续请求导向其他健康的备用模型。这种机制的核心价值在于它为开发者提供了一个抽象层使得应用无需在代码中硬编码复杂的重试和切换逻辑而是由平台层面来保障请求的最终成功。关于路由策略的具体配置选项如基于延迟、成本或手动指定的优先级用户可以在 Taotoken 控制台的相关模块进行查看和设置。2. 模拟场景主模型延迟升高为了直观感受路由切换的过程我们设计了一个简单的模拟测试。假设我们在 Taotoken 控制台中为某个应用配置了路由策略优先使用模型 A当其平均响应延迟超过 5 秒或错误率升高时自动将流量切换至备用模型 B。我们使用一个脚本以固定频率向 Taotoken 的统一端点https://taotoken.net/api/v1/chat/completions发送请求。初始阶段所有请求均被路由至模型 A响应延迟稳定在 1-2 秒左右。随后我们通过外部手段此部分为模拟非平台操作人为地引入了模型 A 后端网络的延迟使其响应时间逐渐增加至 8-10 秒。此时我们持续观察发送到 Taotoken 端点的请求响应情况。3. 切换过程中的观察与体感在模型 A 延迟升高的初期约持续 1-2 个请求周期通过 Taotoken 发出的请求依然会路由至模型 A因此体验到的延迟同步升高。这个过程可以理解为平台的监控系统正在收集和评估模型 A 的健康指标。很快在接下来的请求中我们观察到响应时间出现了显著变化。大部分请求的延迟回落到了 2-3 秒的水平与之前使用模型 B 的基准测试结果相符。通过检查返回的响应体中的model字段可以确认请求已被路由至模型 B。这标志着自动切换已经生效。在整个切换窗口期大约持续了 3-5 个请求没有观察到因切换导致的请求完全失败例如返回 HTTP 5xx 错误。所有请求最终都成功返回了内容。这意味着切换过程对于客户端而言是相对平滑的没有造成服务中断。从开发者的体感来看最直接的感受是在模型 A 发生问题时应用没有“卡死”在超时等待上而是短暂经历波动后恢复了正常响应速度。这避免了自己去实现和运维一套复杂的故障检测与切换系统。4. 手动干预与策略配置的灵活性除了自动切换Taotoken 也提供了手动干预的灵活性。例如在控制台的“模型广场”或相关路由配置页面用户可以临时调整某个模型的权重将其设置为“禁用”或直接指定当前请求使用的供应商。在本次模拟中当自动切换发生后我们尝试在控制台手动将模型 A 的权重调至最低。随后发送的请求几乎立即全部流向模型 B响应延迟保持稳定。这体现了平台在提供自动保障的同时也给予了运维人员根据实际情况进行快速调控的能力。需要强调的是具体的路由算法、切换阈值和生效时间可能因平台策略优化而调整。因此在实际业务中建议开发者以 Taotoken 官方文档和控制台实时信息为准并结合自身业务的 SLA 要求进行测试和配置。5. 总结稳定性设计的可感知价值通过这次简单的模拟观察我们可以体会到 Taotoken 在多模型路由与容灾方面的设计所带来的价值。它将模型供应商的不可控因素部分转化为了平台层可控的稳定性风险缓解措施。对于开发者而言这意味着降低运维复杂度无需为每一个模型接口单独编写熔断、降级和切换逻辑。提升最终用户体验当单一模型出现问题时服务仍能通过备用通道继续提供避免了长时间的不可用状态。增强成本与效果的平衡能力可以结合路由策略在性能、成本和效果之间进行更灵活的权衡与配置。最终这些能力的有效发挥依赖于对平台路由规则的合理配置以及对各模型特性的了解。建议开发者在 Taotoken 控制台中仔细查阅相关功能说明并根据自身业务场景进行充分的测试与验证。开始体验 Taotoken 的多模型路由与稳定性功能请访问 Taotoken。 告别海外账号与网络限制稳定直连全球优质大模型限时半价接入中。 点击领取海量免费额度
观察 Taotoken 在多模型间路由的响应表现与容灾切换体感
发布时间:2026/5/18 22:18:39
告别海外账号与网络限制稳定直连全球优质大模型限时半价接入中。 点击领取海量免费额度观察 Taotoken 在多模型间路由的响应表现与容灾切换体感在构建依赖大模型的应用时服务的稳定性是核心考量之一。单一模型供应商的接口波动或临时性延迟都可能直接影响终端用户的体验。Taotoken 作为大模型聚合分发平台其设计目标之一便是通过多模型路由与容灾机制来提升整体服务的可用性。本文将以一次模拟的主模型延迟升高场景为例描述在 Taotoken 平台上观察到的路由切换表现与相关体感帮助开发者理解其稳定性设计。1. 理解 Taotoken 的路由与容灾基础Taotoken 平台允许用户通过一个统一的 OpenAI 兼容 API 端点接入多家模型供应商。其路由逻辑可以根据预设的策略将请求智能地分发到不同的模型后端。当某个模型或供应商出现响应缓慢、高错误率或不可用时平台的路由系统可以依据配置将后续请求导向其他健康的备用模型。这种机制的核心价值在于它为开发者提供了一个抽象层使得应用无需在代码中硬编码复杂的重试和切换逻辑而是由平台层面来保障请求的最终成功。关于路由策略的具体配置选项如基于延迟、成本或手动指定的优先级用户可以在 Taotoken 控制台的相关模块进行查看和设置。2. 模拟场景主模型延迟升高为了直观感受路由切换的过程我们设计了一个简单的模拟测试。假设我们在 Taotoken 控制台中为某个应用配置了路由策略优先使用模型 A当其平均响应延迟超过 5 秒或错误率升高时自动将流量切换至备用模型 B。我们使用一个脚本以固定频率向 Taotoken 的统一端点https://taotoken.net/api/v1/chat/completions发送请求。初始阶段所有请求均被路由至模型 A响应延迟稳定在 1-2 秒左右。随后我们通过外部手段此部分为模拟非平台操作人为地引入了模型 A 后端网络的延迟使其响应时间逐渐增加至 8-10 秒。此时我们持续观察发送到 Taotoken 端点的请求响应情况。3. 切换过程中的观察与体感在模型 A 延迟升高的初期约持续 1-2 个请求周期通过 Taotoken 发出的请求依然会路由至模型 A因此体验到的延迟同步升高。这个过程可以理解为平台的监控系统正在收集和评估模型 A 的健康指标。很快在接下来的请求中我们观察到响应时间出现了显著变化。大部分请求的延迟回落到了 2-3 秒的水平与之前使用模型 B 的基准测试结果相符。通过检查返回的响应体中的model字段可以确认请求已被路由至模型 B。这标志着自动切换已经生效。在整个切换窗口期大约持续了 3-5 个请求没有观察到因切换导致的请求完全失败例如返回 HTTP 5xx 错误。所有请求最终都成功返回了内容。这意味着切换过程对于客户端而言是相对平滑的没有造成服务中断。从开发者的体感来看最直接的感受是在模型 A 发生问题时应用没有“卡死”在超时等待上而是短暂经历波动后恢复了正常响应速度。这避免了自己去实现和运维一套复杂的故障检测与切换系统。4. 手动干预与策略配置的灵活性除了自动切换Taotoken 也提供了手动干预的灵活性。例如在控制台的“模型广场”或相关路由配置页面用户可以临时调整某个模型的权重将其设置为“禁用”或直接指定当前请求使用的供应商。在本次模拟中当自动切换发生后我们尝试在控制台手动将模型 A 的权重调至最低。随后发送的请求几乎立即全部流向模型 B响应延迟保持稳定。这体现了平台在提供自动保障的同时也给予了运维人员根据实际情况进行快速调控的能力。需要强调的是具体的路由算法、切换阈值和生效时间可能因平台策略优化而调整。因此在实际业务中建议开发者以 Taotoken 官方文档和控制台实时信息为准并结合自身业务的 SLA 要求进行测试和配置。5. 总结稳定性设计的可感知价值通过这次简单的模拟观察我们可以体会到 Taotoken 在多模型路由与容灾方面的设计所带来的价值。它将模型供应商的不可控因素部分转化为了平台层可控的稳定性风险缓解措施。对于开发者而言这意味着降低运维复杂度无需为每一个模型接口单独编写熔断、降级和切换逻辑。提升最终用户体验当单一模型出现问题时服务仍能通过备用通道继续提供避免了长时间的不可用状态。增强成本与效果的平衡能力可以结合路由策略在性能、成本和效果之间进行更灵活的权衡与配置。最终这些能力的有效发挥依赖于对平台路由规则的合理配置以及对各模型特性的了解。建议开发者在 Taotoken 控制台中仔细查阅相关功能说明并根据自身业务场景进行充分的测试与验证。开始体验 Taotoken 的多模型路由与稳定性功能请访问 Taotoken。 告别海外账号与网络限制稳定直连全球优质大模型限时半价接入中。 点击领取海量免费额度
相关文章

GitHub加速终极指南:如何让代码下载速度提升10倍以上
GitHub加速终极指南:如何让代码下载速度提升10倍以上 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾经在深夜…
黑马SpringBoot3+Vue3(实战篇)学习记录 一:新建数据库、新建项目
实战篇01 02 注:视频开头的建立数据库可以直接通过MySQL workbench建立,无需考虑基础篇的内容 1.建立数据库: 最好使用MySQL workbench执行 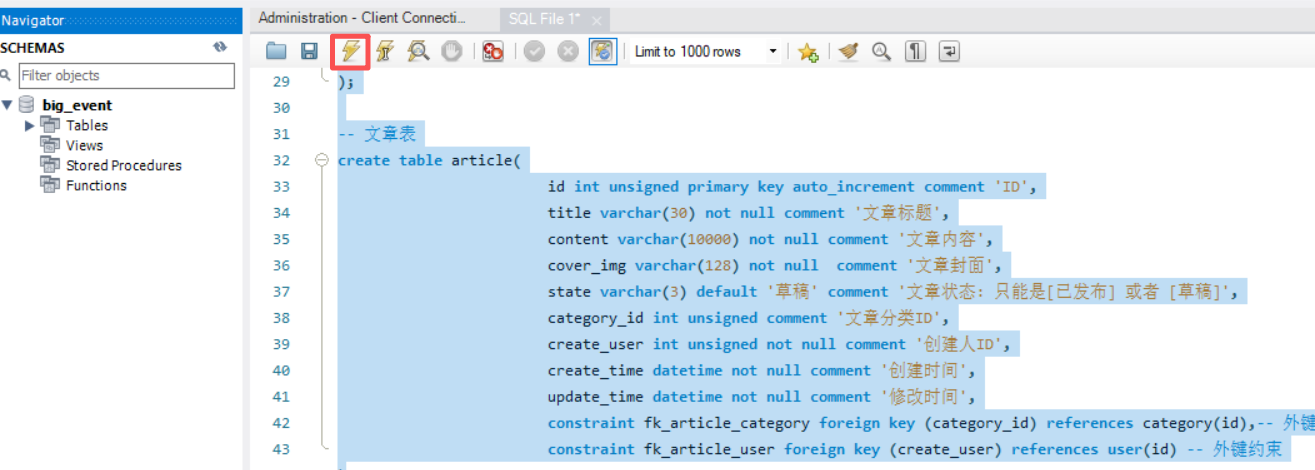 …
Windows右键菜单终极清理指南:三步高效管理冗余选项
Windows右键菜单终极清理指南:三步高效管理冗余选项 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager Windows右键菜单随着软件安装日益臃肿࿰…

Linux Exploit Suggester与常见漏洞检测工具对比分析:终极指南
Linux Exploit Suggester与常见漏洞检测工具对比分析:终极指南 【免费下载链接】Linux_Exploit_Suggester Linux Exploit Suggester; based on operating system release number 项目地址: https://gitcode.com/gh_mirrors/li/Linux_Exploit_Suggester Linu…
CL API实时闭环神经控制技术解析与应用
1. CL API实时闭环神经控制技术概述在生物神经网络(BNN)研究领域,实时闭环控制技术正成为连接计算系统与生物神经元的桥梁。CL API作为这一领域的前沿工具,其设计哲学源于对神经电生理实验的深刻理解——当我们需要在毫秒级时间尺…
企业内网系统通过Taotoken安全调用外部大模型API的方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内网系统通过Taotoken安全调用外部大模型API的方案 对于有严格数据安全与合规要求的企业IT部门而言,如何安全、可控…
片上变压器增益增强原理与射频IC设计实战
1. 项目概述:为什么要在芯片里“塞”个变压器?提起变压器,大家脑海里浮现的肯定是那种方方正正、绕满铜线、用在电网里升降电压的“大家伙”。但在射频和毫米波集成电路的世界里,情况完全不同。这里的“片上变压器”是一个微缩到硅…
XC7Z100-2FFG900:AMD Xilinx Zynq-7000 SoC旗舰,双核ARM+Kintex-7 FPGA,FCBGA-900封装
XC7Z100-2FFG900:Zynq-7000旗舰FPGA的高性能异构计算平台在高端工业自动化、软件无线电、4K视频处理以及复杂边缘计算等领域,传统的单处理器架构或独立FPGA方案往往难以兼顾“通用计算的灵活性”与“硬件加速的实时性”。设计者需要在海量数据的吞吐速率…
AI教材生成新体验:低查重AI写教材,一键搞定教材编写难题!
AI 教材写作工具测评与推荐 在写教材的过程中,总是能准确地踩到“慢节奏”的各种坑。尽管框架和材料已准备就绪,却往往在撰写具体内容时陷入困境——一句话反复修改半小时,仍觉得表述不够准确;章节间的衔接总是想破脑袋也找不到合…

精益管理推不动?找准根源+避坑指南,破解全员参与难题
很多工厂推行精益管理,都陷入了管理层热、员工冷的尴尬困境:管理层耗费大量精力制定精益方案、投入资源,却始终推不动,一线员工要么被动应付,要么抵触反抗,不主动识别浪费、不参与改善,精益落地…
基于React与Zustand构建现代化个人站点导航器:从设计到部署全解析
1. 项目概述:一个现代站点导航器的诞生最近在整理自己的浏览器书签和常用工具时,我发现自己陷入了一个典型的“数字混乱”状态。收藏夹里塞满了各种链接,从开发文档、设计资源到日常工具,杂乱无章。每次想找一个特定的网站&#x…
开发团队如何通过 Taotoken 实现 API 密钥的统一管理与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发团队如何通过 Taotoken 实现 API 密钥的统一管理与审计 对于开发团队而言,安全、高效地管理大模型 API 密钥是一项…

【实用小程序】超轻量级文件上传下载中心 (File Download Server)
站内源码及jar包下载 一、项目概述 文件下载中心一个基于 Java 内置 HTTP 服务器(com.sun.net.httpserver)构建的轻量级文件管理服务。它零第三方依赖,单 JAR 包即可运行,适合在内网环境或临时场景中快速搭建文件共享站点。 你的团队需要临时共享一批日志文件或交付物,…
py每日spider案例之某website之xin东方选课搜索接口(难度一般 扣取代码即可)
加密位置: 逆向接口参数: 逆向接口: const g = globalThis; g.window = g; g.self = g; g.location = {<
终极轻量级Android文本编辑器Markor:多格式笔记应用完全指南
终极轻量级Android文本编辑器Markor:多格式笔记应用完全指南 【免费下载链接】markor Text editor - Notes & ToDo (for Android) - Markdown, todo.txt, plaintext, math, .. 项目地址: https://gitcode.com/gh_mirrors/ma/markor 在移动设备上寻找一款…

MPC-BE:基于DirectShow架构的专业级开源媒体播放解决方案
MPC-BE:基于DirectShow架构的专业级开源媒体播放解决方案 【免费下载链接】MPC-BE MPC-BE – универсальный проигрыватель аудио и видеофайлов для операционной системы Windows. 项目地址:…
如何快速计算3D模型体积和重量:STL-Volume-Model-Calculator终极指南
如何快速计算3D模型体积和重量:STL-Volume-Model-Calculator终极指南 【免费下载链接】STL-Volume-Model-Calculator STL Volume Model Calculator Python 项目地址: https://gitcode.com/gh_mirrors/st/STL-Volume-Model-Calculator 你是否曾经为3D打印项目…
通过Taotoken CLI工具一键配置团队开发环境与模型密钥
通过Taotoken CLI工具一键配置团队开发环境与模型密钥 1. CLI工具安装与基本使用 Taotoken提供的CLI工具可通过npm全局安装或直接使用npx运行。对于需要频繁使用CLI的团队,推荐全局安装: npm install -g taotoken/taotoken对于临时使用或项目级配置&a…